
mtvcrafter 是由中国科学院深圳先进技术研究院计算机视觉与模式识别实验室、中国电信人工智能研究所等多个研究机构共同开发的一款创新的人体图像动画框架,专注于从原始3d运动序列生成高质量动画。该框架通过引入4d运动标记化(4dmot)技术,直接对3d运动数据进行建模,从而绕过了传统方法中依赖2d渲染姿态图像的限制。此外,mtvcrafter 还采用了运动感知视频扩散transformer(mv-dit),利用独特的4d运动注意力机制和位置编码,以4d运动标记作为动画生成的上下文信息。在 tiktok 基准测试中,mtvcrafter 的 fid-vid 得分为6.98,较第二名提升了65%,显示了其卓越的泛化性能和稳定性。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
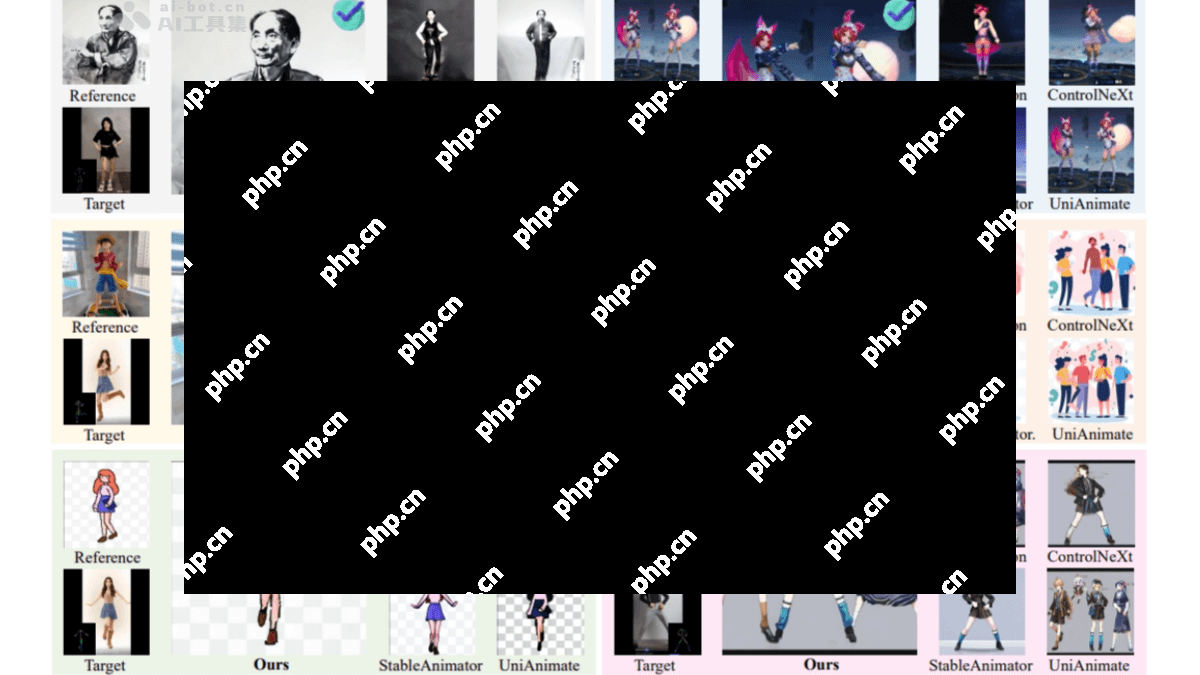
以上就是MTVCrafter— 中科院联合中国电信等机构推出的人像动画生成框架的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 422
422






















