
推理模型常表现出类似自我反思的行为,但它们是否真的能有效探索新策略?
对此,西北大学与 Google、谷歌 DeepMind 团队对传统强化学习与反思的关系提出质疑,并提出了贝叶斯自适应的强化学习方法,首次解释了为何、如何以及何时应进行反思和探索。

通过对比采用传统强化学习和新方法训练的模型,研究人员发现:
在完成“模型需在3步内输出三个连续相同字符”的合成任务中,传统RL往往一条道走到黑,而新方法懂得排除无效假设并适时切换策略。
此外,在数学推理任务中,新方法在大多数基准和模型上均获得了更高的准确率,且解题所耗token数更少。
更有趣的是,团队发现反思次数并非决定性能的唯一因素,部分基础模型虽有大量徒劳的反思,但并未带来实质性信息增益。
以下详细展开。
贝叶斯自适应强化学习激发反思性探索
直观来看,测试时的试错步骤仅在能带来信息增益时才有益,然而现有强化学习并未告知模型试错和反思带来的信息增益。
实际上,基于马尔可夫假设的传统强化学习范式存在局限——探索仅发生于训练阶段,代理在部署时通常只利用训练中学到的确定性策略。
马尔可夫假设使RL代理仅依据当前状态做决策,历史信息(如试错并回溯的思考过程)对策略的影响都被压缩至当前状态表示中。
研究者指出,这种传统范式可能导致模型通过记忆训练解答获得高分,而无需真正学会反思;模型内部思考的试错也无法提供信息增益。
那么,测试时的反思性探索真的有用吗?如何才能学到有效的反思性探索策略呢?

为了解决上述问题,研究者研究了与传统RL不同的贝叶斯自适应RL框架,简称BARL。
其核心思想是将LLM的反思性探索转化为贝叶斯自适应强化学习问题处理,通过引入对环境不确定性的建模,让模型在推理过程中自适应地进行探索。
简而言之,BARL不再局限于传统RL的马尔可夫假设,而是考虑了MDP的不确定性(如不同策略对一道题的有效性),因此需要将所有历史观察(包括奖励反馈)纳入决策中。
这种框架天然平衡了奖励最大化的利用和信息获取的探索。
具体而言,在BARL中,团队假设模型面对的是一个存在未知要素的任务,可以用一组假设的MDP(马尔可夫决策过程)来描述这些不确定性。
模型对每个假设MDP保持一个后验概率(belief),随着推理过程不断更新。
每当模型选择一个动作(如生成下一个思维步骤),都会根据观察到的结果更新对各个假设的信念。
BARL的目标策略并非针对单一确定环境优化,而是直接优化在后验分布下的期望累积回报。这意味着模型在决策时会考虑“这样做收益是多少,同时这样的行动能多大程度减少不确定性?”。
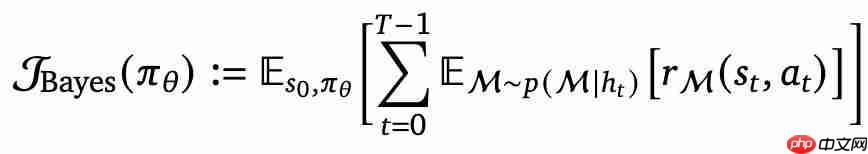
BARL明确将测试时的表现纳入优化目标,通过最大化后验下的期望回报鼓励模型考虑未知情况。
模型明白只有主动探索才能在未知情境下保持高收益,因此反思是为了获取关键信息,避免一条路走错到底。
简而言之,BARL让模型意识到——
适时反思、多一种尝试可能带来更高的回报,这正是反思行为得以涌现的动机。
全新推理模型强化学习算法
研究者针对推理模型给出了BARL决策的数学形式,其中核心是如何计算后验的期望值:
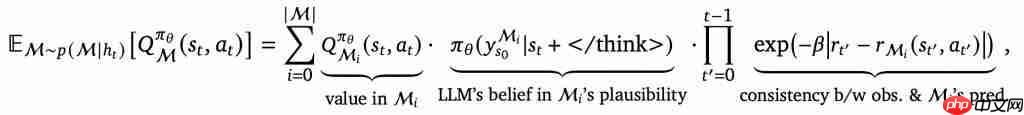
该公式针对多个候选答案(如best-of-N中的N个答案)计算了预期回报加权求和,权重一方面是模型认为该候选答案的好坏,另一方面还包含了一个“校正项”——用来衡量实际观察结果与模型预期的偏差。
正是这个校正项充当了反思信号:如果某个策略原本被模型高度看好,但奖励反馈结果不尽如人意,那这个差异会迅速降低该假设的权重,提醒模型“也许该换一种思路了”,这正回答了模型应该何时进行反思和探索。
通过这种机制,BARL的决策公式指导模型在每个步骤判断是否需要反思、何时切换策略。
这也是BARL反思性决策的精髓——让模型基于贝叶斯后验来权衡“继续当前思路”还是“尝试新思路”。
这种更新过程鼓励模型拼接和切换不同的推理策略,就像把多条可能的解题思路串联起来,并在中途发现某条思路行不通时迅速切换到另一条。
BARL通过端到端的RL优化自动实现了这一点,可谓以原则化的方式赋予了LLM在推理过程中的“何时反思、如何反思”的指南,达到了以一条长CoT线性化best-of-N的效果。
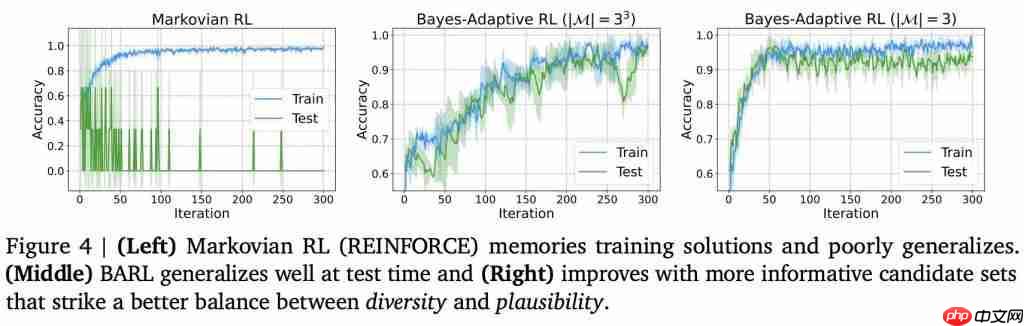
合成任务案例:更清楚的对比RL和BARL
为了直观展示BARL如何在测试时展现反思探索能力,作者设计了一个合成任务:模型需要在3步内输出三个连续相同的字符(0/1/2),才能获得奖励。
训练阶段,提示(prompt)字符只会是0或1,模型学会了对应输出000或111来拿到奖励;但测试时,提示字符变为了2。
直觉上,训练时学到的确定性策略在遇到新字符时将不再有效,需要模型即时探索正确的输出模式。
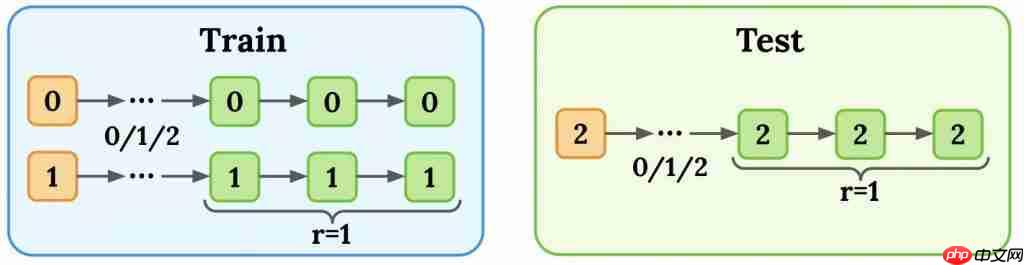
让两个模型来挑战这个任务:一个用传统马尔可夫RL训练,另一个用BARL方法训练。
Markovian RL很快便最大化了训练准确率,几乎将这些答案背了下来。
BARL在训练中同样学会了正确输出模式,但更有趣的是,它同时学会了根据不确定性来调整策略——这一点要等到测试才能看出差别。
测试阶段揭示了截然不同的行为。即当提示变为新字符2时,Markovian RL由于在训练中只记住了固定的输出(000/111)无法泛化,因此几乎总是答错,测试准确率接近于零。
而BARL代理则展现出“反思”能力。它会先尝试某个策略,如果初步尝试未获得奖励,就迅速反思切换,尝试另一种可能的序列。
下图形象说明了Markov RL和BARL在该合成任务中的决策差异——
Markov策略一条路走到黑,BARL策略则懂得排除无效假设,适时切换新策略。
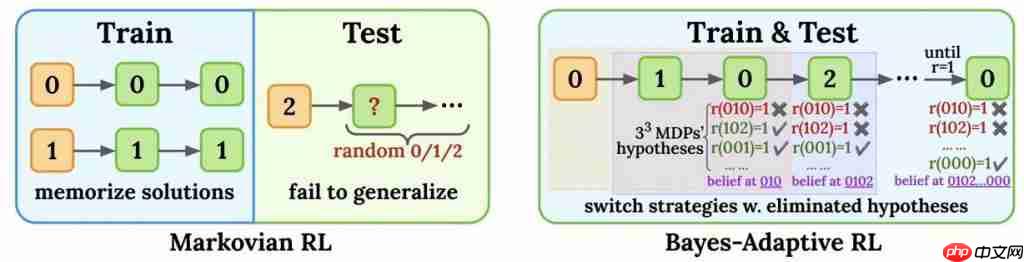
可以看到,左图中马尔可夫RL模型训练时成绩很快逼近100%,但测试时几乎完全失败,中图的BARL模型则不仅训练表现提升,在测试时也取得了显著的高准确率。
值得注意的是,右图显示如果事先给予BARL一些关于任务结构的先验知识(如“奖励模式就是某个字符重复三次”),它的收敛速度和最终成绩还会更好。
这说明了候选策略既要有多样性以覆盖未知情况,又要有合理的可信度以不至于无谓浪费精力。
数学推理任务:性能全面提升,显著节省Token
研究人员还将BARL应用于LLM的数学推理领域,并比对了GRPO和“Progress”奖励基线(给予正确答案概率的分步奖励)。
BARL在大部分基准和模型上均取得了更高的准确率。
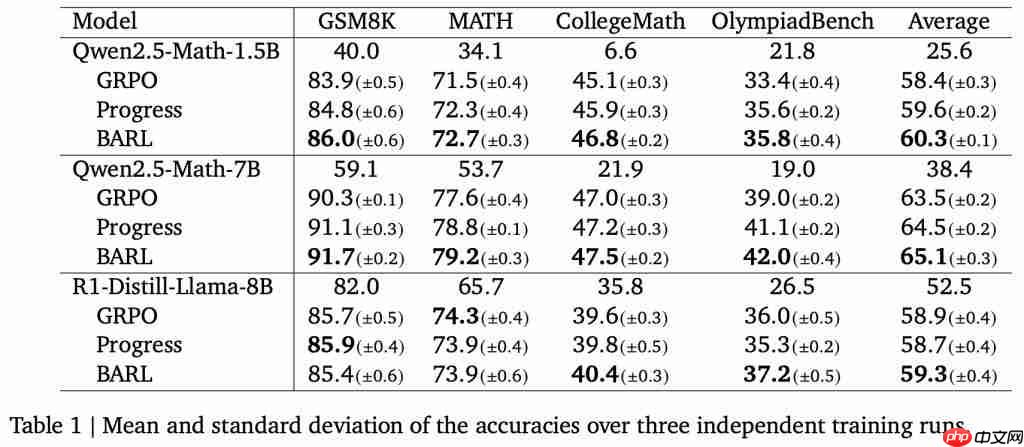
不仅如此,BARL还展现出更高的效率优势。
作者特别度量了每种方法为解出题目所耗费的token数量,结果发现在达到同等甚至更高准确率的情况下,BARL生成的内容要短得多。

这意味着,BARL模型并不会为了“多反思几次”而付出冗长啰嗦的代价,反而因为每次反思都更有针对性、更有效。
作者还观察到另一个有趣的现象:反思次数本身并非决定性能的唯一因素。
基础模型往往出现很多徒劳的反思,并没有带来实质的信息增益。相比之下,BARL的反思行为更加“有目的性”。

谷歌浏览器Google Chrome是一款可让您更快速、轻松且安全地使用网络的浏览器。Google Chrome的设计超级简洁,使用起来得心应手。这里提供了谷歌浏览器纯净安装包,有需要的小伙伴快来保存下载体验吧!

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 547
547
























