

HDFS(Hadoop Distributed File System)是一种分布式文件系统,旨在存储和管理大规模数据集。它采用主从(Master/Slave)架构,由一个NameNode和多个DataNode构成。以下是HDFS文件系统的核心结构及其组成部分:
NameNode:
DataNode:
Secondary NameNode:
数据块(Block):
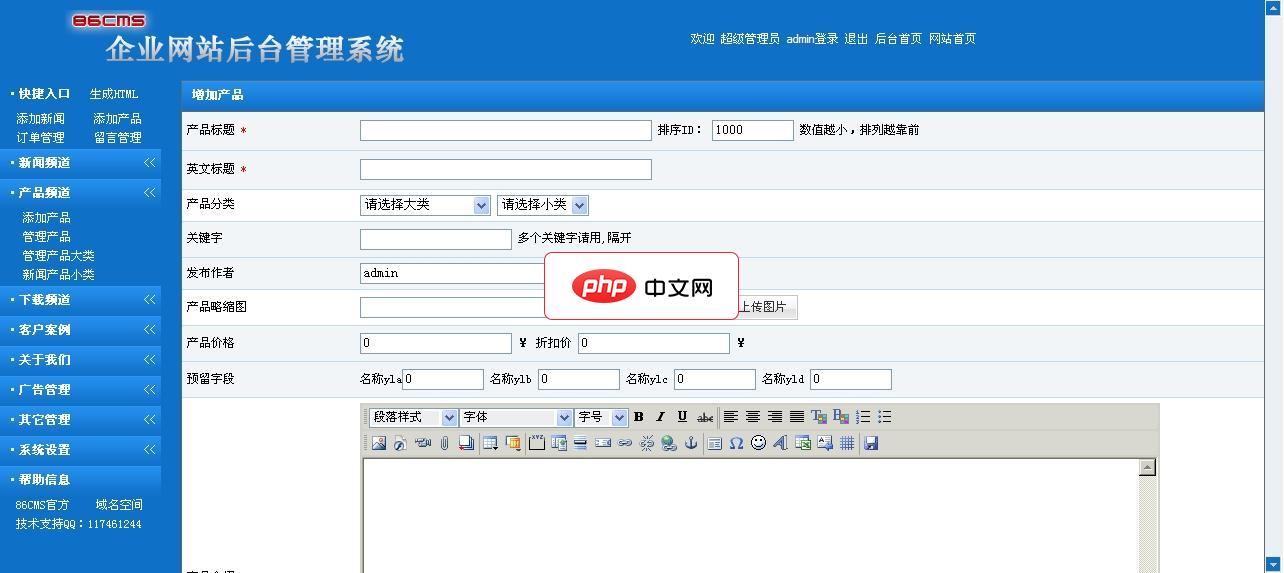
86CMS企业网站系统为智能ASP网站管理程序,适合中小企业自建网站、二次开发使用。本程序具有体积小巧、程序文件结构严谨、界面清爽简单、功能强大、非专业人士使用入门快、中小企业使用投资小等实用特点。本版本为中英繁版本。86CMS企业网站系统中英繁三语版 v1.2 更新1.修正英文版的flash幻灯调用出错问题。2.修正英文版导航菜单设置出错问题。3.增加信息是否显示在中英各版的功能。4.调整首页视
 1
1

副本分布策略:
客户端:
HDFS的设计目的在于为大数据应用提供高吞吐量的数据访问能力,支持PB级的数据存储与处理。凭借数据块复制与容错机制,HDFS保证了数据的高度可靠性和可用性。
以上就是HDFS文件系统结构是怎样的的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号





 516
516






















