







omniflow是由松下与加州大学洛杉矶分校(ucla)联合开发的一种多模态人工智能模型。该模型能够实现文本、图像和音频之间的任意到任意(any-to-any)生成任务,比如将文字描述转化为图像或声音,或将音频内容转化为视觉图像等。omniflow在现有图像生成流匹配框架的基础上进行了扩展,通过整合并处理三种不同类型的数据特征,学习复杂的数据关系,避免了对不同模态数据特征进行简单平均所带来的局限性。其模块化设计支持各部分独立预训练和微调,从而显著提高了训练效率以及模型的可扩展性。omniflow在多模态生成领域展现出强大的性能与灵活性。

☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
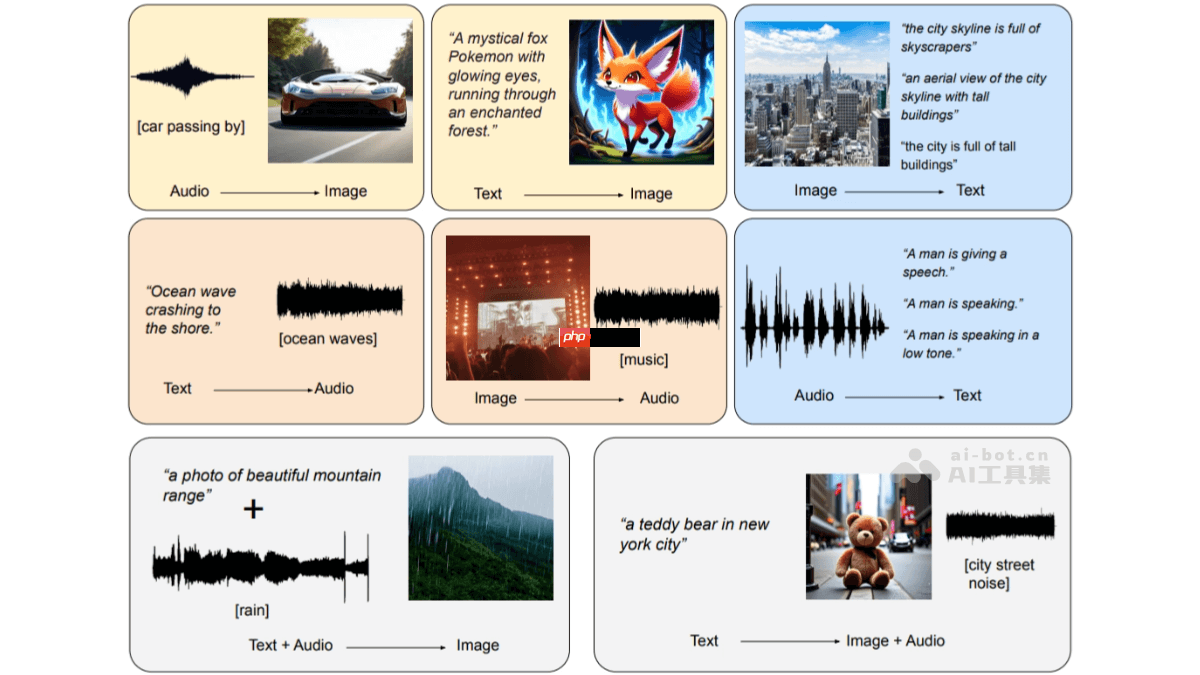 OmniFlow的核心功能
OmniFlow的核心功能
-
任意到任意(Any-to-Any)生成:可在文本、图像和音频之间自由转换与生成。
- 文本到图像(Text-to-Image):根据文字描述生成相应图片。
- 文本到音频(Text-to-Audio):将文本内容转换为语音或音乐。
- 音频到图像(Audio-to-Image):依据音频内容生成相关图像。
- 多模态输入到单模态输出:允许组合多种模态输入,如文本+音频共同生成图像。
- 多模态数据处理能力:具备同时处理文本、图像和音频等多种类型数据的能力,适用于复杂的多模态生成任务。
- 灵活的生成控制机制:通过引入多模态引导机制,用户可以在生成过程中灵活调整不同模态之间的对齐方式和交互程度,例如突出图像中的某个特定元素或调整音频语调。
- 高效训练与良好扩展性:基于模块化架构设计,各个模态组件可以独立预训练,在需要时再合并微调,从而提升训练效率并增强模型扩展能力。
OmniFlow的技术原理
- 多模态修正流(Multi-Modal Rectified Flows):OmniFlow是在修正流(Rectified Flow)框架基础上发展而来,用于处理多模态数据的联合分布。它通过整合并处理文本、图像和音频三种不同的数据特征,能够学习更复杂的数据关联,避免传统方法中因简单平均而导致的问题。修正流框架使模型能够在生成过程中逐步减少噪声干扰,从而生成高质量的目标模态数据。
- 模块化架构:采用模块化结构,将文本、图像和音频处理模块分别构建。在完成各自预训练后,这些模块可以灵活组合,并针对具体任务进行联合微调。
- 多模态引导机制:OmniFlow引入了一种多模态引导机制,允许用户通过参数调整来控制生成过程中不同模态之间的互动与协调。
- 联合注意力机制:利用联合注意力机制,实现不同模态特征之间的直接交互。在生成过程中,模型能动态识别并关注各模态间的相关性,以生成更加一致且质量更高的结果。
OmniFlow的项目地址
- 官方网站:https://www.php.cn/link/714e5298558ee2f60212a2f332d0dfcf
- arXiv技术论文链接:https://www.php.cn/link/ff842a801c4817b140a19c5e1f564851
OmniFlow的应用场景
- 创意设计:根据文本描述快速生成图像或设计元素,辅助设计师获取灵感,可用于广告海报、艺术作品等内容创作。
- 视频制作:结合文本与音频生成视频内容,或依据音频生成对应的视觉效果,适用于短视频创作和动画制作等领域。
- 写作辅助工具:从图像或音频中提取信息并生成文本描述,帮助创作者撰写文章、剧本或故事梗概。
- 游戏开发:根据游戏剧情文本自动生成场景设定、角色形象或音效资源,加快游戏开发进程。
- 音乐创作:依据文字描述或图像内容生成背景音乐,为电影、游戏或商业广告提供配乐支持。




























