Lingshu:医学领域的多模态大模型
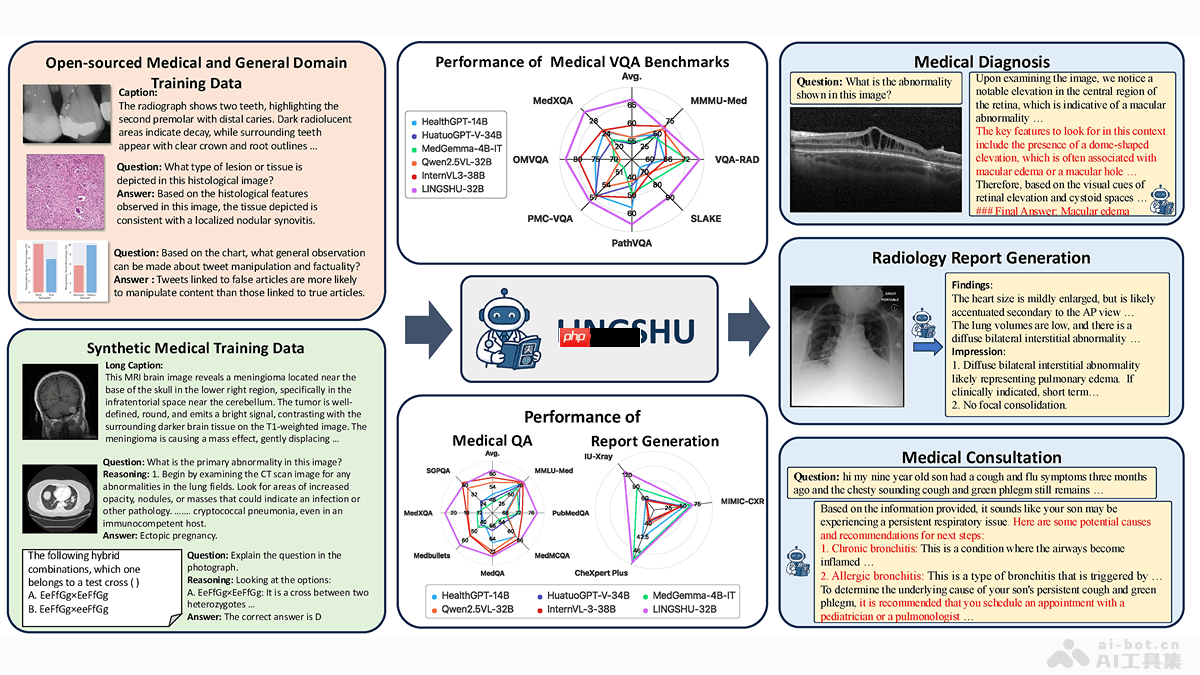
lingshu是由阿里巴巴达摩院研发的面向医疗行业的多模态大型语言模型。该模型支持超过12种医学影像类型,如x光、ct和mri等,在多模态问答、纯文本问答以及医学报告生成等方面表现出色。通过多阶段训练策略,逐步引入医学专业知识,显著增强了其在医学领域中的推理与问题解决能力。lingshu提供7b和32b两种参数规模版本,其中32b版本在多项医学多模态任务中表现优于gpt-4.1等商业模型。此外,lingshu项目还推出了medevalkit评估框架,整合了主流医学基准测试,推动医学ai模型的标准化评估发展。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
核心功能
-
多模态医学问答:能够处理多种医学图像类型的视觉问答任务,结合输入的医学图像与相关问题,生成准确的回答。
-
医学报告自动生成:可根据医学图像内容生成高质量的放射学报告,包括“发现”和“印象”两个关键部分,为医生提供有价值的参考信息。
-
医学知识应答:可回答各类纯文本形式的医学问题,涵盖广泛医学领域知识,为医学生、临床医生及研究人员提供精准的信息支持。
-
医学推理与辅助诊断:具备较强的医学逻辑推理能力,能够结合图像与文本信息进行复杂分析并提供诊断建议。
-
医学图像识别与标注:能识别并标注医学图像中的关键病变特征,例如位置、类型和严重程度,支持生成详尽的图像描述,协助医生更好地理解图像内容。
技术实现机制
-
数据准备:
-
采集来源:从多个渠道获取医学图像数据、医学文献资料及通用领域语料。
-
质量控制:对图像进行筛选去重,对文本进行清洗整理,确保训练数据的相关性与准确性。
-
样本合成:生成高质量的医学图像标题、视觉问答(VQA)样例及推理路径,扩展训练集。
-
模型结构设计:基于Qwen2.5-VL架构构建,包含三个核心模块:大型语言模型负责文本处理与生成,视觉编码器用于提取图像特征,投影器将图像表示映射至语言模型空间。
-
分阶段训练流程:
-
初步医学适配:使用少量医学图文对进行微调,使模型能够准确解析医学图像并生成基本描述。
-
深度医学融合:采用更大规模、更高品质且语义更丰富的医学图文对进一步训练,深入整合专业医学知识。
-
指令优化训练:基于大量医学指令数据优化模型执行特定任务的能力。
-
强化学习提升:应用基于验证奖励的强化学习方法(RLVR),增强模型在医学推理方面的表现。
-
评估体系构建:配套推出的MedEvalKit评估平台,集成多个多模态与文本类医学评测基准,支持多种题型,如选择题、封闭式与开放式问题及报告生成任务。平台统一数据预处理格式、后处理流程及模型接口标准,便于快速部署与一键式评估。
项目资源链接
实际应用场景
-
医学影像诊断辅助:完成多种医学影像类型的视觉问答任务,分析图像异常并提供诊断意见,生成详细的图像解读与关键特征标注,协助医生做出更精准判断。
-
医学报告自动化撰写:根据医学影像内容生成高精度的放射科与病理科报告,涵盖“发现”与“印象”部分,为临床医生提供参考依据,提升报告编写效率与准确性。
-
医学知识查询服务:提供权威可靠的医学知识解答,帮助医学生、医务工作者及相关人员获取所需信息,辅助决策制定。
-
医学科研支持:在科研过程中协助整理与分析医学图像与文本数据,提高研究效率。
-
公共卫生数据分析:可用于处理公共卫生相关数据,支持流行病学研究与归因风险计算等工作。
以上就是Lingshu— 阿里推出的医疗多模态语言模型的详细内容,更多请关注php中文网其它相关文章!



 广告
广告







 317
317
























