
某个项目,由于监控系统尚未完善,我常常需要手动检查状态。终于有一天,我发现了异常情况:
 watch -d -n1 'netstat -s | grep reset'
watch -d -n1 'netstat -s | grep reset'
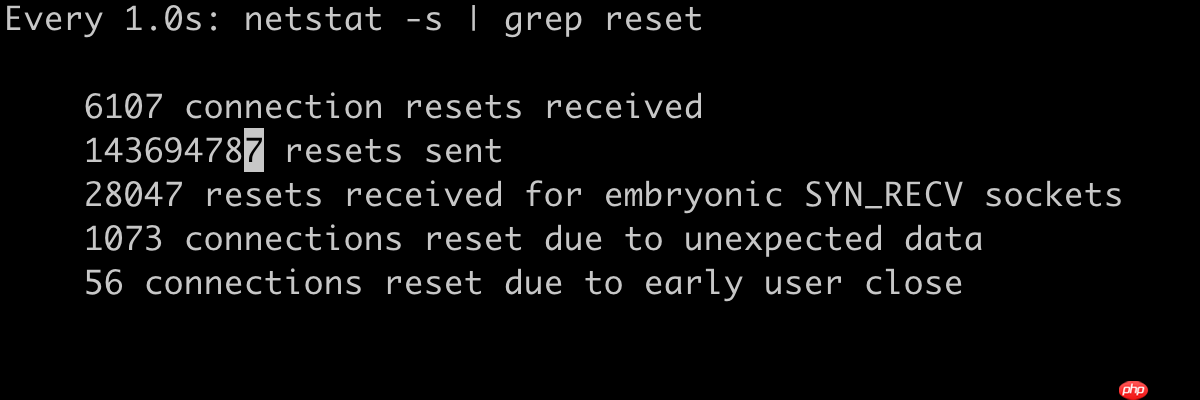
如图所示,服务器发送了大量的重置信号(RST),在监控期间还在持续发送,明显存在问题。
通过 tcpdump,我们可以简单地捕获 RST 包:
shell> tcpdump -nn 'tcp[tcpflags] & (tcp-rst) != 0'
然而,更好的方法是使用 tcpdump 捕获更多流量,然后通过 wireshark 进行分析:
 RST
RST
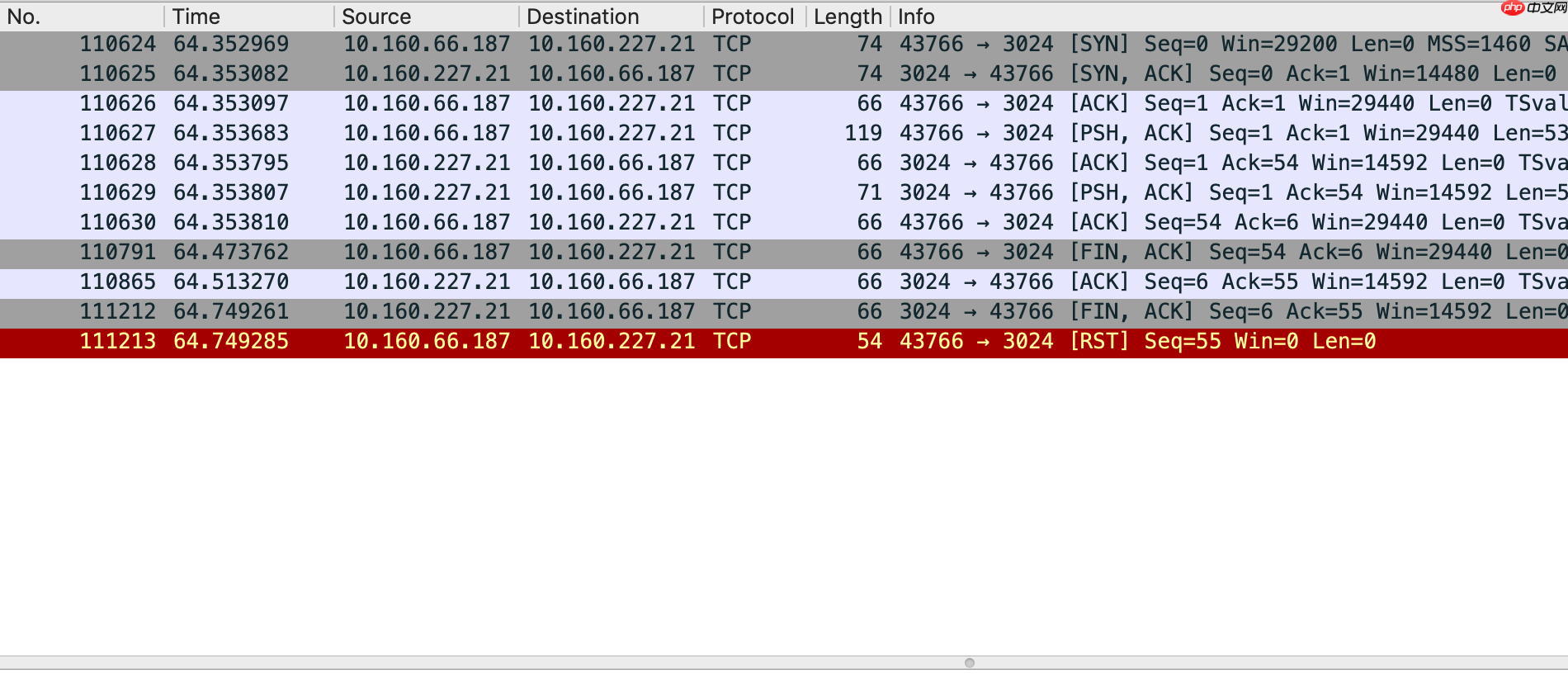
如图所示,描述了 web 服务器与 redis 服务器之间的交互过程。存在两个问题:
在我的场景中,我使用了 lua-resty-redis 连接池,为什么还会发送 FIN 来关闭连接?即使关闭连接,为什么 web 服务器在收到 FIN 后还会发送 RST 作为补充?由于项目代码较多,我暂时无法确定 lua-resty-redis 连接池的问题所在,因此我决定先解决为什么 web 服务器在收到 FIN 后还会发送 RST 作为补充的问题。
我们可以通过 systemtap 来检查内核(3.10.0-693)是通过什么函数发送 RST 的:
shell> stap -l 'kernel.function("*")' | grep tcp | grep resetkernel.function("bictcp_hystart_reset@net/ipv4/tcp_cubic.c:129")kernel.function("bictcp_reset@net/ipv4/tcp_cubic.c:105")kernel.function("tcp_cgroup_reset@net/ipv4/tcp_memcontrol.c:200")kernel.function("tcp_fastopen_reset_cipher@net/ipv4/tcp_fastopen.c:39")kernel.function("tcp_highest_sack_reset@include/net/tcp.h:1538")kernel.function("tcp_need_reset@net/ipv4/tcp.c:2183")kernel.function("tcp_reset@net/ipv4/tcp_input.c:3916")kernel.function("tcp_reset_reno_sack@net/ipv4/tcp_input.c:1918")kernel.function("tcp_sack_reset@include/net/tcp.h:1091")kernel.function("tcp_send_active_reset@net/ipv4/tcp_output.c:2792")kernel.function("tcp_v4_send_reset@net/ipv4/tcp_ipv4.c:579")kernel.function("tcp_v6_send_reset@net/ipv6/tcp_ipv6.c:888")虽然我不熟悉内核,但这并不妨碍我解决问题。通过查看源代码,可以大致判断出 RST 是由 tcp_send_active_reset 或 tcp_v4_send_reset 发送的(虽然 tcp_reset 看起来像是我们要找的,但实际上它是处理收到 RST 时的操作)。
为了确认到底是谁发送的,我启动了两个命令行窗口:
一个运行 tcpdump:
shell> tcpdump -nn 'tcp[tcpflags] & (tcp-rst) != 0'
另一个运行 systemtap:
#! /usr/bin/env stapprobe kernel.function("tcp_send_active_reset") { printf("%s tcp_send_active_reset\n", ctime())}probe kernel.function("tcp_v4_send_reset") { printf("%s tcp_v4_send_reset\n", ctime())}通过对比两个窗口显示的内容的时间点,最终确认 RST 是由 tcp_v4_send_reset 发送的。
接下来确认一下 tcp_v4_send_reset 是由谁调用的:
#! /usr/bin/env stapprobe kernel.function("tcp_v4_send_reset") { print_backtrace() printf("\n")}// output0xffffffff815eebf0 : tcp_v4_send_reset+0x0/0x460 [kernel]0xffffffff815f06b3 : tcp_v4_rcv+0x5a3/0x9a0 [kernel]0xffffffff815ca054 : ip_local_deliver_finish+0xb4/0x1f0 [kernel]0xffffffff815ca339 : ip_local_deliver+0x59/0xd0 [kernel]0xffffffff815c9cda : ip_rcv_finish+0x8a/0x350 [kernel]0xffffffff815ca666 : ip_rcv+0x2b6/0x410 [kernel]0xffffffff81586f22 : __netif_receive_skb_core+0x572/0x7c0 [kernel]0xffffffff81587188 : __netif_receive_skb+0x18/0x60 [kernel]0xffffffff81587210 : netif_receive_skb_internal+0x40/0xc0 [kernel]0xffffffff81588318 : napi_gro_receive+0xd8/0x130 [kernel]0xffffffffc0119505 [virtio_net]如上所示,tcp_v4_rcv 调用 tcp_v4_send_reset 发送了 RST。让我们看看 tcp_v4_rcv 的源代码:
int tcp_v4_rcv(struct sk_buff *skb){ ... sk = __inet_lookup_skb(&tcp_hashinfo, skb, th->source, th->dest); if (!sk) goto no_tcp_socket;process: if (sk->sk_state == TCP_TIME_WAIT) goto do_time_wait; ...no_tcp_socket: if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) goto discard_it; if (skb->len doff 有两处可能会触发 tcp_v4_send_reset(no_tcp_socket)。先看后面的 tcp_v4_send_reset 代码,也就是 do_time_wait 相关的部分,只有进入 TIME_WAIT 状态才会执行相关逻辑,而在本例中发送了 RST,并没有正常进入 TIME_WAIT 状态,不符合要求,因此问题的症结应该是前面的 tcp_v4_send_reset 代码,也就是 __inet_lookup_skb 相关的部分:当 sk 不存在的时候,发送重置信号。
但是为什么 sk 会不存在呢?当 web 服务器发送 FIN 时,进入 FIN_WAIT_1 状态,当 redis 服务器回复 ACK 时,进入 FIN_WAIT_2 状态,如果 sk 不存在,那么就说明 FIN_WAIT_1 或 FIN_WAIT_2 中的某个状态丢失了。通过 ss 观察一下:
shell> watch -d -n1 'ss -ant | grep FIN'
通常,FIN_WAIT_1 或 FIN_WAIT_2 存在的时间都很短暂,不容易观察,但在本例中,由于流量较大,所以没有问题。如果你的环境没有大流量,也可以通过 ab/wrk 等压力工具人为施加压力。结果发现,可以观察到 FIN_WAIT_1,但很难观察到 FIN_WAIT_2,看起来 FIN_WAIT_2 似乎丢失了。
原本以为可能与 linger、tcp_fin_timeout 等设置有关,经确认排除嫌疑。彷徨了许久,记起 TIME_WAIT 有一个控制项:tcp_max_tw_buckets,可以用来控制 TIME_WAIT 的数量,会不会与此有关:
shell> sysctl -a | grep tcp_max_tw_bucketsnet.ipv4.tcp_max_tw_buckets = 131072shell> cat /proc/net/sockstatsockets: used 1501TCP: inuse 117 orphan 0 tw 127866 alloc 127 mem 56UDP: inuse 9 mem 8UDPLITE: inuse 0RAW: inuse 0FRAG: inuse 0 memory 0
对比系统现有的 tw,可以发现已经接近 tcp_max_tw_buckets 规定的上限。尝试提高阈值,发现又能观察到 FIN_WAIT_2 了,甚至 RST 的问题也随之消失。
如此一来,RST 问题算是有眉目了:TIME_WAIT 数量达到 tcp_max_tw_buckets 规定的上限,进而影响了 FIN_WAIT_2 的存在(问题细节尚未搞清楚),于是在 tcp_v4_rcv 调用 __inet_lookup_skb 查找 sk 时查不到,最终只能发送 RST。
结论:tcp_max_tw_buckets 不能设置得太小!
...
问题到这里还不算完,别忘了我们还有一个 lua-resty-redis 连接池的问题尚未解决。
如何验证连接池是否生效呢?
最简单的方法是核对连接到 redis 的 TIME_WAIT 状态是否过多,如果是的话,那么就说明连接池可能没有生效,为什么是可能?因为在高并发情况下,当连接过多时,会按照 LRU 机制关闭旧连接,此时出现大量 TIME_WAIT 是正常的。
最准确的方法是使用 redis 的 client list 命令,它会打印每个连接的 age 连接时长。通过此方法,我验证发现 web 服务器与 redis 服务器之间的连接,总是在 age 很小的时候就被断开,说明有问题。
在解决问题前了解一下 lua-resty-redis 的连接池是如何使用的:
local redis = require "resty.redis"local red = redis:new()red:connect(ip, port)...red:set_keepalive(0, 100)
只要用完后记得调用 set_keepalive 把连接放回连接池即可。一般出问题的地方有两个:
openresty 禁用了 lua_code_cache,此时连接池无效redis 的 timeout 太小,此时长连接可能会频繁被关闭在我的场景里,如上问题均不存在。每当我一筹莫展的时候,我就重看一遍文档,当看到 connect 的部分时,下面一句话提醒了我:
也就是说,即便是短连接,在 connect 的时候也会尝试从连接池里获取连接,这样的话,如果是长短连接混用的情况,那么连接池里长连接建立的连接就可能会被短连接关闭掉。顺着这个思路,我搜索了一下源代码,果然发现某个角落有一个短连接调用。
结论:不要混用长短连接!
以上就是记一次Redis连接池问题引发的RST的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 110
110

























