全民k歌:歌房舞台效果开启指南
腾讯出品的全民K歌,以其智能打分、修音、混音和专业音效等功能,深受K歌爱好者喜爱。本教程将详细指导您如何在全民K歌歌房中开启炫酷的舞台效果。

步骤:
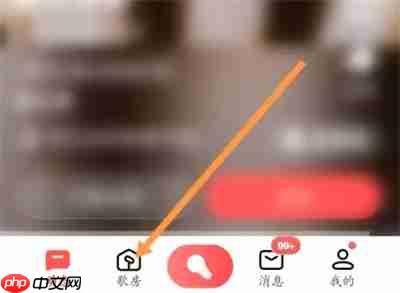
- 打开全民K歌并进入歌房: 打开全民K歌APP,点击底部菜单栏中的“歌房”图标进入。
立即学习“Python免费学习笔记(深入)”;

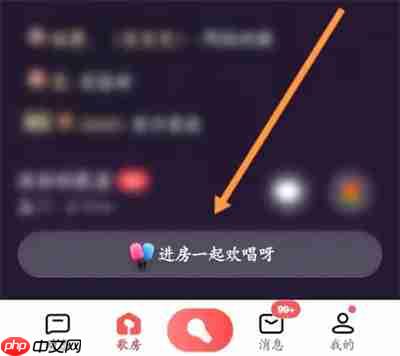
- 进入歌房: 在歌房界面底部,点击“进房一起欢唱呀”按钮。
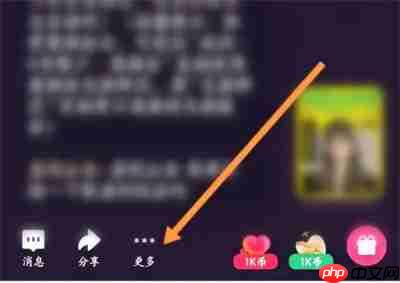
- 打开更多设置: 在歌房界面底部找到“更多”选项并点击。
- 进入演唱设置: 在弹出的菜单中,选择“演唱设置”进入。
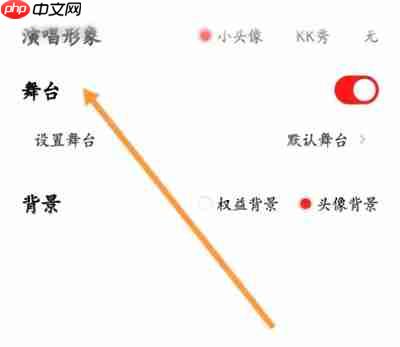
- 开启舞台效果: 在演唱设置页面找到“舞台”选项,点击其后的开关按钮,将其设置为彩色即可开启舞台效果。