








☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

• 论文题目:
Aux-Think: 探索数据高效视觉语言导航的推理策略
• 论文链接:
https://www.php.cn/link/5e0096402339448552f8dff7015d901d
• 项目主页:
https://www.php.cn/link/680c256fb6e2c27e27a9d268e8379690
视觉语言导航(VLN)中的推理机制研究
在视觉语言导航任务中,智能体需依据自然语言指令在复杂场景中进行实时路径决策。尽管推理机制已在多个领域取得成功,但在VLN任务中其作用尚未被深入研究。我们首次系统性地分析了不同推理策略对VLN任务的影响,并发现当前主流的两种推理方法(Pre-Think与Post-Think)在测试阶段反而会降低导航性能,导致任务失败。针对这一问题,我们提出了Aux-Think框架,通过结构创新有效解决了推理带来的负面影响。
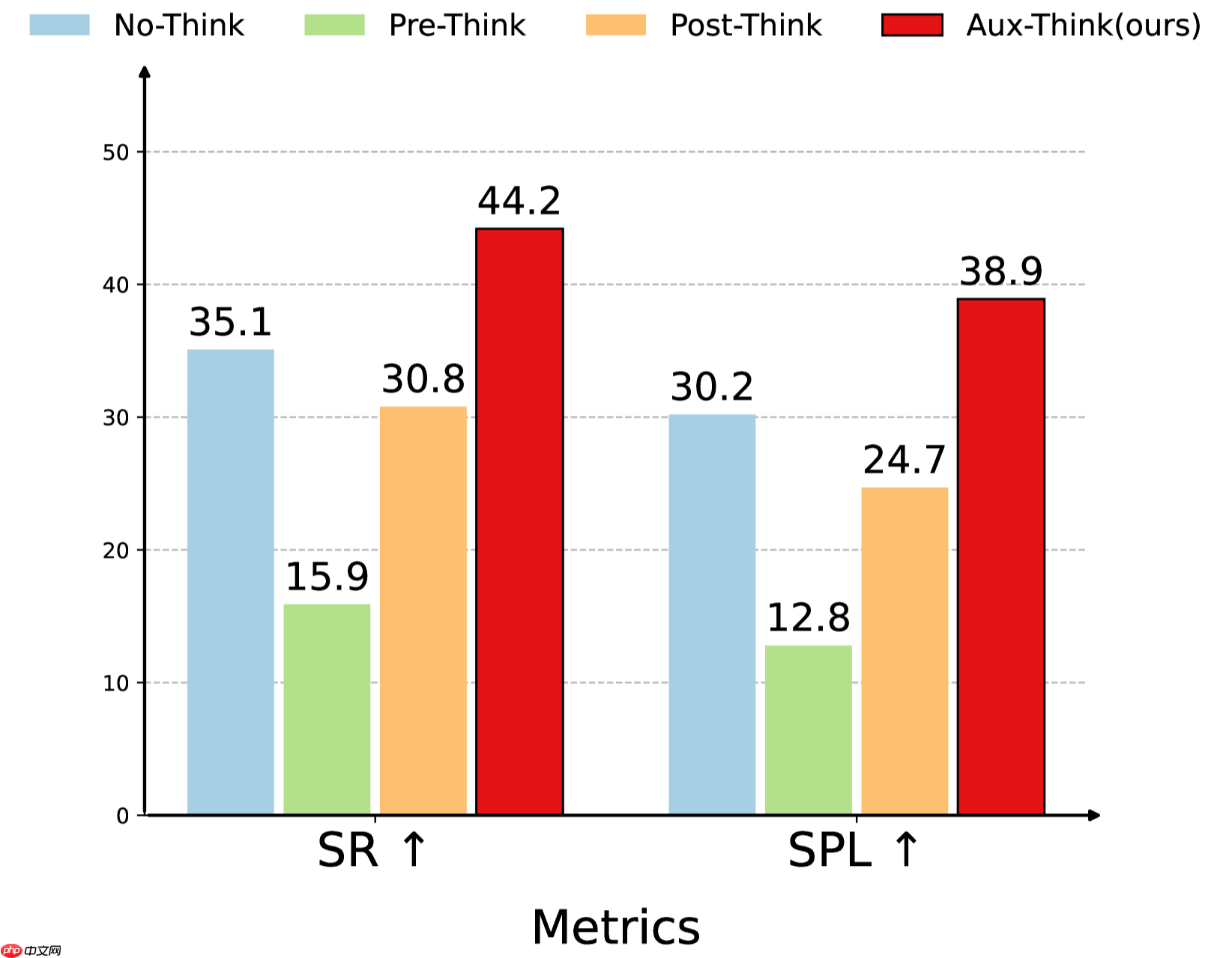
Aux-Think在多种推理策略中表现更优

Aux-Think实现了数据效率与成功率的最佳平衡
测试阶段推理存在的难题
设想一位驾驶员在行驶过程中不断回顾交通法规并反复分析路况才做出判断。虽然这种做法有助于理解环境,但在面对陌生或复杂情况时,过度依赖理论分析可能导致判断失误。
在视觉语言导航任务中,推理过程类似于“复习规则”,而实际操作则对应于“驾驶行为”。虽然推理旨在帮助智能体理解任务要求,但当进入训练未覆盖的状态时,思维链可能产生幻觉。特别是在不熟悉环境中,过度依赖推理不仅无法提升决策质量,反而会干扰行动、累积误差,最终导致导航失败。这种“推理失效”现象正是Aux-Think所致力于解决的核心问题。


长推理链中的微小错误(标红)也会引发决策偏差
Aux-Think的解决方案
为应对上述挑战,我们提出了一种全新的推理训练框架——Aux-Think。其核心思想是:在训练阶段利用推理辅助模型学习,而在测试阶段让智能体直接基于已掌握的知识进行决策,不再执行推理生成。具体设计如下:
训练阶段:通过引导模型完成推理任务,使其内化推理逻辑。
测试阶段:仅依赖训练阶段习得的知识进行动作预测,跳过推理步骤。
该设计有效规避了测试阶段推理带来的不确定性,使智能体能够更专注于任务本身,减少推理过程中的潜在干扰。

上图展示了一个典型导航任务:“穿过房间,走到右侧拱门并停在玻璃桌旁”。三种策略在相同环境下表现出显著差异:Pre-Think模型试图在行动前完整规划路径,误判为“前进75cm”,却忽略了当前尚未穿越房间;Post-Think模型在执行后才意识到未见拱门,但错误已不可逆;而Aux-Think在训练阶段学习推理逻辑,测试阶段直接根据观察判断“右转15度”,精准识别目标位置,顺利完成任务。
实验结果验证有效性
大量实验证明,Aux-Think在数据利用效率和导航性能方面均优于现有方法。即便使用较少训练数据,Aux-Think仍能在多个VLN基准测试中达到单目视觉方法中的最高成功率。通过将推理过程限制在训练阶段,该方法有效缓解了测试阶段的推理幻觉与错误传播,在长距离动态导航任务中展现出更强泛化能力与稳定性。
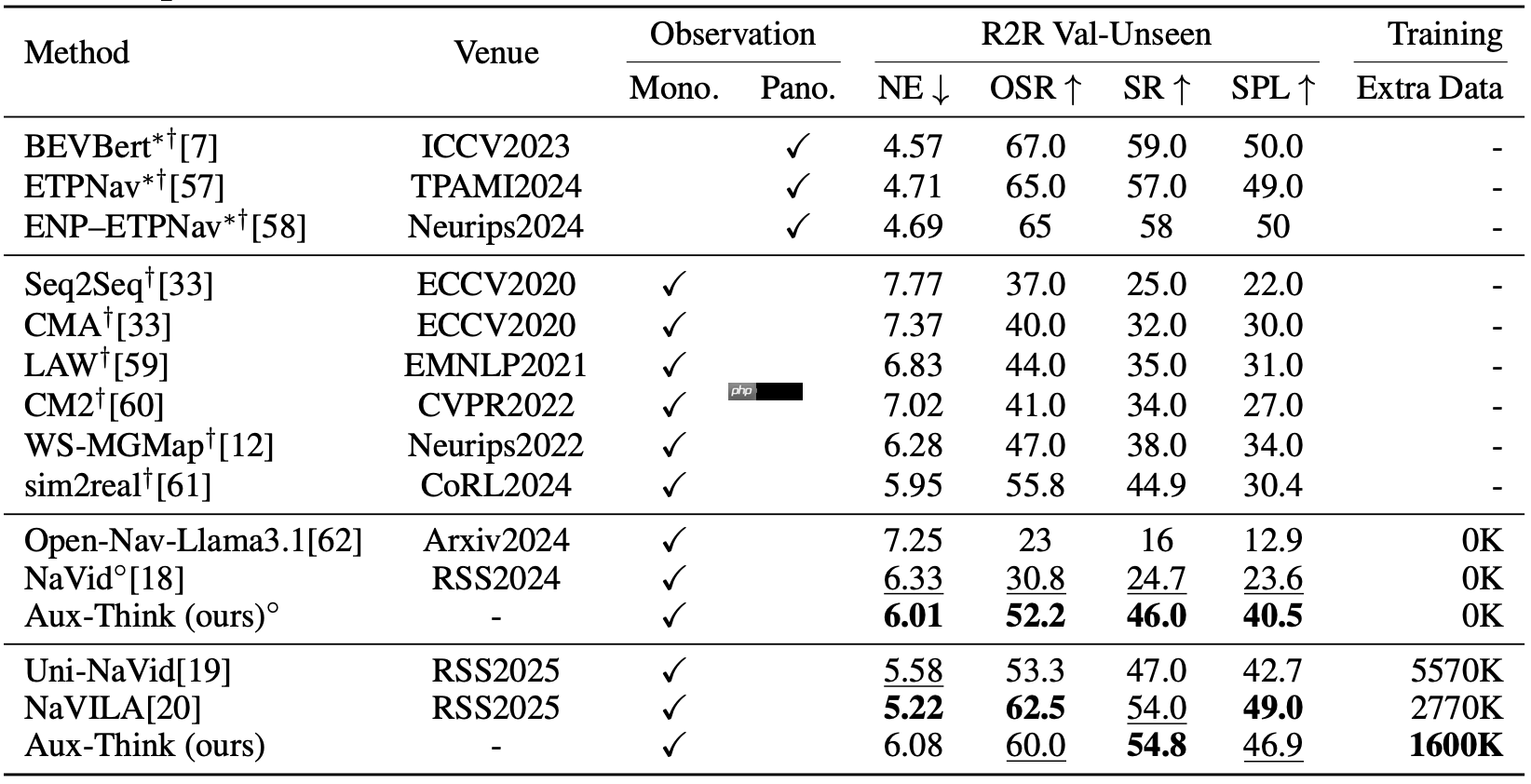
R2R-CE指标显示:在视觉语言导航任务的R2R验证集(Val-Unseen)上,Aux-Think以更少训练数据取得领先的成功率(SR)。
RxR-CE指标显示:由于RxR比R2R更大更复杂,Aux-Think在该验证集上的成功率优势更为明显,体现出卓越的泛化能力。
总结与未来方向
Aux-Think为解决测试阶段推理带来的导航问题提供了新思路。通过训练阶段引入推理指导、测试阶段去除推理负担的设计,使智能体能够更专注地执行任务,从而提升导航稳定性与准确性。这一成果为机器人在实际应用中的表现奠定了坚实基础,也为具身智能推理策略的研究提供了重要参考。




























