
" 人类最后的考试 " 首次突破 30 分,还是咱国内团队干的!
该测试集是出了名的超难,刚推出时无模型得分能超过 10 分。
直到最近,最高分也不过 26.9,由 Kimi-Research 和 Gemini Deep Research 并列取得。
现在,上海交大联合深势科技团队突然发布了一项新研究,在 " 人类最后的考试 "(HLE,Humanity ’ s Last Exam)上一举拿下 32.1 分,创下新纪录。

在这项研究中,团队推出工具增强推理智能体 X-Master、多智能体工作流系统 X-Masters。
划重点:还直接把这套方案给开源了。
网友们纷纷感叹现在 AI 竞赛太激烈,一天一个样。
另外值得一提的是,这项研究使用了 DeepSeek-R1-0528 作为驱动智能体的推理模型,由此也有网友表示:
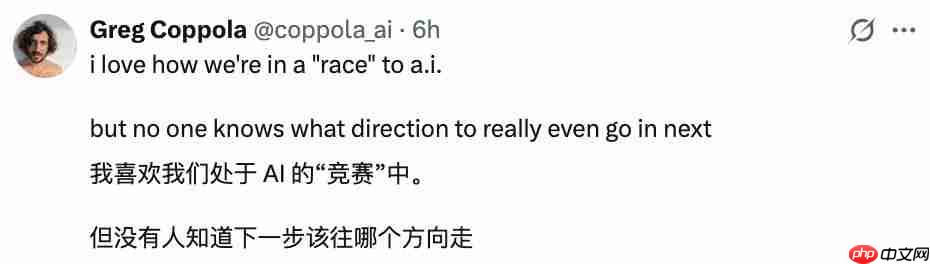
R1 在函数调用上表现仍欠佳,而且在这项研究里甚至没有针对这一点进行微调。但即便如此,只要给它搭配合适的框架,它在 HLE 这个难度很高的测试中就能拿到 32% 的成绩。
虽然大家可能会习惯性地称 R1 为 " 最佳基础模型 ",但我觉得这其实是给 V4 打下了基础。我敢肯定,V4 一出来就会自带智能体功能。
怎么做到的?
具体来看 X-Master 和 X-Masters,这是该团队 SciMaster 系列研究的第一部分,旨在开发通用科学 AI 智能体。
X-Master 是一个由开源模型(如 DeepSeek-R1)驱动的工具增强型推理智能体,其核心设计理念是模拟人类研究者的动态问题解决过程,在内部推理和外部工具使用之间流畅切换。
这一过程形成了一个共生循环:
工具输出为智能体的推理提供关键反馈,帮助其完善推理;而更清晰的推理又能引导智能体更智能、更高效地使用工具。
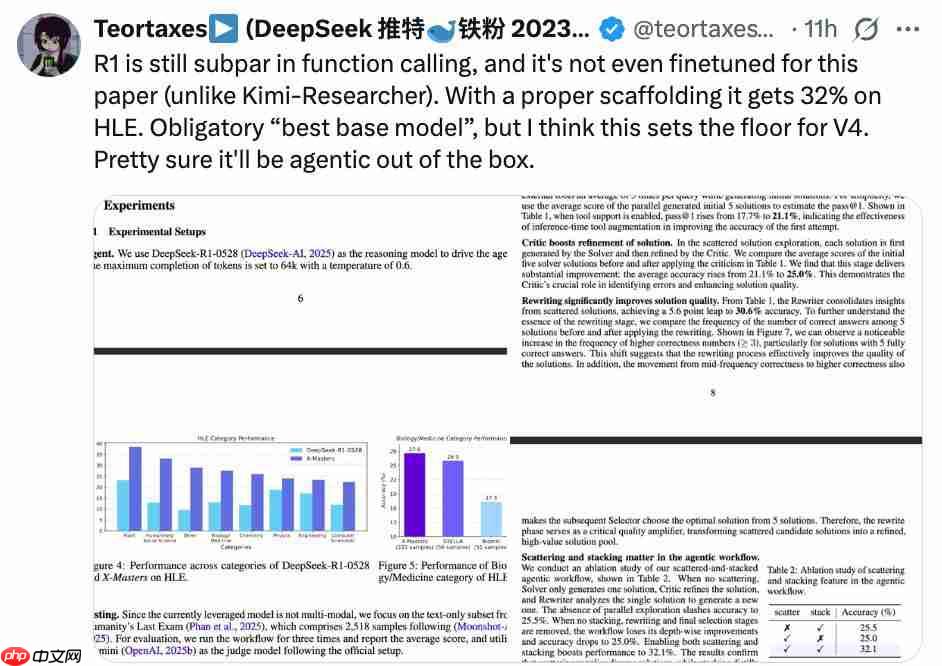
实现这一过程的核心机制是将代码概念化为一种交互语言。
当 X-Master 遇到无法通过内部推理解决的问题时,它会将精确的行动计划编写为代码块。这个 " 计划 " 随后会被执行,与任何所需资源进行接口连接,这些资源既包括 NumPy 和 SciPy 的强大数值计算能力,也包括团队专门设计的用于实时网络搜索和数据提取的工具包。
执行结果会被无缝吸收回智能体的上下文环境中,丰富其知识储备,并为后续推理提供依据。
具体而言,在智能体的思考过程中,即在 token"" 和 "" 之间生成代码以与环境进行交互。
一旦通过字符串匹配检测到这种模式,其中的代码就会被提取出来,并在一个沙盒环境中执行,在该环境中可以访问各种 Python 库和工具。
执行结果随后会被附加到模型的上下文中,并由特殊 token"
之后,推理模型会继续其思考过程,解读执行结果并进一步推理,直到发起下一次交互或思考结束。
由于当前可用的强推理模型(如 DeepSeek-R1)本质上是非智能体的,并且往往在遵循指令方面能力有限,仅依靠传统的提示工程不足以可靠地引导这些模型展现出预期的智能体行为。
因此,团队还引入了一个简单而有效的机制:初始推理引导。
该机制不会让推理模型在收到用户查询后立即开始不受约束的思考过程,而是在模型的初始 ""token 之后直接嵌入一系列引导文本。
这些引导文本特意从推理智能体自身的角度出发来设计,采用第一人称表述,例如 " 我可以通过访问外部环境有效回答这个查询 "" 每当我确定需要与外部工具交互时,我会生成包裹在 和 token 之间的 Python 代码 "。
团队表示,通过将这些精心设计的自我陈述拼接至模型的上下文中,可有效地引导模型 " 相信 " 自身具备增强的能力。
即便没有针对智能体行为进行明确的微调,该模型也能够自主生成和执行代码,与环境交互,并最终发挥出强大的智能体功能。
接下来,为充分发挥 X-Master 的潜力,团队设计 X-Masters,这是一种分散 - 堆叠式智能体工作流,通过编排多智能体认知过程,系统地增强推理的广度和深度。
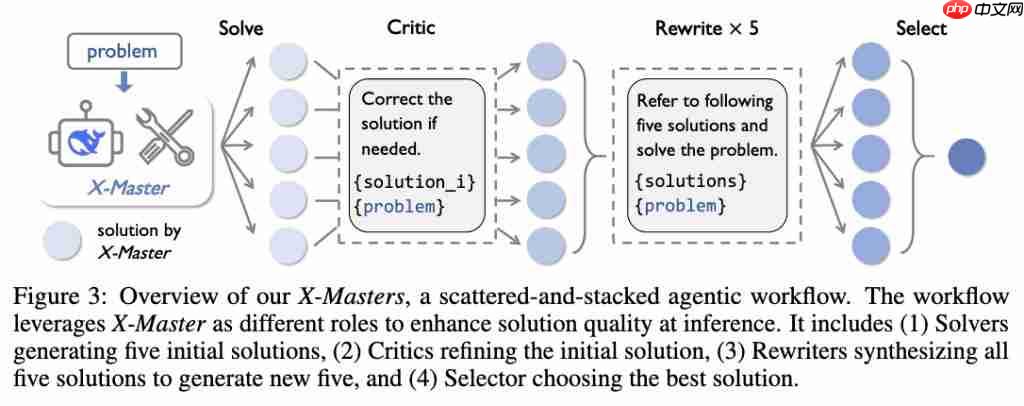
在这个过程中,X-Master 的不同实例承担着多种专门角色。
" 分散 " 阶段旨在拓宽思路,多个求解器(Solver)智能体并行工作,生成多样化的解决方案,同时批评者(Critic)智能体对这些方案可能存在的缺陷进行修正。
接着 " 堆叠 " 阶段用于深化思考,重写器(Rewriter)智能体将所有先前的输出综合成更优的解决方案,最后由选择器(Selector)智能体裁定出最佳答案。
团队表示,其分散 - 堆叠架构本质上是一种结构化探索和利用策略,与强化学习(RL)中的 "Rollouts" 概念有很强的相似性。
" 分散 " 阶段类似于强化学习中 Rollouts 的探索原理,即模拟多条未来轨迹以评估不同行动的潜力。后续的 " 堆叠 " 阶段类似于强化学习中 Rollouts 之后的聚合和 " 利用 " 步骤。
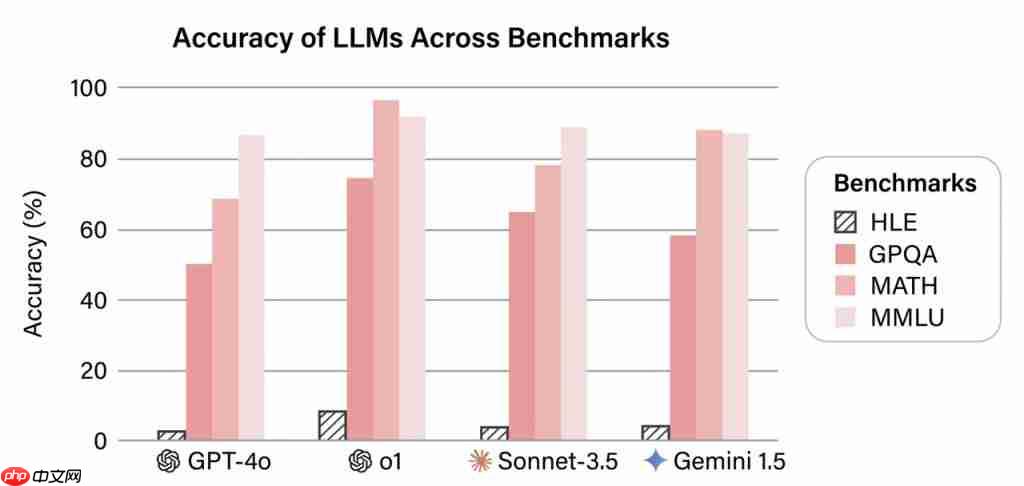
首个在 HLE 上得分超过 30% 的系统
实验部分,团队使用 DeepSeek-R1-0528 作为驱动智能体的推理模型,最大完成 token 数设置为 64k,temperature 为 0.6。
测试重点关注 HLE 的纯文本子集,包含 2518 个样本。评估运行工作流三次并报告平均分数,同时按照官方设置,使用 o3-mini 作为评判模型。
基线模型在 HLE 上的结果均来自现有的排行榜。
主要结果显示,X-Masters 取得了 32.1% 的最高分,超过了所有现有智能体和模型,这也是首个在 HLE 上得分超过 30% 的系统。
跨不同类别的性能显示,与 DeepSeek-R1-0528 相比,X-Masters 在所有类别中都显示出显著改善:
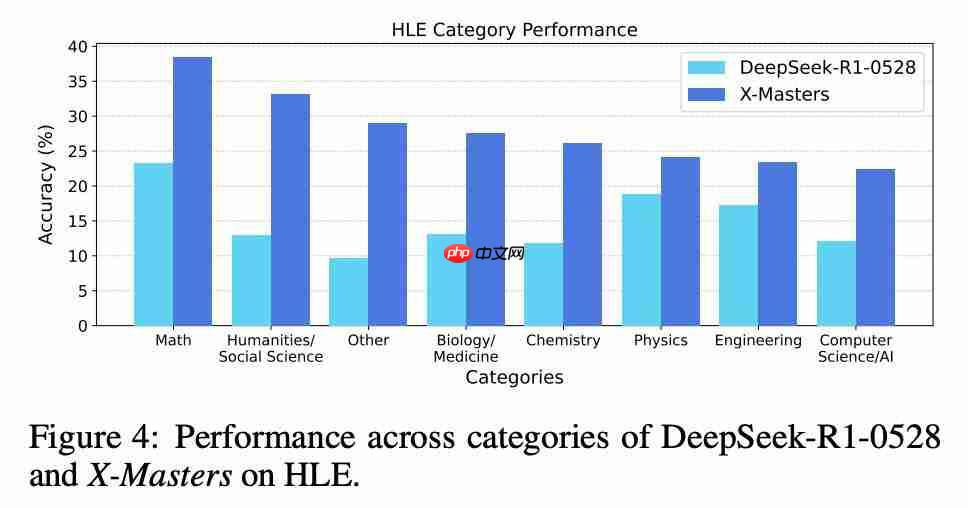
消融研究结果揭示了智能体工作流中的渐进收益:
工具增强推理(求解器)使基线准确率提高了 3.4%,迭代优化(批评者和重写器)又增加了 9.5%,最终选择(选择器)则实现了 32.1% 的纪录成绩。
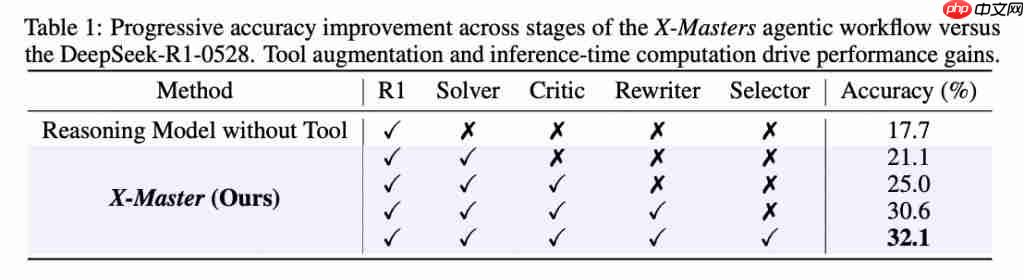
另外,团队还将 X-Masters 与生物学领域科学智能体进行对比。
近期研究成果,如 Biomni 和 STELLA,通过利用配备大量专业工具的大语言模型智能体,在应对生物学难题方面取得了一定进展。
而 X-Masters,在 HLE 的生物学 / 医学类别中,表现优于现有系统,Biomni 的正确率是 17.3%,STELLA 大概 26%,而 X-Masters 达到了 27.6%。
并且 Biomni 和 STELLA 是从生物学 / 医学类题目里挑了一部分来测试的,而 X-Masters 是考了这一类里所有 222 道纯文字题,说明它在复杂生物医学问题上的能力确实突出。
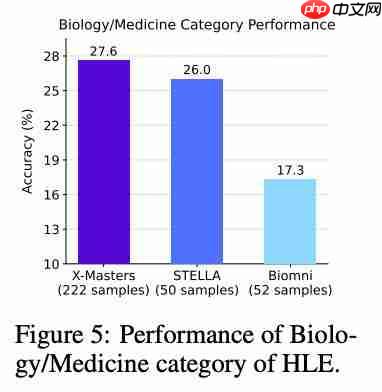
在一个叫 TRQA-lit(choice)的生物学专门测试中,X-Masters 也取得了目前最好的成绩。这个测试里有 172 道多选题,都是生物学研究里的复杂任务,比如找治疗靶点、研究生物医学机制等
独立的 X-Master 达到了 62.1% 的准确率,借助智能体工作流,X-Masters 取得了 67.4% 的 SOTA 成绩,体现了分散探索和堆叠选择的有效性。
与整合了 500 多种专家工具的多智能体系统 OriGene 相比,X-Master 仅使用两种网络工具(网页搜索和网页解析),却获得了更高的准确率,进一步印证了 X-Master 工具增强推理过程的高效性,即通过广泛探索和堆叠选择,它能够有效解决复杂的生物学任务。
" 人类最后的考试 " 是什么?
" 人类最后的考试 " 由 AI 安全中心和 Scale AI 发起,今年年初发布。刚发布时,包括 o1 在内,没有一个模型得分超过 10%,被称作是史上最难大模型测试集。
题目来自 500 多家机构的 1000 多名学者,涉及机构包括高校、研究所和企业,还有来自医疗机构的学者以及一些独立研究者等。OpenAI、Anthropic、谷歌 DeepMind 以及微软研究院都包括在其中。
团队收集到的题目需要经历大模型和人工的双重审查。不仅要达到研究生难度,而且还要确保不能被检索到。当然题目还应当有明确的答案和评判方式,证明等开放式问题不会入选。
最终入围的题目有 3000 多道。
入选的问题涵盖了数理化、生物医药、工程和社会科学等多种学科,按细分学科来算则多达 100 余个。按大类来分,可分为八大类,其中占比最多的是数学(42%),然后是物理和生物医药(均为 11%)。
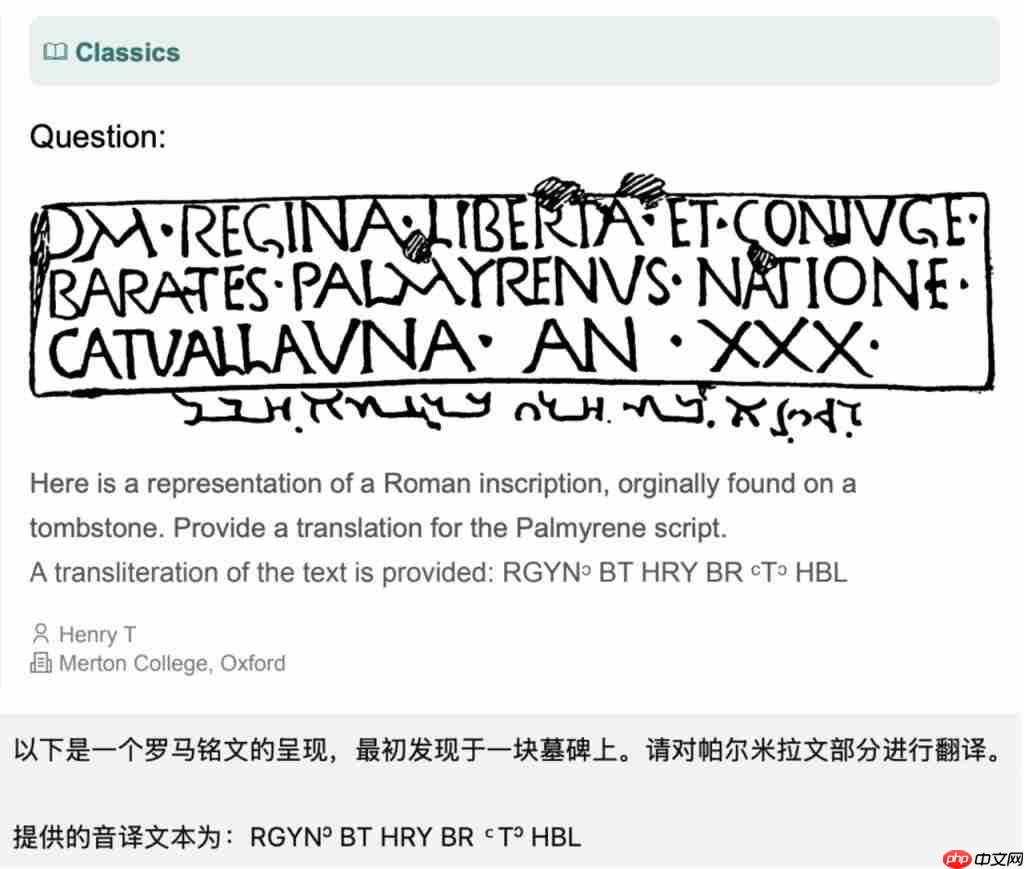
其中有些题目,还会考察模型的视觉能力,比如解读这种上古文字(翻译由 GPT-4o 生成)。
有些题目还需要结合视觉信息和文本共同理解,比如在化学,特别是有机化学当中,需要用图来表示相关物质的结构。

数学题计算机科学的题目,对推理的要求很高,难度 be like:
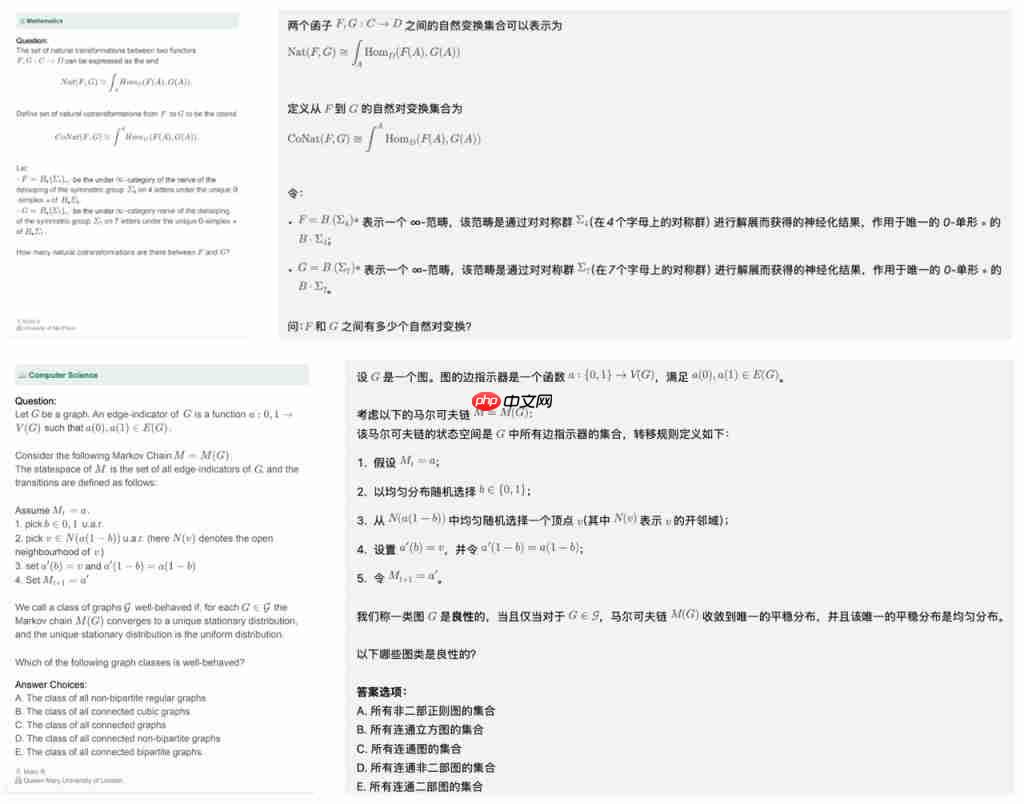
足以见得,X-Masters 拿下 32.1 分实属不易,而这项突破性成果还是出自我们国内团队之手。
共同一作 Jingyi Chai、Shuo Tang、Rui Ye、Yuwen Du 全部来自上海交通大学人工智能研究院,上海交大陈思衡副教授指导。
深势科技方面,创始人兼首席科学家张林峰亲自署名。

论文链接:https://arxiv.org/abs/2507.05241
GitHub 链接:https://github.com/sjtu-sai-agents/X-Master
参考链接:https://x.com/gm8xx8/status/1942486326726611421
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
专属 AI 产品从业者的实名社群,只聊 AI 产品最落地的真问题 扫码添加小助手,发送「姓名 + 公司 + 职位」申请入群~
进群后,你将直接获得:
最新最专业的 AI 产品信息及分析
不定期发放的热门产品内测码
内部专属内容与专业讨论
点亮星标
科技前沿进展每日见
以上就是DeepSeek-R1 超级外挂!“人类最后的考试”首次突破 30 分,上海交大等开源方案碾压 OpenAI、谷歌的详细内容,更多请关注php中文网其它相关文章!

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号









 242
242



















