
[论文阅读] web data extraction based on visual information and partial tree alignment
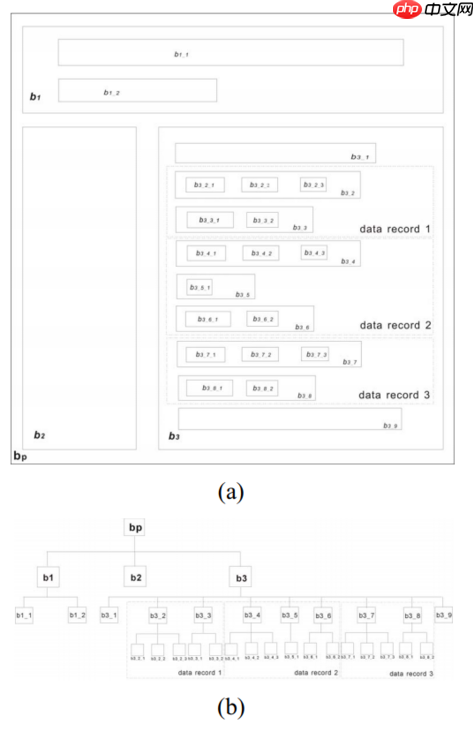
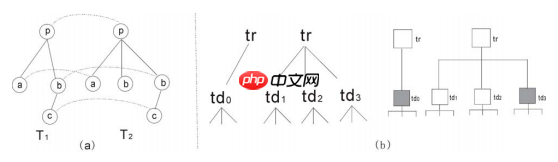
DOMTree:未经渲染的HTML节点树,如图(a)所示。VBT(Visual Block Tree):网页的可视块树模型,如图(b)所示。
视觉特性:选择网站设计者最广泛使用的属性来定义结果页面的视觉外观,例如font-weight,font-size,text-align,vertical-align,color。(【译者】云中的猫:应该还需要包含一些关于大小的属性,比如width和height)视觉相似度:如果两个块的所有视觉特性相同,则A和B视觉上相似。
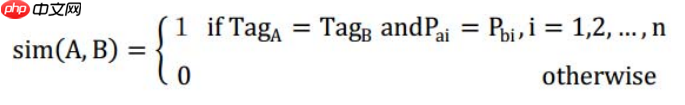
算法可分为四个步骤:
第一步:找到数据区域
数据区域:包含一组相似对象的描述的一组数据记录通常呈现在页面的连续区域中,该区域称为数据区域,比如图(a)中的b3。
通过以下公式来筛选出数据区域:
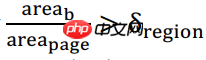
大致意思就是通过计算该区域占到整个区域的比值,获得一个关于数据区域的候选者列表(候选者对象可能不止一个,此时便选择area值最小的那一个,area值猜测为视觉区域的面积)。
第二步:在数据区域中识别记录
识别记录需要解决两个问题:
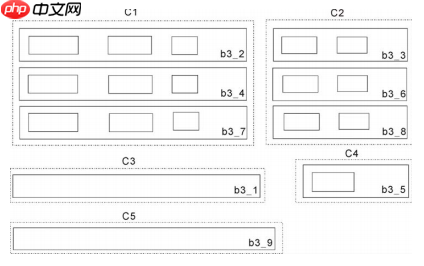
可能存在不属于数据区域中的任何数据记录的块,例如b3_1,b3_9,这些块称为噪声块。一个数据记录可以对应于可视块树中的一个或多个子树,并且一个数据记录包含的子树的总数不是固定的。作者使用了Jaccard相似性来识别数据区域的子块,然后重新组合这些块。

第三步:从这些记录中提取数据项并对齐相同语义的数据项
数据记录包含一些静态模板文本和标签,这些文本和标签不是由Web数据库生成的。这些文本或标签通常是数据的注释,例如书籍记录中的“价格:”提醒我们旁边的项目是书的价格。这些标签对Web数据注释很有用。数据记录可能包含一些可选数据项。例如,有些书有折扣价,有些则没有。
第四步:生成包装器
由于来自同一Web数据库的所有结果页面共享相同的可视化模板,因此一旦提取了结果页面上的数据记录和数据项,我们就可以使用这些提取的数据记录和数据项来生成Web数据库的提取包装器,以便可以使用包装器快速处理来自同一Web数据库的新结果页面,而无需重新应用整个提取过程。
聚类 Clustering
如果
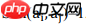 ,则把a的两个子块i和j聚类在一起。
,则把a的两个子块i和j聚类在一起。
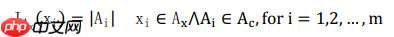
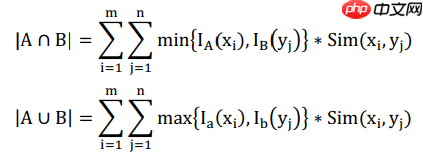
如公式所示,还是比较好理解的,作者通过节点间的视觉相似度,将Jaccard系数比较高的聚为同一类,否则分开,效果如下图所示。
重组 Regroup
在前一步骤中获得的聚类不对应于数据记录。相反,同一簇中不是噪声块簇的块都来自不同的数据记录。
需要重新组合块,使得属于相同数据记录的块形成组。重组块的基本思想如下:据统计,在数据记录中的第一块总是必须的,例如ASB 3_2,B 3_4,B 3_7。这些块称为强制块。因此,包含必需块的集群具有最大数量; 设n是这个最大数。可能有多个群集包含n个块。作者的重组方法从左到右遍历数据区域的子块,以找到包含n个块的第一个簇外观。作者将此群集称为C max。C max中的每个块是一条记录的第一块。所以作者可以找到每个记录的第一个块。而且,两个相邻的强制块之间的块形成一个记录。第一个记录左侧的块是噪声块。但是,无法识别最后的记录边界,因为数据区域底部可能存在噪声阻塞。最后一条记录不在两个相邻的强制块之间。我们的方法记录每个记录的最后一个块所属的簇,写为R 簇。然后从右到左遍历数据区域的子块,以找到属于R 簇的块的第一次出现。该块是最后一条记录的最后一个块,最后一条记录右侧的块是噪声块。最后,确定每条记录。
数据项对齐
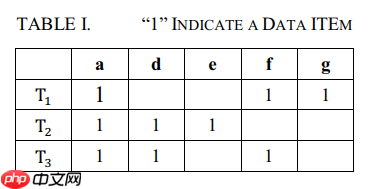
让每条记录对应成一个树,叶节点是数据项,因此需要用到树匹配技术。
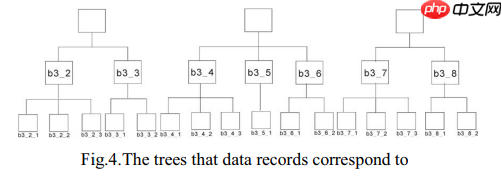
简单的树匹配让T成为一棵树。n表示T的节点数.T [i]表示在树的前序遍历中第i树的节点。(M,T 1, T 2)是从T 1到T 2的映射M ,其中M是满足以下整数(i,j)的任何整数对集合:

中间关于不同节点的映射比较还是采用了Sim()方法。
部分树匹配
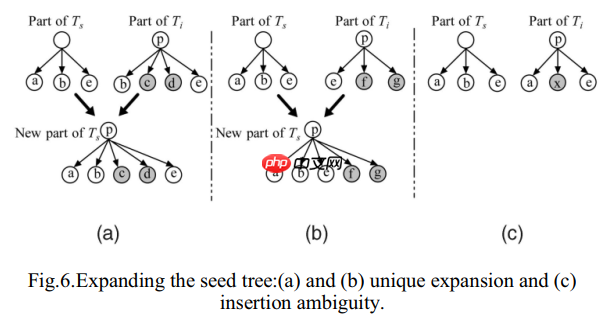



数据集和实验结果
数据集
该数据集由UIUC Web Integration Repoitory [16]提供,其中包含来自8个代表域的447个深度Web源的原始查询接口,这些域是机票,酒店,租赁,书籍,电影,音乐,工作和汽车。我们在每个域中选择5个域和4个接口。对于每个Web数据库,提交10个不同的查询并收集10个结果页面。
结果和比较
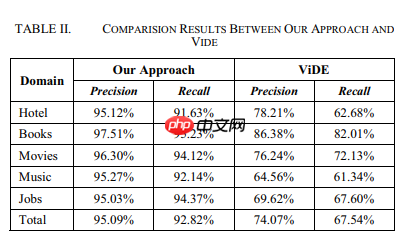

以上就是【论文阅读】Web Data Extraction Based On Visual Information的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 838
838
























