
半监督学习是指利用少量有标记数据和大量无标记数据来进行训练的过程。
 在某些特定领域,获取大量有标记的数据是困难的。
在某些特定领域,获取大量有标记的数据是困难的。
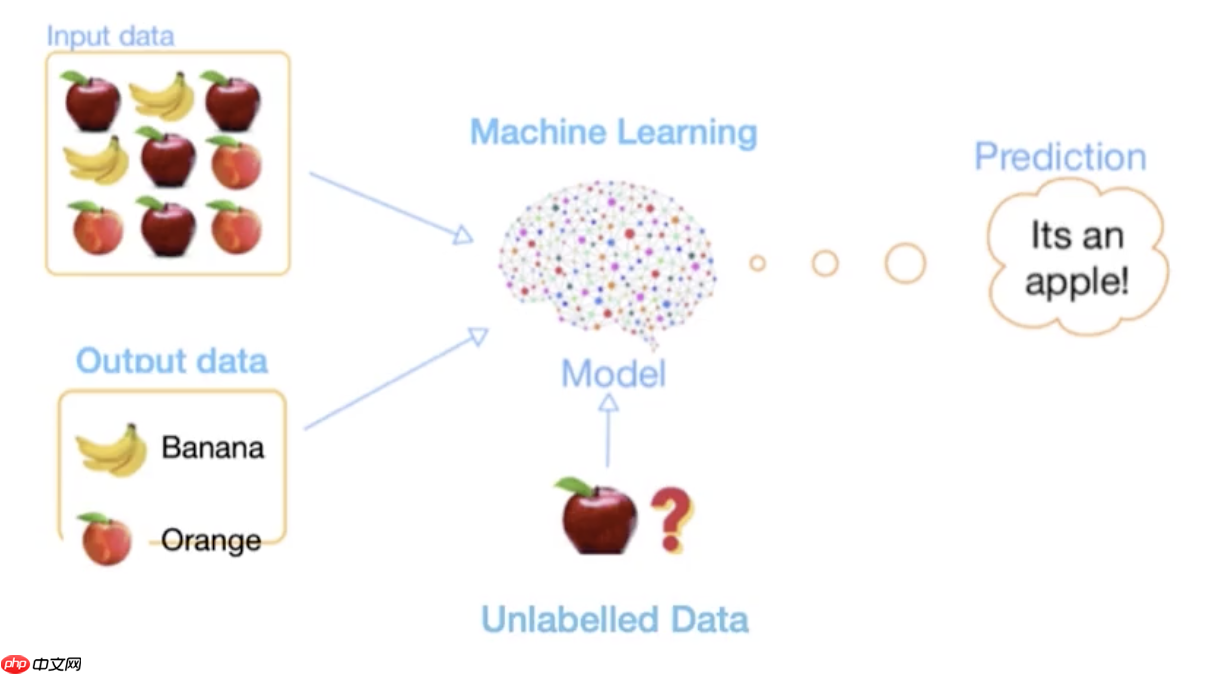 例如,我们有一个完全标注的公开数据集。我们可以先使用有监督学习的方法进行测试,然后使用10%的标注数据结合90%的未标注数据进行半监督学习,期望达到与有监督学习相似的效果。
例如,我们有一个完全标注的公开数据集。我们可以先使用有监督学习的方法进行测试,然后使用10%的标注数据结合90%的未标注数据进行半监督学习,期望达到与有监督学习相似的效果。
 半监督学习的应用包括视频理解、自动驾驶、医疗影像分割和心脏信号分析。半监督学习的前提假设包括:
半监督学习的应用包括视频理解、自动驾驶、医疗影像分割和心脏信号分析。半监督学习的前提假设包括:
连续性假设(Continuity Assumption):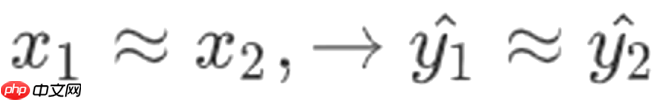 以分类问题为例,当输入数据较为接近时,比如在猫狗分类中,两张猫的图片非常相似,那么它们的输出(后验概率矩阵)也应该相似。
以分类问题为例,当输入数据较为接近时,比如在猫狗分类中,两张猫的图片非常相似,那么它们的输出(后验概率矩阵)也应该相似。
 例如,x1和x2非常接近,x1的后验概率为0.9和0.1,明显属于第一类。x2有两组输出,一组为0.85和0.15,另一组为0.55和0.45。虽然两组输出都将类别归为第一类,但第二组输出
例如,x1和x2非常接近,x1的后验概率为0.9和0.1,明显属于第一类。x2有两组输出,一组为0.85和0.15,另一组为0.55和0.45。虽然两组输出都将类别归为第一类,但第二组输出
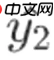 不符合连续性假设,因为它与
不符合连续性假设,因为它与
 差异较大。
差异较大。
聚类假设(Cluster Assumption): 聚类假设要求类内数据要紧密聚集,类间数据要分开。即同一类的数据要非常相似,接近于一点,而不同类别要尽量分开。因此,不能有模糊不清的图片,如
聚类假设要求类内数据要紧密聚集,类间数据要分开。即同一类的数据要非常相似,接近于一点,而不同类别要尽量分开。因此,不能有模糊不清的图片,如
 流行假设(Manifold Assumption):所有数据点都可以用低维流行来表示。相同流行上的数据点具有相同的标签。这可以理解为降维,许多高维数据的某些维度是不起作用的,其特征集中在一些低维度上。
流行假设(Manifold Assumption):所有数据点都可以用低维流行来表示。相同流行上的数据点具有相同的标签。这可以理解为降维,许多高维数据的某些维度是不起作用的,其特征集中在一些低维度上。
半监督学习的数学定义如下:
 上表来自学术论文,x代表输入,y代表输出,可以是分类输出或回归输出;
上表来自学术论文,x代表输入,y代表输出,可以是分类输出或回归输出;
 代表有标签的数据集;
代表有标签的数据集;
 代表无标签的数据集;X是整个数据集,包括有标签和无标签的数据;L是损失函数;G是生成器,半监督学习可以使用生成式模型;D是判别器;C是分类器;H是熵,通常指交叉熵;E是期望;R是正则项,半监督学习中通常指一致性正则,当然也可以使用传统的L1和L2正则;
代表无标签的数据集;X是整个数据集,包括有标签和无标签的数据;L是损失函数;G是生成器,半监督学习可以使用生成式模型;D是判别器;C是分类器;H是熵,通常指交叉熵;E是期望;R是正则项,半监督学习中通常指一致性正则,当然也可以使用传统的L1和L2正则;
 指的是标签。
指的是标签。
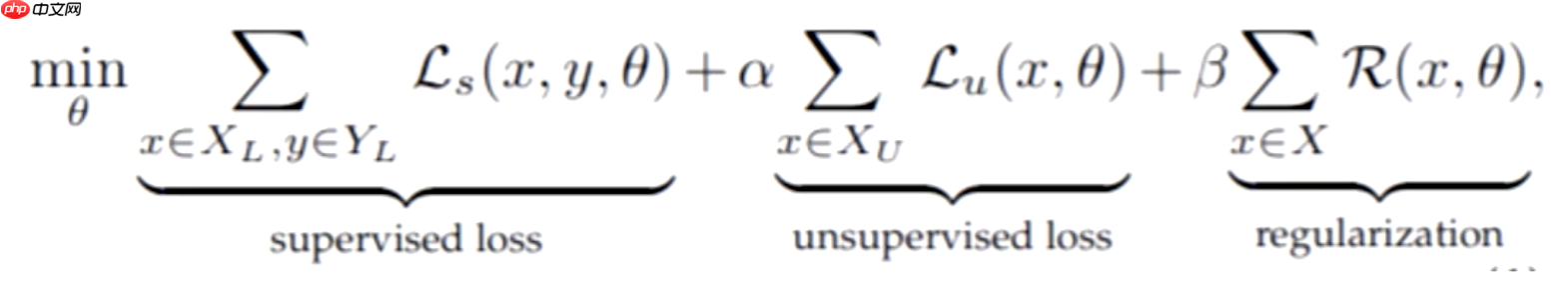 半监督学习的核心是其损失函数,通常包括三部分:第一部分是有监督的损失(supervised loss),第二部分是无监督的损失(unsupervised loss),第三部分是正则项(regularization)。由于半监督学习有少量有标签的数据,第一部分是这些有标签数据的损失;第二部分是大量未标注数据的损失;第三部分可以使用L1、L2正则或一致性正则。
半监督学习的核心是其损失函数,通常包括三部分:第一部分是有监督的损失(supervised loss),第二部分是无监督的损失(unsupervised loss),第三部分是正则项(regularization)。由于半监督学习有少量有标签的数据,第一部分是这些有标签数据的损失;第二部分是大量未标注数据的损失;第三部分可以使用L1、L2正则或一致性正则。

韩顺平,毕业于清华大学,国内著名的软件培训高级讲师,先后在新浪、点击科技、用友就职。 主持或参与《新浪邮件系统》、《橙红sns(社会化网络)网站》、《点击科技协同软件群组服务器端(Linux/solaris平台)》、《国家总参语音监控系统》、《英语学习机系统》、《用友erp(u8产品)系统》等项目。实战经验丰富,授课耐心细致,通俗易懂,勇于实践,勤于创新,授课风格贴近生活,授课语言生动风趣,多年
 632
632

第一部分的损失与之前相同,通常是交叉熵损失函数,主要设计的是后两部分的损失函数。
半监督学习的实施方法包括:
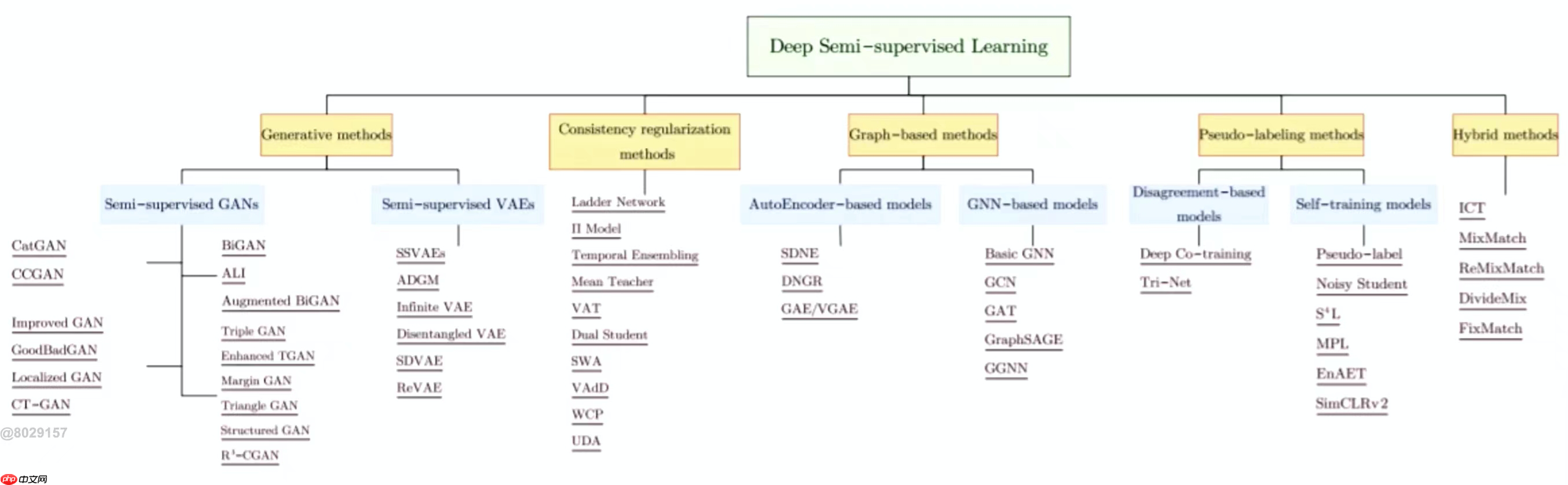 半监督学习模型可以分为五种方法:生成式模型、一致性损失正则、图神经网络、伪标签方法和混合方法。目前最常用的是混合方法,它结合了前四种方法的优点。
半监督学习模型可以分为五种方法:生成式模型、一致性损失正则、图神经网络、伪标签方法和混合方法。目前最常用的是混合方法,它结合了前四种方法的优点。
Generative Based:基于生成式网络1、重用判别器(Re-using Discriminator)
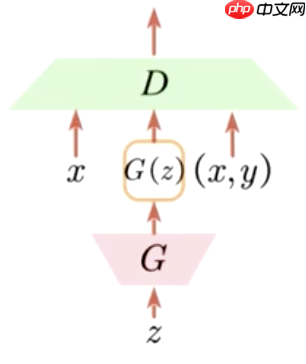 在使用GAN时,判别器充当二分类器的角色,判断输入的真实图片或生成图片的真假。在半监督学习中,重用判别器作为K类分类器,不仅对有标签的数据(x,y)进行分类,还对生成的数据(G(z))和未标注的数据x进行分类。通过这三部分的损失构建我们的K类分类器,从而联合利用未标注和有标签的数据。
在使用GAN时,判别器充当二分类器的角色,判断输入的真实图片或生成图片的真假。在半监督学习中,重用判别器作为K类分类器,不仅对有标签的数据(x,y)进行分类,还对生成的数据(G(z))和未标注的数据x进行分类。通过这三部分的损失构建我们的K类分类器,从而联合利用未标注和有标签的数据。
2、用于正则化分类器的生成样本(Generated samples to regularize a classifier)
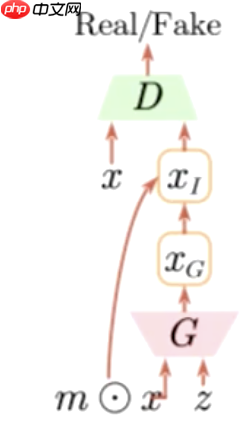 这里的判别器D仍然是一个二分类器,生成器G在生成数据时,输入包含未标注数据x和某一分布的随机初始矩阵z,共同生成
这里的判别器D仍然是一个二分类器,生成器G在生成数据时,输入包含未标注数据x和某一分布的随机初始矩阵z,共同生成
 ,然后由
,然后由
生成
 ,生成
,生成
的公式如下
 这里的m是一个二值化的掩膜,即一个与x大小相同的矩阵,其值只有0和1。0乘以x中的像素点会直接置为0,而1会保留x中的像素点的值。最后将x和
这里的m是一个二值化的掩膜,即一个与x大小相同的矩阵,其值只有0和1。0乘以x中的像素点会直接置为0,而1会保留x中的像素点的值。最后将x和
一同送入判别器D中,判别它们是否一致。我们希望判别结果一致,这意味着可以驱动判别器D识别到图片的某些特征。一旦模型训练完成,就可以单独提取判别器用于其他分类器,或作为其他损失设计的一部分,相当于一个表征或特征提取器。
以上就是半监督学习的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号





 950
950
























