
在上一期中,我们讨论了容器在运行时受到namespace、rootfs和cgroups等限制,无法将写入的数据持久化存储。然而,在云原生应用中,某些组件确实需要数据持久化存储。
回到我们开篇的问题:
X博希望利用kubeflow构建一个深度学习平台,用于训练神经网络模型,以便自动识别所有江疏影和方方的图片:
 因此,kubeflow的容器实例必须能够将训练模型持久化存储。否则,X博的工作即使找到了抓手,协调了周边资源,明确了项目目标,提炼了底层逻辑,优化了策略,采取了综合措施,但由于缺乏沉淀,没有形成闭环,最终将毫无价值。X博将面临绩效评估3.25甚至3.0的严重危机。
因此,kubeflow的容器实例必须能够将训练模型持久化存储。否则,X博的工作即使找到了抓手,协调了周边资源,明确了项目目标,提炼了底层逻辑,优化了策略,采取了综合措施,但由于缺乏沉淀,没有形成闭环,最终将毫无价值。X博将面临绩效评估3.25甚至3.0的严重危机。
那么,如何让X博及其领导下的kubeflow工作能够有效沉淀,最终形成闭环,帮助X博避免361考核的困境呢?
X博向方老师求助。尽管是来自竞争对手的请求,方老师本着知识共享的精神,为X博详细讲解了解决方案——
在创建docker容器时,我们实际上可以手动为容器添加持久化挂载的存储,例如在docker run命令中加入参数 -v。
我们来做一个实验:
首先,我们将用户切换到root,并在/root目录下创建一个名为tmp的目录。
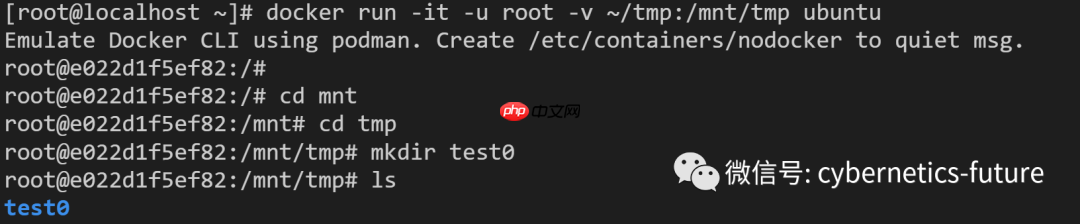
 然后,我们在root用户下运行ubuntu容器,使用以下命令:
然后,我们在root用户下运行ubuntu容器,使用以下命令:
docker run -it -u root -v ~/tmp:/mnt/tmp ubuntu
这条命令的作用是:
docker run \ #运行容器
-it \ #交互模式
-u root \ #指定使用root用户
-v ~/tmp:/mnt/tmp \# 将hostos的~/tmp/目录挂载到容器上的/mnt/tmp/目录
ubuntu \# ubuntu容器
 接下来,我们查看hostos的/root/tmp/目录:
接下来,我们查看hostos的/root/tmp/目录:
 在宿主机上,我们看到了目录test0。
在宿主机上,我们看到了目录test0。
然后,我们在ubuntu容器中执行以下操作:
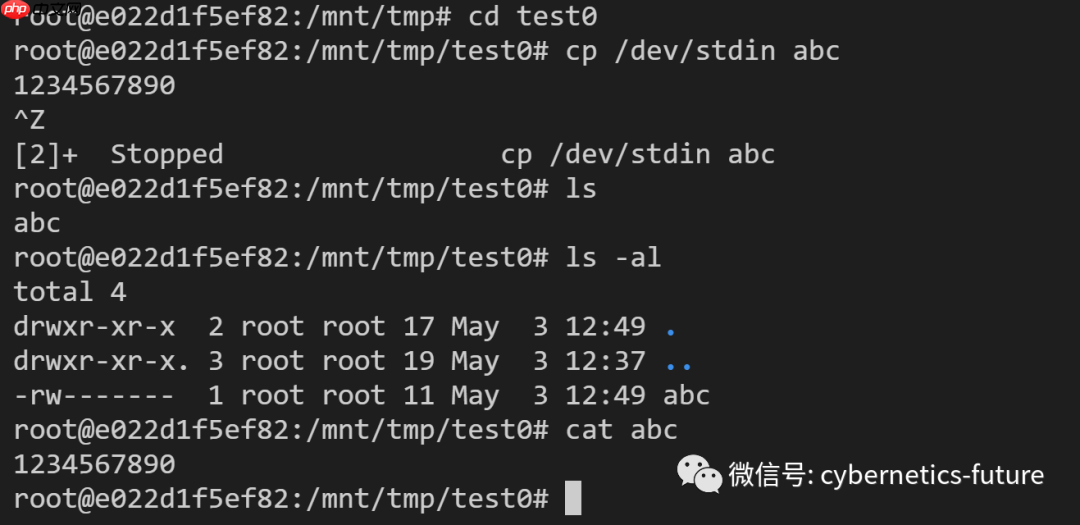 我们使用cp /dev/stdin abc命令(将标准输入拷贝到文件abc),创建一个名为abc的文件,其内容是键盘输入的内容(标准输入)。
我们使用cp /dev/stdin abc命令(将标准输入拷贝到文件abc),创建一个名为abc的文件,其内容是键盘输入的内容(标准输入)。
我们在ubuntu容器中查看abc文件的内容,与我们输入的内容一致:
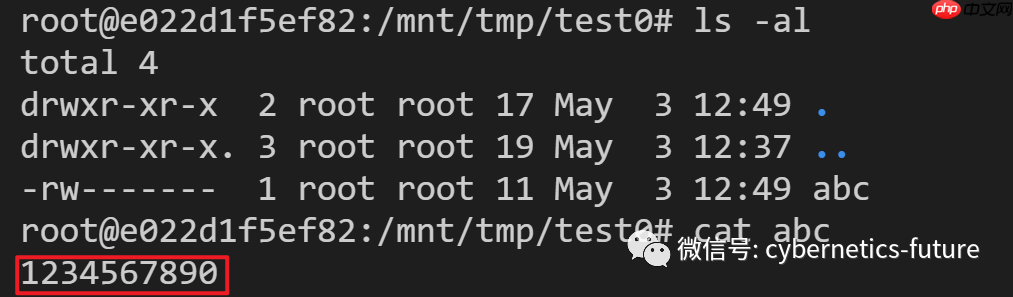 然后,我们在hostos上查看:
然后,我们在hostos上查看:
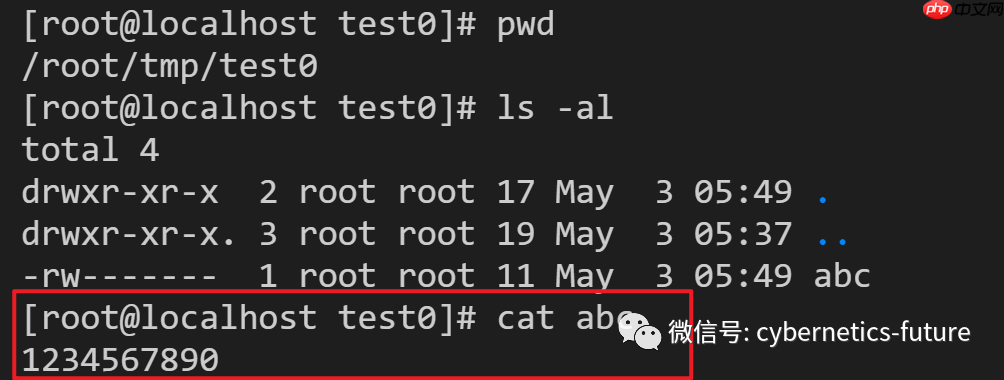 文件内容与容器中写入的内容一致。
文件内容与容器中写入的内容一致。
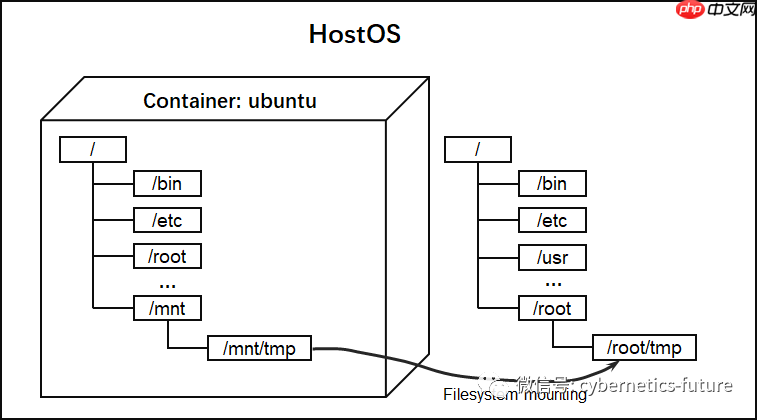
我们退出ubuntu容器后再次验证,文件仍然存在。这说明,通过为容器挂载本地持久化目录,我们已经突破了容器的次元壁,使容器能够读写外部的持久化存储。
如图所示,HostOS上的/root/tmp/目录被映射到ubuntu容器中的/mnt/tmp目录,成为了容器通过hostpath方式挂载的持久化存储。
 如果我们有一台nfs服务器,也可以在容器启动时使用命令加上-v参数,将外部nfs目录挂载为容器的持久化卷。
如果我们有一台nfs服务器,也可以在容器启动时使用命令加上-v参数,将外部nfs目录挂载为容器的持久化卷。
这样一来,X博只需要在启动kubeflow容器时加上这个参数即可。
然而,在云原生的世界里,有一条铁律:
任何需要手动操作的事情,都不符合云原生的自动化原则。
我们需要的是,让容器能够自动化地挂载外部持久化共享卷。也就是说,让kubernetes在批量启动容器时,能够自动化地让容器挂载持久化卷,无论是块存储还是文件存储。
我们如何实现这一目标呢?
请看下回分解。
以上就是云存储硬核技术内幕——(27) 次元壁坍塌的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 770
770





















