还记得kimi吗?那个凭借超强长文本处理能力,能一口气“读完”数十万字小说而一炮走红的ai助手,曾是国产大模型中备受瞩目的明星。
然而,AI领域的竞争堪称“神仙打架”,技术迭代速度令人瞠目。在一波又一波新模型的冲击下,曾经风光无限的Kimi似乎略显沉寂,不少用户甚至直言它“掉队了”。
就在外界以为月之暗面会被对手甩开时,他们却悄然祭出了一记重磅杀招——Kimi-Dev-72B。
这并非普通的升级版Kimi,而是一个专为软件工程任务打造的代码大模型。它不满足于生成几行简单代码,而是致力于解决真实世界中复杂的开发难题,堪称一位能独当一面的“虚拟程序员”。
它到底有多强?
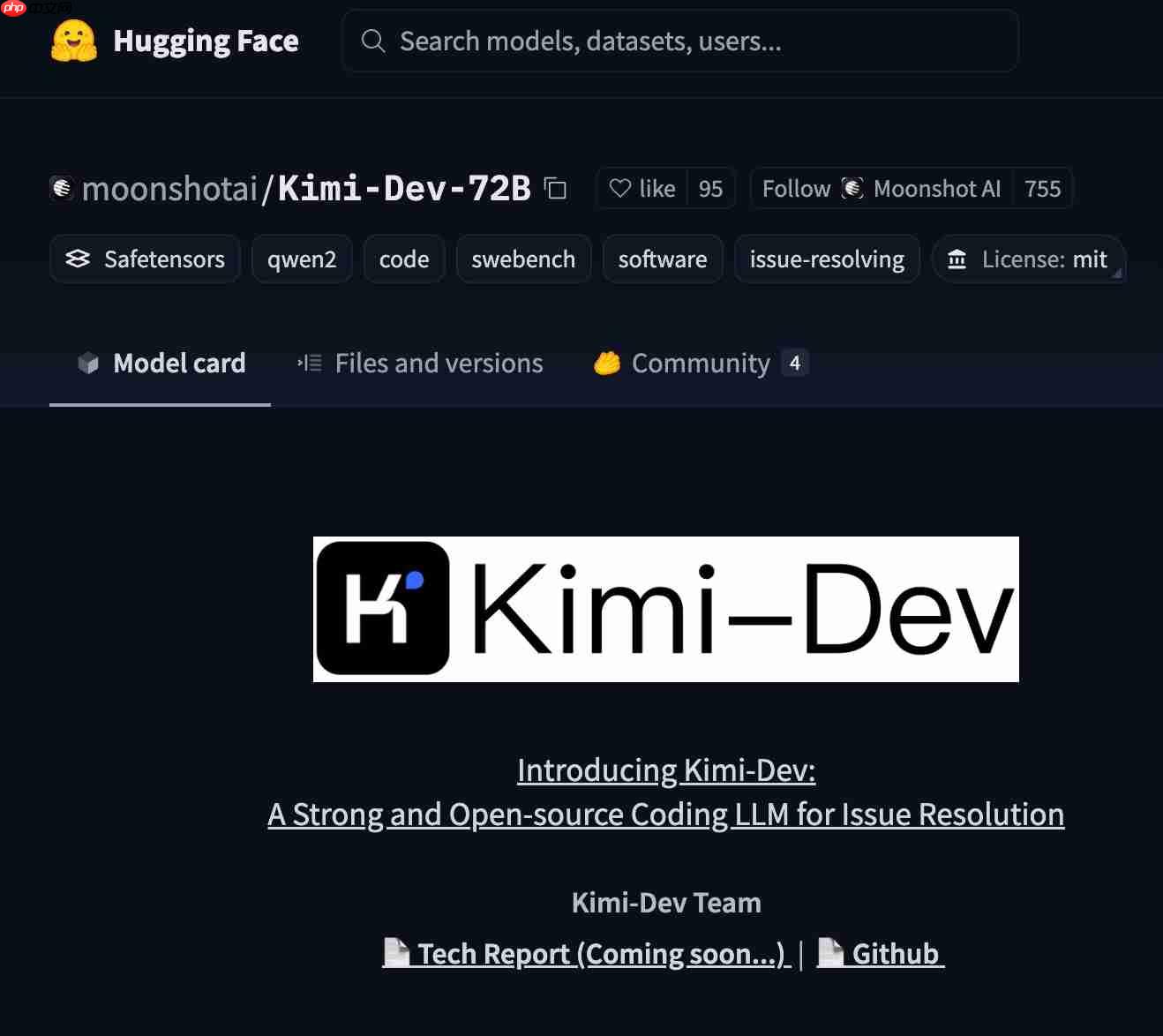
要了解它的实力,先看一项硬核指标:SWE-bench。这是目前软件工程领域最具挑战性的评测基准之一,相当于AI界的“代码奥运会”。它考验的是模型能否修复GitHub上真实存在的复杂Bug,任务难度极高。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
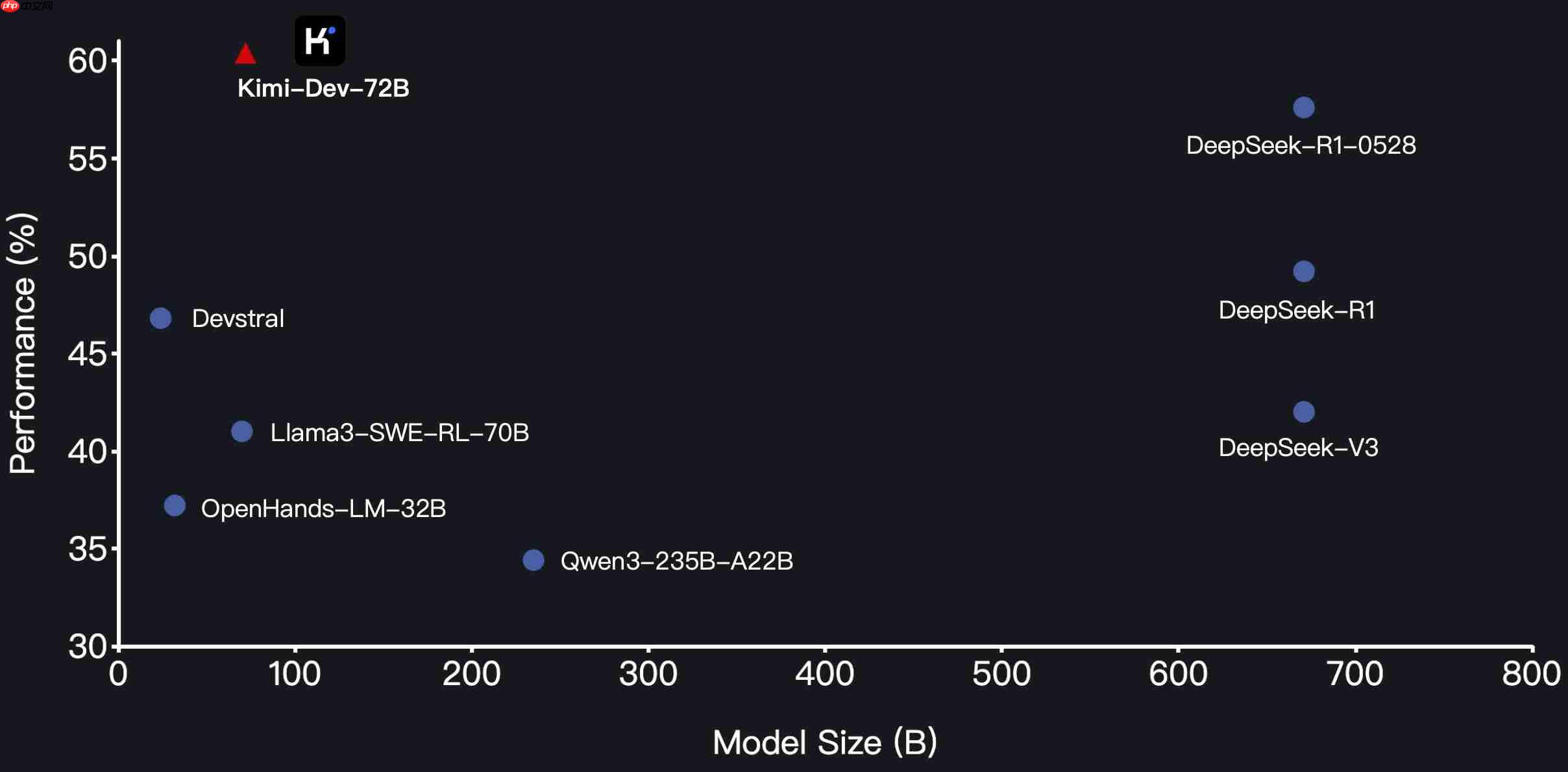
在这个含金量十足的榜单上,Kimi-Dev-72B一举拿下了当时所有开源模型中的最高分,甚至超越了GPT-4.1等闭源强者。这一成绩标志着,它在应对真实软件开发挑战方面,已为开源社区树立了新的标杆。
像顶尖工程师一样思考与工作
Kimi-Dev的“神技”从何而来?关键在于其独特的训练机制——结果驱动的强化学习。
不同于传统代码模型仅靠模仿人类写法来生成代码,Kimi-Dev更像是一个经验老道的技术专家。它的训练方式极为严苛:
真实战场:模型直接被投入真实的GitHub项目中,面对的是开发者实际提交的Bug和需求。
双脑协作:内部集成了两个“角色”——“Bug修复师”(BugFixer)和“测试编写师”(TestWriter)。前者负责提出修复方案,后者则立即编写高覆盖率的测试用例来验证方案的有效性。
唯结果论:模型不会因“语法正确”或“逻辑合理”而获得奖励。唯一的评判标准是:修复后的代码必须通过项目全部测试用例。这意味着它必须交付真正稳健、无副作用的解决方案。

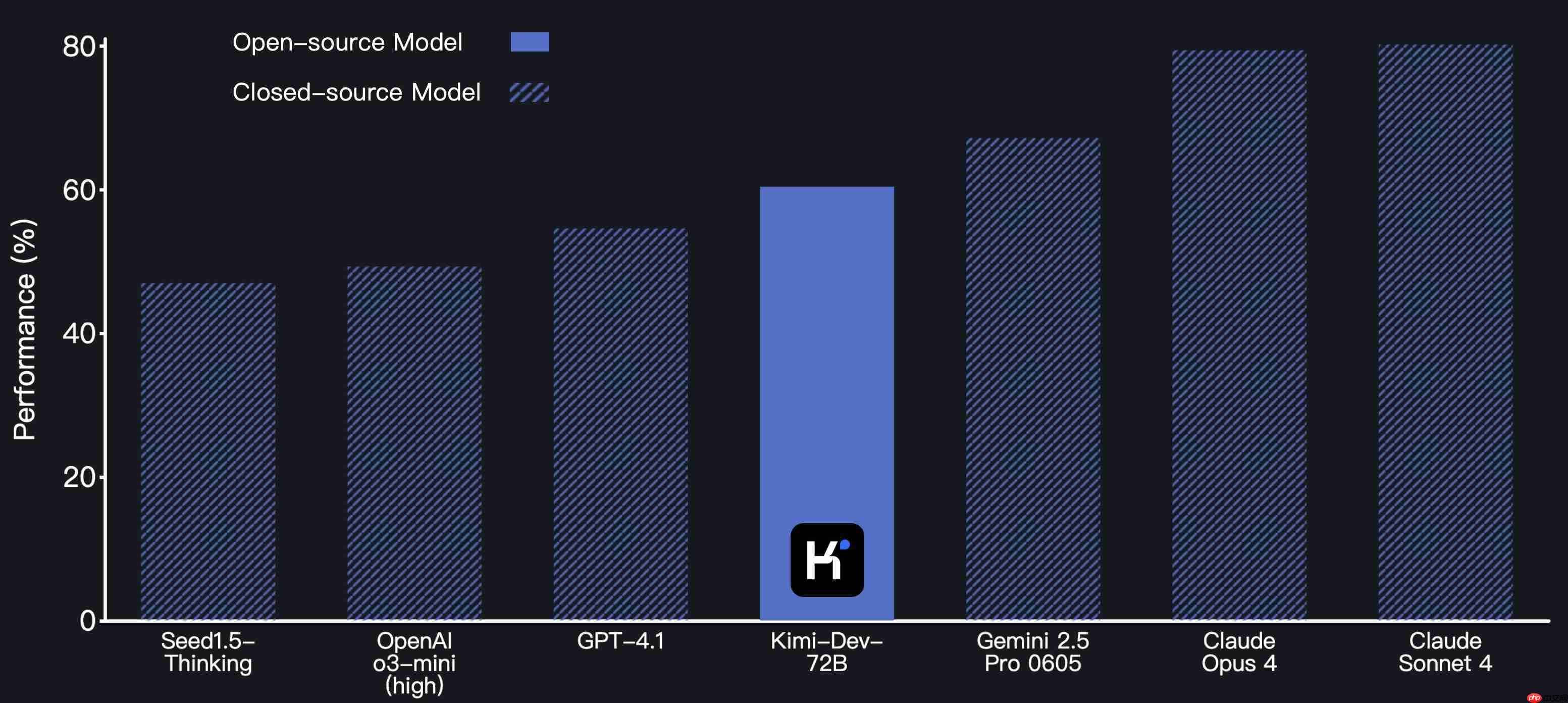
每当“修复师”提交代码,“测试师”便立刻执行检验。一旦测试失败,失败案例将作为负反馈回传,促使“修复师”调整策略,重新提交。这一“生成-验证-迭代”的闭环不断重复,直到最终达成目标:问题被彻底解决,且所有测试全部通过。
这种自我博弈、自我纠错的机制,让Kimi-Dev学会了像人类高手一样严谨思考:精准定位问题、提出假设、反复验证、最终交付可靠成果。它不再只是“照猫画虎”,而是真正具备了解决复杂工程问题的能力。
开放共享,技术普惠
此次发布的最大亮点之一,就是Kimi-Dev的全面开源。
月之暗面宣布,已向全球开发者公开模型权重(Model Weight)和源代码(Source Code),并承诺技术细节报告即将上线。
这意味着,这款具备顶尖能力的AI编程助手,现在任何人都可以免费使用、研究甚至二次开发。这不仅是一次技术释放,更是中国AI发展进程中的重要一步。
未来,月之暗面计划进一步拓展Kimi-Dev的能力边界,聚焦更复杂的工程任务。重点方向包括与主流IDE、版本控制系统(如Git)、以及CI/CD流水线的深度集成,使其能够无缝嵌入开发者的日常流程。
同时,团队将持续优化模型性能,加强安全性评估,并定期向社区推出更强大、更稳定的版本。