DragonV2.1是什么
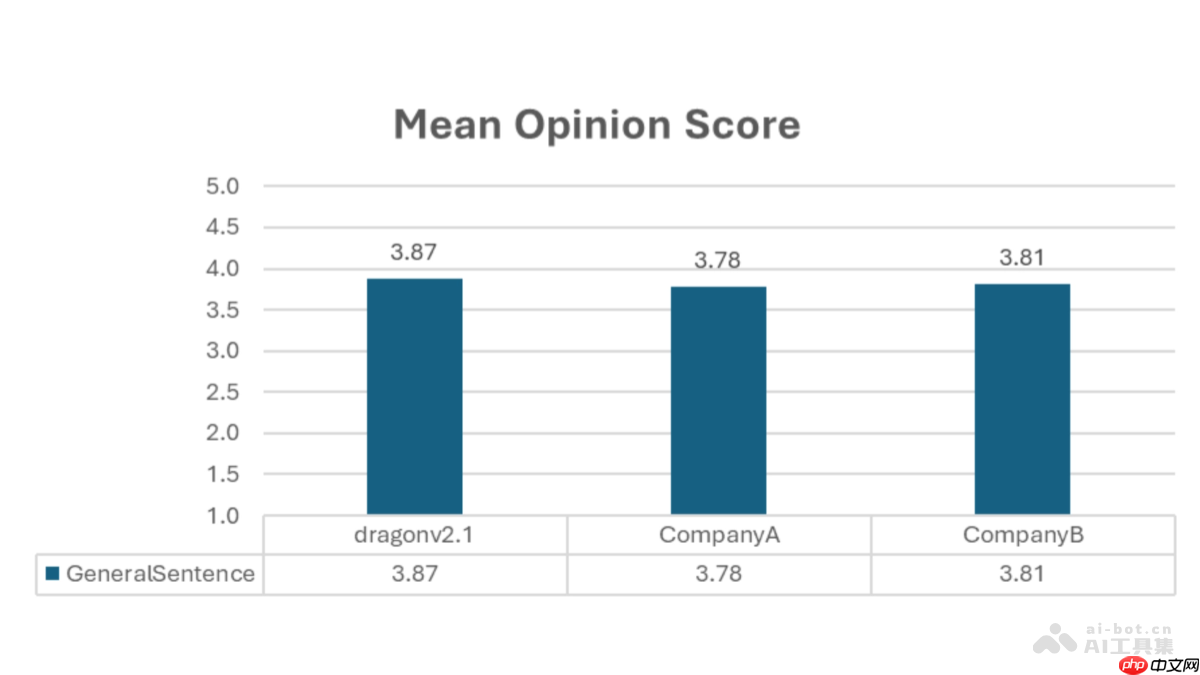
dragonv2.1(dragonv2.1neural)是微软最新发布的零样本文本转语音(tts)模型。该模型采用先进的 transformer 架构,具备多语言支持与零样本语音克隆能力,仅需 5 至 90 秒的语音样本即可生成高度自然且富有情感的语音内容。相比前代 dragonv1,dragonv2.1 在发音准确度、语音流畅性及控制灵活性方面均有显著提升,平均词错误率(wer)下降 12.8%。同时支持 ssml 音素标注和自定义词典功能,可精准调控发音细节与口音特征,并集成语音水印技术,保障合成语音的安全性与合规性。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
DragonV2.1的主要功能
-
多语言合成:兼容 100 多种 Azure TTS 语言环境,能够生成多种语言的高质量语音,满足全球化应用需求。
-
情感与口音适配:根据文本语境智能调整语调、情感和口音,使合成语音更具表现力与个性化特征。
-
零样本语音克隆:仅需短至 5 秒的语音输入,即可构建高保真的个性化 AI 声音,显著降低语音复制的技术门槛。
-
高效实时合成:语音生成延迟低于 300 毫秒,实时因子(RTF)小于 0.05,适用于对响应速度要求高的实时交互场景。
-
精细发音控制:支持在 SSML(语音合成标记语言)中使用音素标签,用户可通过国际音标(IPA)精确设定发音方式。
-
自定义词典功能:允许用户定义专有词汇或特殊术语的读音,提升专业领域语音输出的准确性。
-
多口音支持:可生成特定区域口音的语音,如英式英语(en-GB)、美式英语(en-US)等,增强语音本地化体验。
-
内置水印机制:自动在生成的语音中嵌入数字水印,有效识别合成内容,防止滥用与伪造风险。
DragonV2.1的技术原理
-
Transformer 架构:模型基于 Transformer 深度学习结构,利用自注意力机制(Self-Attention)处理文本与语音之间的长距离依赖关系,提升语音自然度与连贯性。
-
多头注意力机制:通过多组注意力头并行分析输入信息,使模型能从多个维度捕捉语音特征,增强表达能力。
-
SSML 深度集成:全面支持语音合成标记语言(SSML),包括音素标注与词典扩展功能,实现对语速、语调、重音等参数的精细调控。
DragonV2.1的项目地址
DragonV2.1的应用场景
-
视频内容制作:为视频提供多语种配音与实时字幕生成,复刻原声演员语调风格,提升跨语言观众的沉浸感。
-
智能客服系统:驱动聊天机器人和语音助手生成拟人化回复,支持多语言交互,优化服务体验并降低人力成本。
-
教育与语言培训:生成标准发音的多语言语音,辅助学习者练习听力与口语,提升在线教学的互动性与效率。
-
智能语音助手:应用于智能家居、车载系统等场景,提供流畅自然的多语言语音交互体验。
-
品牌声音塑造:为企业打造专属品牌语音,用于广告宣传与营销推广,强化品牌形象并拓展国际市场影响力。
以上就是DragonV2.1— 微软推出的零样本文本到语音模型的详细内容,更多请关注php中文网其它相关文章!











 444
444























