
阿里通义 qwen 团队通过 hugging face transformers 库的 pr 提交了对 qwen3-next 系列的支持,信息显示将有一款名为 qwen3-next-80b-a3b-instruct 的模型。该系列定位为 “下一代基础模型”,主打极端上下文长度与参数效率。
据介绍,Qwen3-Next 系列模型在架构层面引入了三项核心创新。首先是 Hybrid Attention,它使用 Gated DeltaNet 和 Gated Attention 替代传统注意力机制,以实现高效的长文本建模。其次是 High-Sparsity MoE,将激活比例压缩至 1:50,大幅减少了单个 token 的 FLOPs 而不损失模型容量。最后是 Multi-Token Prediction,在预训练阶段同步预测多个 token,从而提升性能并加速推理。
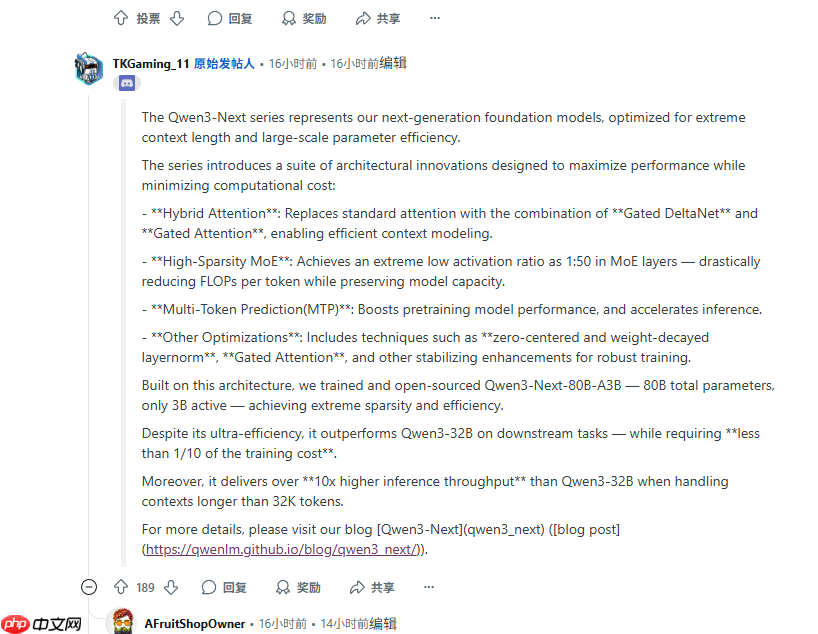
此外,模型还辅以 zero-centered、weight-decayed layernorm 等多项稳定化改进,增强了训练的鲁棒性。
源码地址:点击下载
以上就是阿里通义即将发布 Qwen3-Next 系列模型的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 196
196





















