
字节跳动Seed研究团队近日发布了一项名为 AgentGym-RL 的全新框架,旨在利用强化学习技术训练大型语言模型(LLM)代理,使其能够在多轮交互中做出高效决策。
该框架采用模块化与解耦设计,具备出色的灵活性和可扩展性,能够适配多种主流强化学习算法。AgentGym-RL 涵盖了多个贴近现实的应用场景,为代理在复杂环境中的决策能力提升提供了有力支持。
为进一步提升训练效率,研究团队创新性地提出了 ScalingInter-RL 训练策略。该方法通过分阶段增加交互步数,使代理在训练初期聚焦于掌握基础操作技能,随后逐步引入更长的交互序列,激发多样化的策略探索。这种动态平衡探索与利用的机制,显著增强了代理在处理高难度任务时的学习稳定性与适应能力。
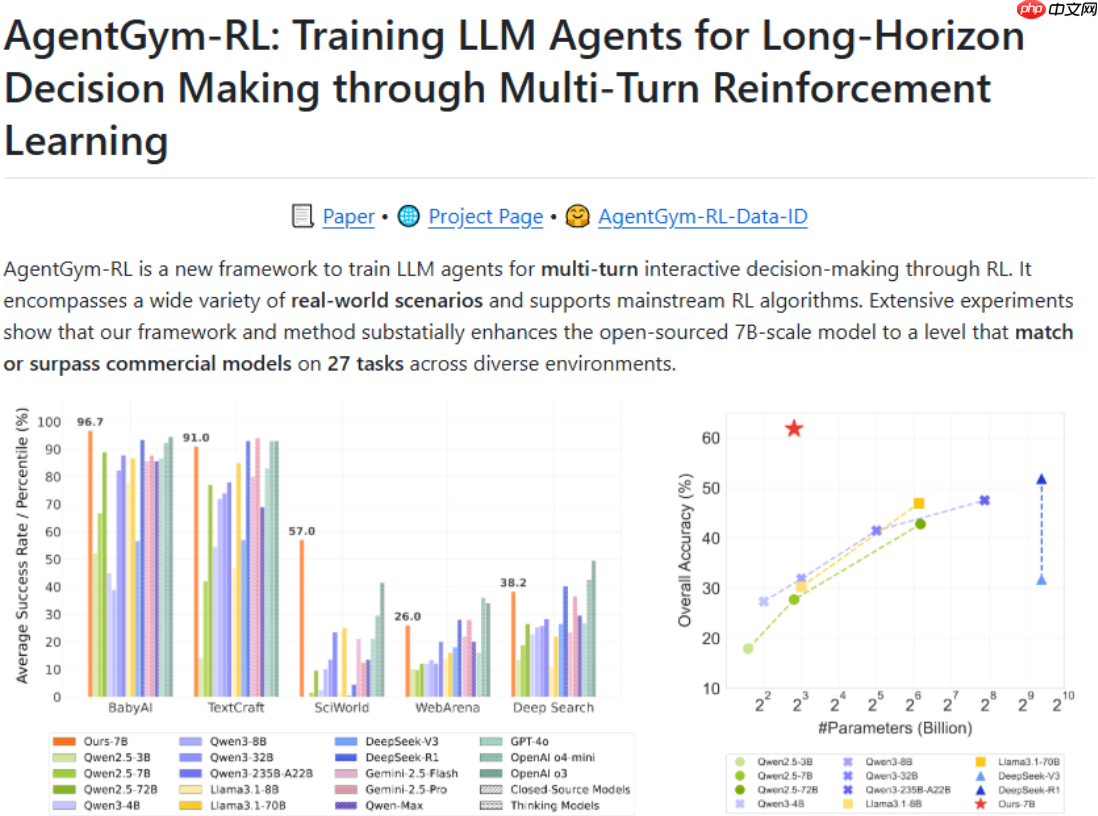
实验部分,研究人员选用 Qwen2.5-3B 和 Qwen2.5-7B 作为基础模型,在五个不同类别的任务场景下对 AgentGym-RL 与 ScalingInter-RL 进行评估。结果表明,基于该框架训练的代理在总共27项任务中超越了多个现有商业级模型的表现。
XDcms是南宁旭东网络科技有限公司推出的一套完全开源的通用的内容管理系统。主要使用php+mysql+smarty技术基础进行开发,XDcms采用OOP(面向对象)方式进行基础运行框架搭建。模块化开发方式做为功能开发形式。框架易于功能扩展,代码维护,二次开发能力优秀。 XDcms重点功能 A、内容管理模型,自定义字段,更方便扩展功能。自带模型:单页模型、新闻模型、产品模型、招聘模型 B、栏目自定
 0
0

值得一提的是,研究团队宣布将全面开源 AgentGym-RL 框架,包括其代码库和相关数据集,旨在推动智能代理领域的开放研究与协作发展。
AgentGym-RL 所涵盖的任务场景广泛,包括网页导航、深度信息检索、数字逻辑游戏、体感交互任务以及科学实验模拟等,要求代理具备高度的环境理解力、长期规划能力和持续决策水平,以应对真实世界中的复杂挑战。
以上就是字节 Seed 推出全新 AgentGym-RL 框架的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号





 271
271
























