
fastmtp 是腾讯自主研发的大语言模型(llm)推理加速技术,通过革新多标记预测(mtp)机制,采用共享权重的单一mtp头替代传统多个独立模块,融合语言感知词汇压缩与自蒸馏训练策略,显著提升llm推理效率。该技术在不牺牲输出质量的前提下,平均实现2.03倍的推理速度提升。fastmtp无需修改主干模型结构,具备良好的可集成性,适用于数学推导、代码生成等结构化生成任务,为大模型的高效部署提供了切实可行的技术路径。

系统优势: 1、 使用全新ASP.Net+c#和三层结构开发. 2、 可生成各类静态页面(html,htm,shtm,shtml和.aspx) 3、 管理后台风格模板自由选择,界面精美 4、 风格模板每月更新多套,还可按需定制 5、 独具的缓存技术加快网页浏览速度 6、 智能销售统计,图表分析 7、 集成国内各大统计系统 8、 多国语言支持,内置简体繁体和英语 9、 UTF-8编码,可使用于全球
 0
0

☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
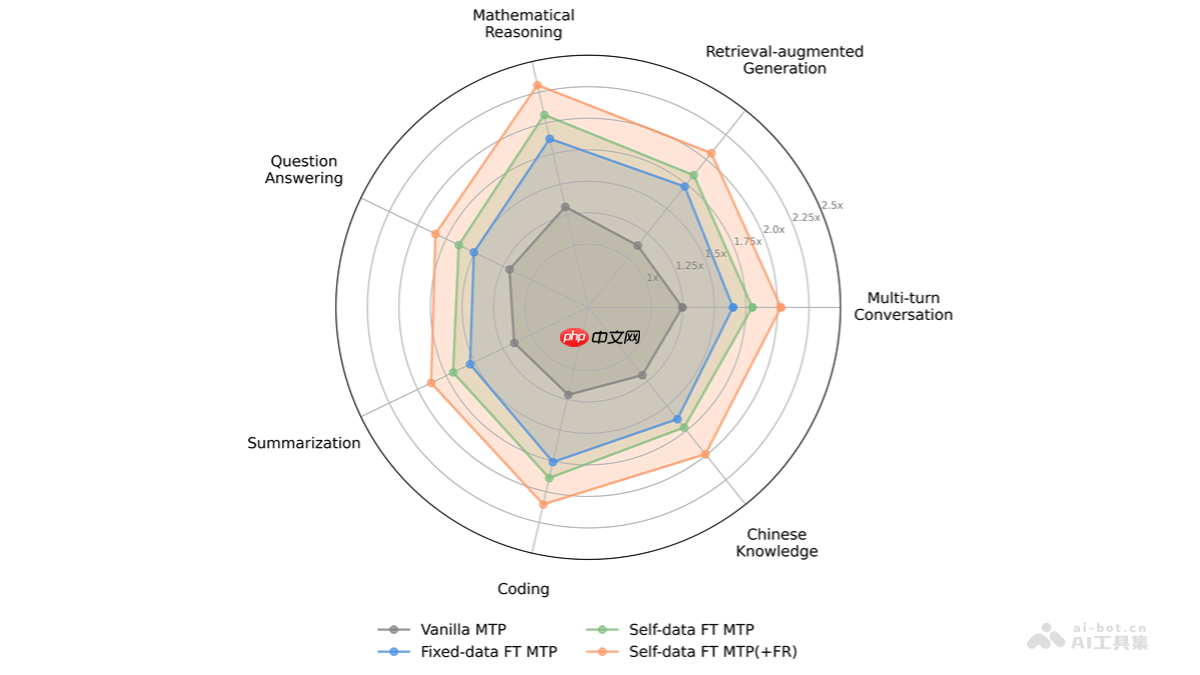
以上就是FastMTP— 腾讯开源的大语言模型推理加速技术的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号





 855
855
























