







1. 学习 flink 的原因
早在 18 年时,我便听说了
Flink这个流式计算引擎,当时阿里选择它作为新一代大数据计算框架,这一消息给我留下了深刻印象。
由于我平时主要从事业务开发,尚未系统学习
Flink,但今年随着数据量的快速增长,我们的架构师提出了通过数据加工和分析,获取更多指标性结果,为用户提供更有价值的业务。
因此,我们规划了如下的系统架构:
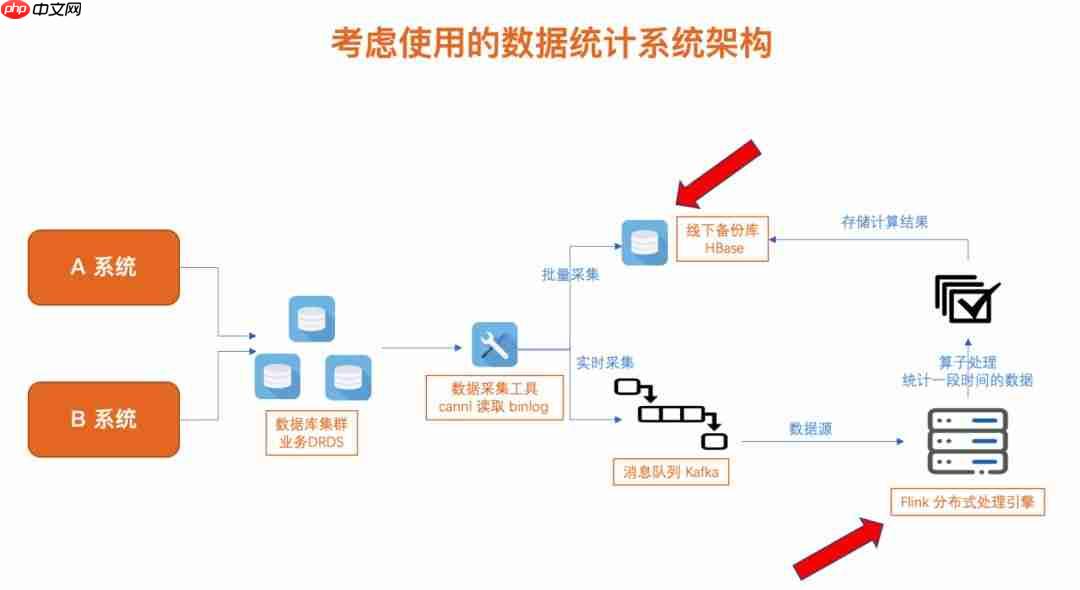 可以看出,业务数据库与数据分析系统已被分离,这样可以避免对核心业务的影响。数据分析的结果存储在线下备份库中,这样即使查询大量分析结果,也不会影响到核心业务。
可以看出,业务数据库与数据分析系统已被分离,这样可以避免对核心业务的影响。数据分析的结果存储在线下备份库中,这样即使查询大量分析结果,也不会影响到核心业务。
在数据处理方面,我们选择了
Flink作为分布式处理引擎。经过深入调研和学习,从它的描述、性能、接口编程和容错恢复等方面来看,它非常适合我们的场景。接下来,我将分享我的调研结果。
- 官网介绍
官网虽然有中文版的文档,但翻译并不完全,经常需要跳转到英文博文。这里推荐一个国内网站 https://www.php.cn/link/7da66e82dc1f8024527341be2df86b9f。
基础语义
基础语义非常重要,高层语法都是基于基础语义构建的,所以需要对它们有所了解。我推荐
ververica中的介绍:
- 流 Stream
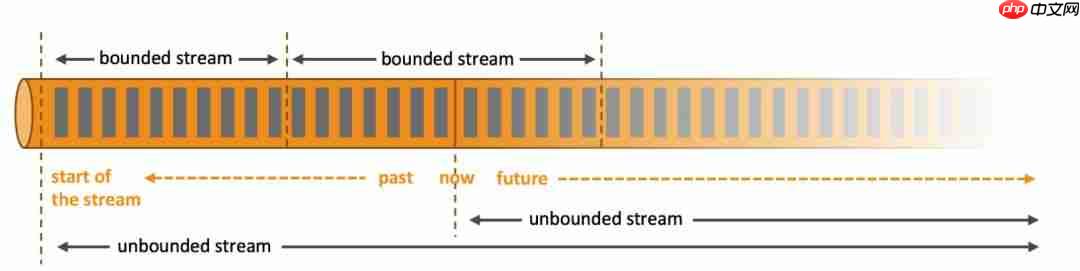 从上图可以看出,数据流分为有界(bounded)和无界(unbounded)两种。有界数据流大小固定,计算最终会完成并结束;无界数据流的数据会随着时间推移持续增加,计算会持续进行且没有结束的状态。
从上图可以看出,数据流分为有界(bounded)和无界(unbounded)两种。有界数据流大小固定,计算最终会完成并结束;无界数据流的数据会随着时间推移持续增加,计算会持续进行且没有结束的状态。
数据流还具有实时和历史记录的属性。实时处理是数据一生成就立即处理;如果时效性要求不高,可以在凌晨统计前一天的完整数据,将数据流持久化到存储系统中,然后进行批处理。
- 状态 State
状态是计算过程中保存的数据信息,在容错恢复和
Checkpoint中起到重要作用。流计算本质上是增量处理,因此需要不断查询和维护状态。为了保证
Exactly-once语义,还需要将数据写入到状态中,以确保在故障发生时,通过保存在状态中的数据进行恢复,保证一致性。持久化存储则可以在整个分布式系统运行失败或崩溃的情况下,实现
Exactly-once语义,这是状态的另一个重要价值。
- 时间 Time
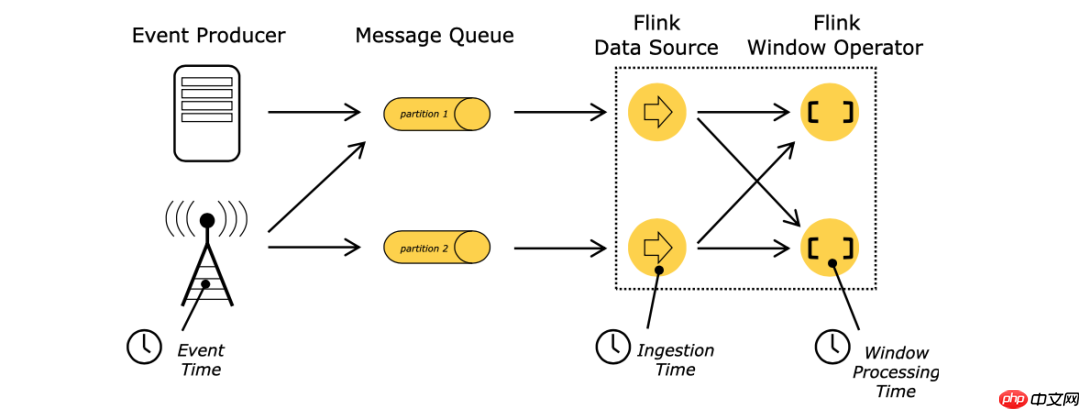
Flink时间分为事件时间(Event Time)、摄入时间(Ingestion Time)和处理时间(Processing Time)。对于无界数据流,时间是判断业务状态是否滞后的重要依据。
事件时间:指事件被处理的时间,由机器的系统时间决定。
处理时间:指事件发生的时间,通常由数据源携带的字段指明。
摄入时间:指数据进入
Flink的时间,在数据源处以操作时间作为时间戳。
三个时间的具体位置如上图所示,后续会详细讲解。
- 接口 API
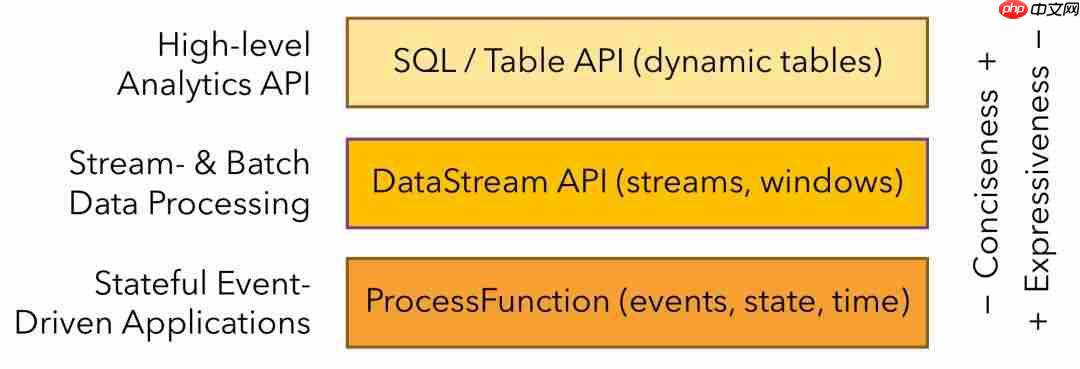 从上到下分为三层:
从上到下分为三层:
SQL/Table API、
DataStream API和
ProcessFunction。
API的表达能力和业务抽象能力都很强,但越接近
SQL层,表达能力会逐步减弱,抽象能力会增强(由于这是基础了解,所以没有深入学习
SQL API层,感兴趣的同学可以进一步探索)。
反之,
ProcessFunction层的
API表达能力非常强,可以进行多种灵活操作,但抽象能力相对较低。
通常,我们最常用的是中间层的
DataStream API,后续的学习也将围绕它展开。
架构介绍来源于 https://www.php.cn/link/45402d4ff8981a182dcfc4813600961f
 1. 有界和无界数据流
1. 有界和无界数据流
Flink具备统一处理有界和无界数据流的能力(流处理是无界的,批处理是有界的,给无界的流处理加上窗口
Window相当于有界的批处理,由于
API一致,算子可以复用)。
- 部署灵活
Flink底层支持多种资源调度器,包括
Yarn、
Kubernetes等。
Flink自带的
Standalone调度器在部署上也非常灵活(
Standalone也是本地开发常用的模式)。
- 极高的可伸缩性
对于分布式系统来说,可伸缩性非常重要。资源不足时可以动态添加节点,分担压力;资源充足时可以撤下服务器,减少资源浪费。阿里巴巴双 11 大屏使用
Flink处理海量数据,测得峰值可达 17 亿/秒。
- 极致的流式处理性能
Flink相较于
Storm的最大特点是将状态语义完全抽象到框架中,支持本地状态读取,避免了大量网络
IO,大大提升了状态存储的性能。
- 特性和优点
以上是对
Flink的定义和架构介绍,下面是更具体的信息。官网从【架构】、【应用】和【运维】三个方面进行了介绍。
这里不会深入分析,主要简单介绍它的特性和优点,提供一个大致的了解,逐步深入,在后续文章中进一步学习。
处理流程
Flink程序的基本构建块是流和转换。(请注意,
Flink的
DataSet API中使用的
DataSet也是内部流)从概念上讲,流是数据记录流(可能永无止境),而转换是将一个或多个流作为一个操作的操作。一个输入可以产生一个(例如
map)或多个输出流(例如
flatMap)。
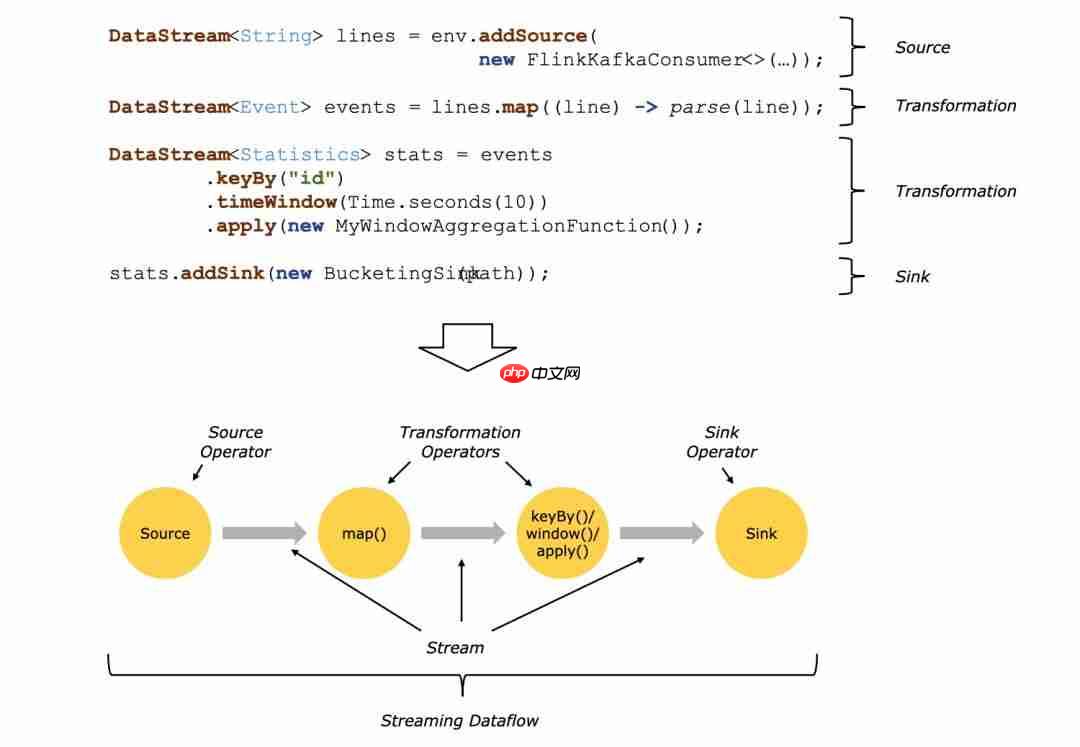 上图是数据处理流程,可以看到几个核心组件:
上图是数据处理流程,可以看到几个核心组件:
- 数据源 Source
自带的
API中,可以读取以下数据:集合数据(fromCollection)、文件数据(readFile)、网络套接字(socket)以及更多扩展来源(addSource)。更多扩展中可以通过自定义
RichSourceFunction实现读取更多来源的数据。
图中获取的数据源是
Kafka,与其他中间件整合中,也封装了许多方便的方法,调用它们可以更方便地获取数据源的数据。
- 转换 Transaction
进行数据的转化,对应于文档中的算子
Operator。常见的数据操作有以下:
map、
flatMap、
filter、
keyBy、
reduce、
fold(在 1.9 中被标注为
deprecated)、
aggregate、
Window等常用操作。
从上图也可以看出,转换的操作可以不止一次,多个算子可以形成
chain链式调用,然后发挥作用。
- 存储 Sink
进行数据的存储或发送,对应于文档中的
connector(既可以连接数据源,也能发送到某个地方存储起来)。

本文档主要讲述的是Sencha Touch快速入门2.0;Sencha Touch可以让你的Web App看起来像Native App。美丽的用户界面组件和丰富的数据管理,全部基于最新的HTML5和CSS3的 WEB标准,全面兼容Android和Apple iOS设备。希望本文档会给有需要的朋友带来帮助;感兴趣的朋友可以过来看看
常用的存储
sink有
Kafka、
Apache Cassandra、
Elasticsearch、
RabbitMQ、
Hadoop等。与前面一样,可以通过扩展
RichSinkFunction进行自定义存储的逻辑。
性能比较
例如与
Hadoop、
Storm或
Spark进行比较,对比性能的高低。如果选择使用
Flink,必须比以前的开发更方便且性能更好。
由于之前没有使用过这些大数据框架,所以测评数据可以参考以下两篇文章:
Flink实时计算性能分析 https://www.php.cn/link/9ce60c64ac4510df68537de96631261f Flink 与 Storm 的性能对比 https://www.php.cn/link/87e942236933558e0ea7cd7dee76e9db:
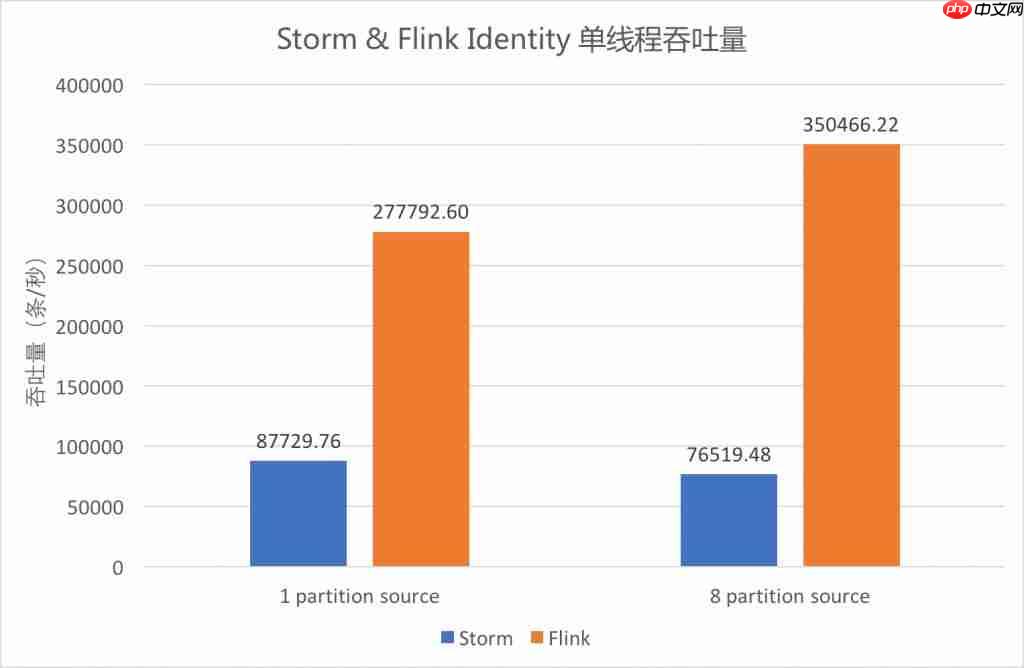 上图的数据源是
上图的数据源是
Kafka Source,蓝色是
Storm,橙色是
Flink。在一个分区
partition情况下,
Flink的吞吐量约为
Storm的 3.2 倍;而在 8 个分区情况下,性能提高到 4.6 倍。
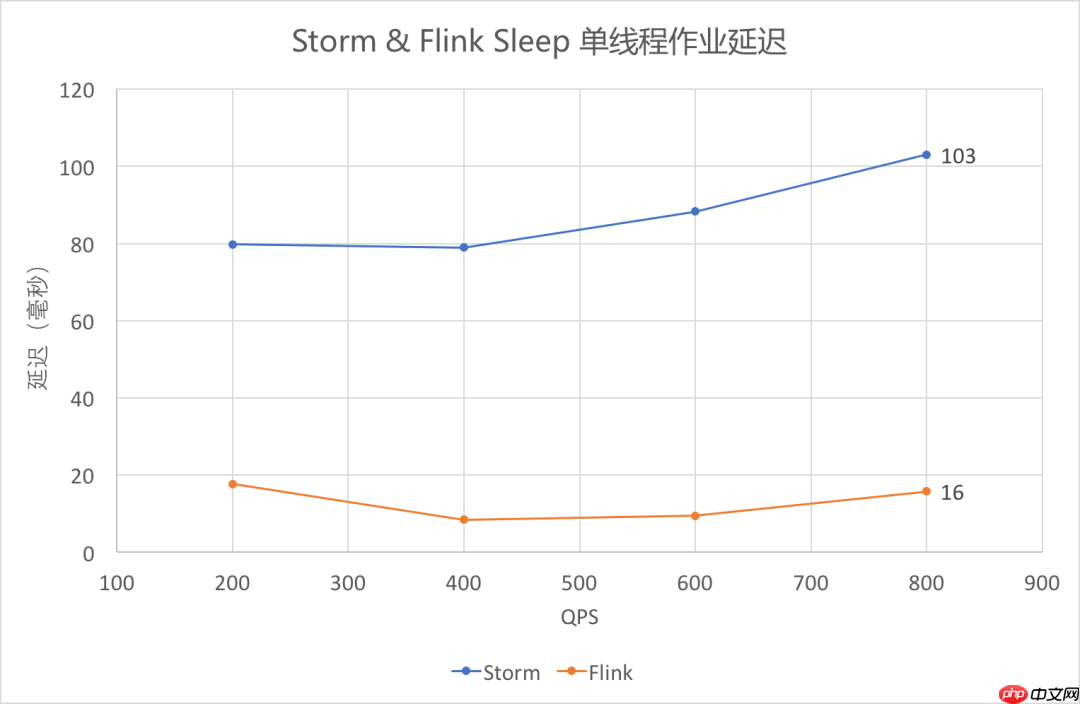 上图采用
上图采用
outTime-eventTime作为延迟,可以看出,
Flink的延迟还是比
Storm的要低。
管理方式 JobManager、TaskWorker
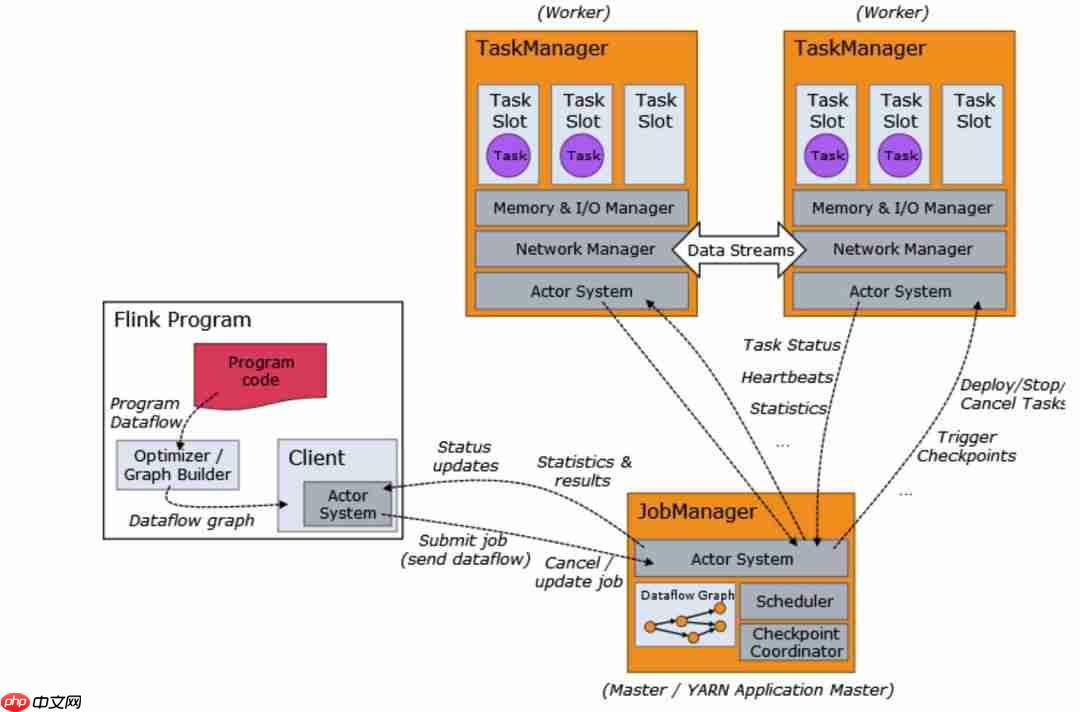 上面是官方示意图,阐述了
上面是官方示意图,阐述了
Flink提交作业的流程,应用程序
Flink Program、
JobManager和
TaskManager之间的关系。
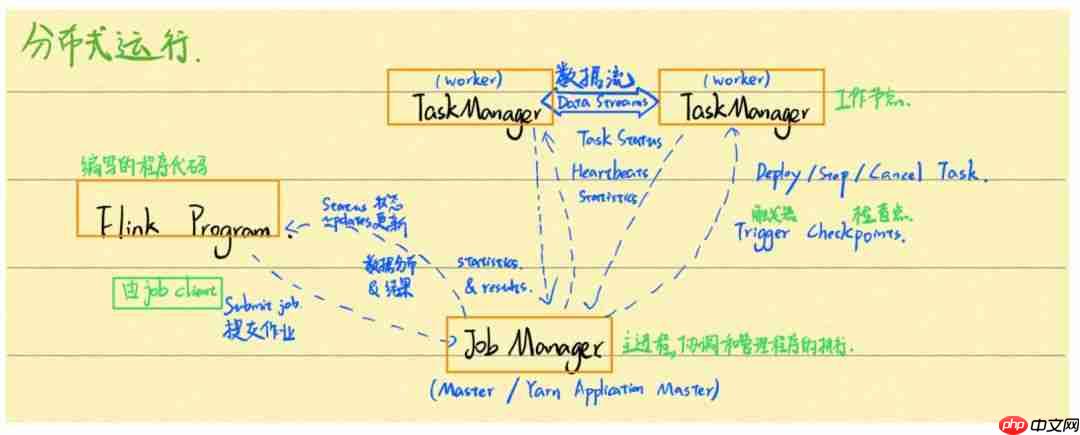 上面是我对它的理解,我个人认为
上面是我对它的理解,我个人认为
zhisheng大佬写的更加详细,可以参考这篇文章:https://www.php.cn/link/c3a05fe072d3d4f009eccce97c41ca71
高可用 HA、状态恢复
High Availability是个老生常谈的话题了,服务难免会遇到无法预测的意外,如何在出现异常情况下快速恢复,继续处理之前的数据,保证一致性,这是个考量服务稳定性的标准。
Flink提供了丰富的状态访问(例如有
List、
map、
aggregate等数据类型),以及高效的容错机制,通过存储状态
State,然后通过存储了状态的
Checkpoint和
Savepoint来帮助应用进行快速恢复。
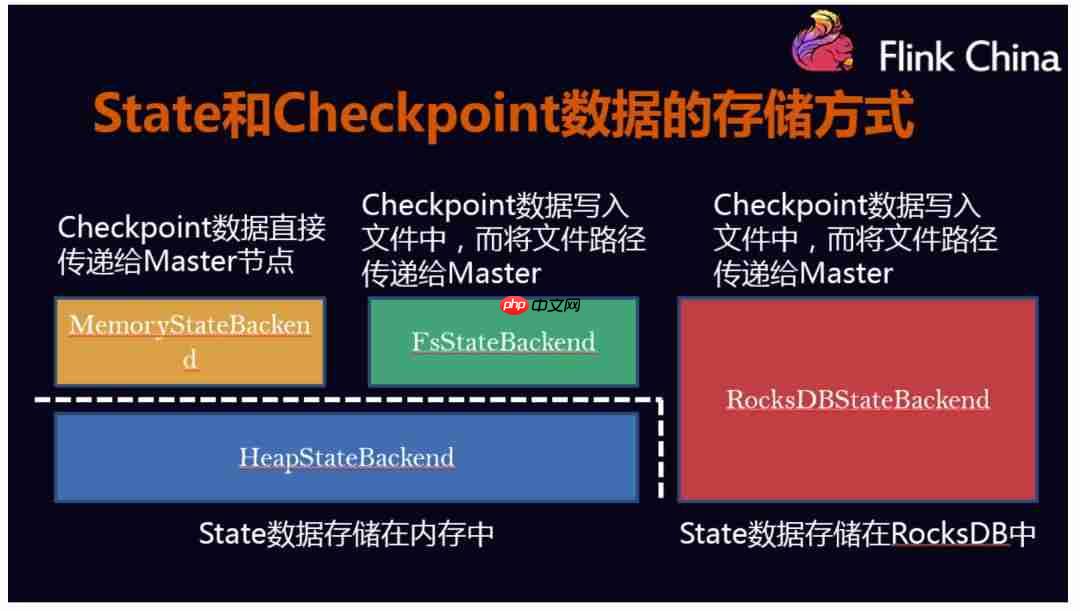 详细请参考这两篇:
详细请参考这两篇:
Apache Flink 零基础入门(七):状态管理及容错机制 https://www.php.cn/link/a1280bb57e980da66d54eb0f20cbb95e Flink状态管理和容错机制介绍 https://www.php.cn/link/c72741e550f08085fefee77a99d9ccb3
真的是非常敬仰发明优秀框架的团队,也非常敬佩每一个为技术做贡献的参与者,所以每次找到相关的资料都跟发现宝藏一样。
下面罗列一下目前找到的资料:
Flink官网:https://www.php.cn/link/c323092e3dc96ec44049c28c7dd27089
国内牛人的分享:https://ververica.cnGithub 项目
可以关注一下提的问题和阿里分支Blink
:https://github.com/apache/flinkzhisheng
个人学习的流程是跟着他的文章走了一遍,然后遇到不懂的继续深入学习和了解:http://www.54tianzhisheng.cn/tags/Flink/wuchong
这位大佬是从 16 年就开始研究Flink
,写的文章很有深度,想要详细了解Flink
,一定要看他的文章!:http://wuchong.me/categories/Flink/从上面的资料可以看出,Flink` 的社区慢慢从小众走向大众,越来越多人参与。
基础知识点
运行环境如下:
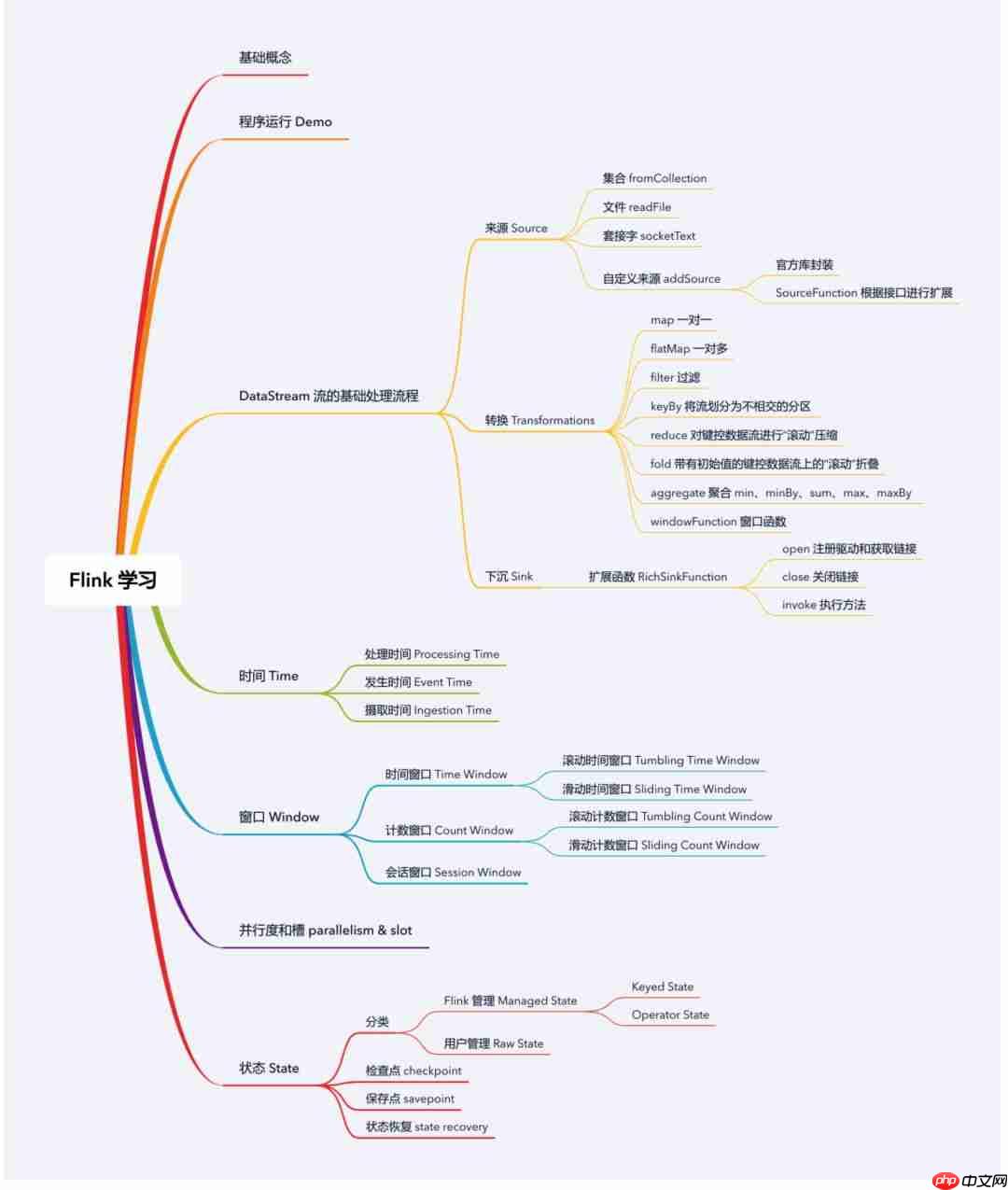 上图是我在学习过程中整理的一些知识点,之后将会根据罗列的知识点慢慢进行梳理和记录。
上图是我在学习过程中整理的一些知识点,之后将会根据罗列的知识点慢慢进行梳理和记录。
- 总结:未来的计算方式
从调研的结果中可以看出,无论从性能、接口编程和容错上,
Flink都是一个不错的计算引擎。
github上拥有 1 万多个
star,这么多人支持以及阿里巴巴的大力推广,还有在 2019.09 参加的云栖大会,演讲嘉宾对
Flink的展望:
 Apache Flink 已经是非常优秀和成熟的流计算引擎
Apache Flink 已经是非常优秀和成熟的流计算引擎
Apache Flink 已经成为优秀的批处理引擎的挑战者
继续挖掘 Apache Flink 在 OLAP 数据分析领域的潜力,使其成为优秀的数据分析引擎
直觉相信,
Flink的发展前景不错,希望接下来与大家分享和更好的去学习它。
参考资料
Flink 从 0 到 1 学习 —— Apache Flink 介绍
Apache Flink 是什么?
Apache Flink 零基础入门(一&二):基础概念解析
为什么说流处理即未来?
Apache Flink 零基础入门(七):状态管理及容错机制
Apache Flink状态管理和容错机制介绍




























