DeepSeek-R1-Safe 是什么
由浙江大学网络空间安全学院与华为联合研发,deepseek-r1-safe 是基于 deepseek 模型衍生出的专注于安全能力的大语言模型。该模型依托华为昇腾ai芯片及 mindspeedllm 训练框架,通过构建专业级安全语料库、实施安全监督训练以及强化学习优化等关键技术路径,全面增强模型在内容安全与合规性方面的表现。项目已开源完整权重,支持自由用于安全相关的训练、微调与测试任务,广泛适用于对安全性要求极高的应用场景,如网络安全防护、敏感数据处理等领域。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
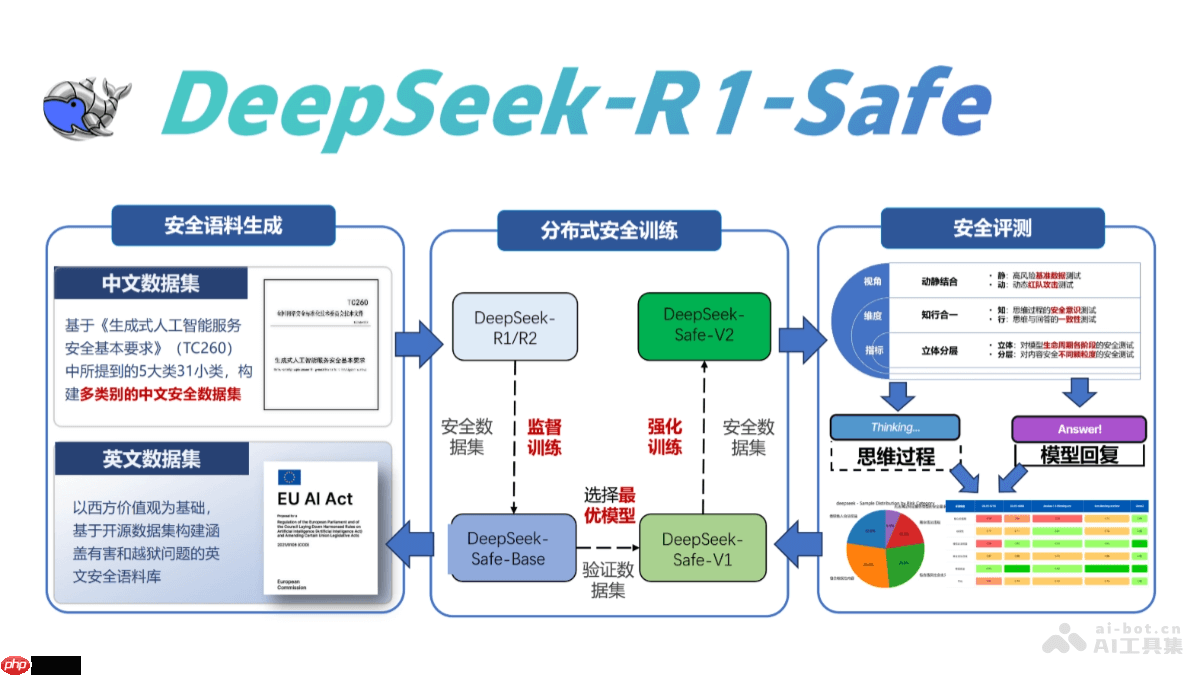
DeepSeek-R1-Safe 的核心功能
-
高效安全防御机制:具备识别并抵御多种类型有害信息和越狱攻击的能力,防御成功率高,显著提升系统整体安全性。
-
通用性能无损保持:在大幅增强安全能力的同时,最大限度保留原始模型的通用理解与生成能力,实现安全与性能的协同优化。
-
深度安全训练流程:采用安全监督学习与多维强化学习技术,引导模型建立风险识别意识,并能进行合规性推理,增强其鲁棒性和可信赖性。
-
高质量安全语料支撑:构建覆盖多类风险场景的专业语料体系,引入“风险问题—安全思维链—合规回答”三元结构,为模型注入主动判断与响应能力。
DeepSeek-R1-Safe 的技术实现原理
-
端到端安全训练架构:打造从数据构建、训练优化到软硬件协同部署的全链条自主可控训练体系,将安全逻辑深度嵌入模型的认知过程和输出行为中。
-
多维度安全语料建设:系统整合全球13个国家共24项法律法规要求,建立涵盖14类主要风险类型的评测基准。设计结构化三元组语料(风险输入-思维链-安全回复),显式植入安全推理路径,并融合前沿越狱攻击样本以提升抗诱导能力。
-
创新安全训练方法论:
-
预对齐安全思维模式:在训练初期提取安全语料中的核心认知模式,提前与模型内部表征结构对齐,实现快速安全导向。
-
动态感知补偿机制:利用代表性非敏感数据集微调非安全相关参数,精准恢复因安全约束导致的性能下降。
-
多维可验证强化学习:构建细粒度、多维度的安全奖励体系,结合性能与安全的帕累托最优策略,使模型在复杂对抗环境中自主平衡安全性与实用性。
DeepSeek-R1-Safe 的项目地址
DeepSeek-R1-Safe 的典型应用场景
-
网络内容治理:可用于实时检测和拦截网络平台中的违法不良信息,助力营造清朗的网络空间。
-
数据隐私与合规管理:在数据处理流程中确保符合监管要求,防止敏感信息泄露或被不当使用。
-
自动化内容审核:应用于社交媒体、新闻资讯、论坛等平台的内容审查,自动识别违规文本,提高审核效率与一致性。
-
智能对话系统安全保障:为客服机器人、虚拟助手等提供安全可控的语言生成能力,避免输出误导性或不合规内容。
-
金融领域风险识别:支持在金融业务中识别欺诈话术、异常交易描述等高风险内容,提升风控系统的智能化水平。
以上就是DeepSeek-R1-Safe— 浙大联合华为推出的安全大模型的详细内容,更多请关注php中文网其它相关文章!


 广告
广告








 231
231
























