







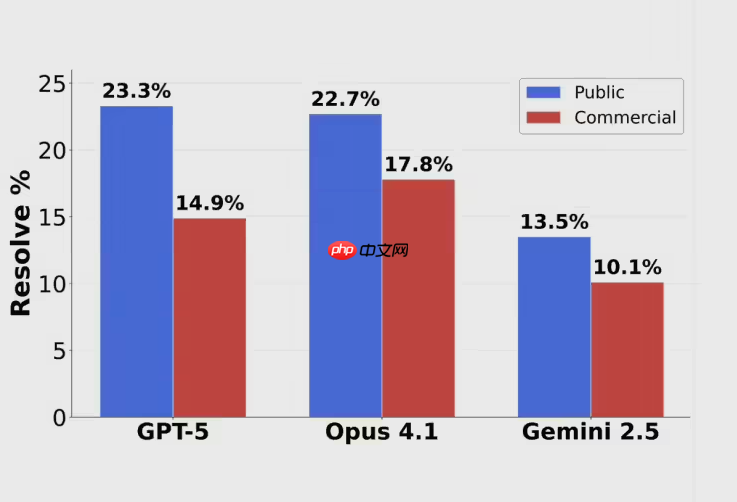
AI三巨头集体受挫:在Scale AI最新推出的SWE-BENCH PRO编程测评中,GPT-5、Claude Opus 4.1与Gemini 2.5均未能突破25%的解决率门槛,遭遇了前所未有的挑战。GPT-5以23.3%的成绩位列第一,Claude Opus 4.1紧随其后为22.7%,而Google Gemini 2.5则仅得13.5%,表现低迷。
这一结果震动业界,似乎揭示出当前顶尖大模型在真实复杂编程任务面前仍显乏力。然而,深入数据背后,故事远非表面那般简单。

前OpenAI研究员Neil Chowdhury指出,若仅统计模型实际提交的任务,GPT-5的准确率高达63%,几乎是Claude Opus 4.1同期31%的两倍。这说明,在它决定介入的问题上,GPT-5依然具备强大实力。相比之下,其他模型不仅整体得分低,且在已尝试任务中的成功率也明显落后。
问题的关键在于——SWE-BENCH PRO本身就是一场“地狱级”考验。该测试集由OpenAI于2024年8月发布,旨在彻底规避传统基准的数据污染风险。不同于旧版SWE-Bench-Verified中大量存在的一两行简单修改题(500题中有161题属此类),SWE-BENCH PRO聚焦工业级现实场景,涵盖跨文件、多模块、数百行代码变更的真实项目难题。
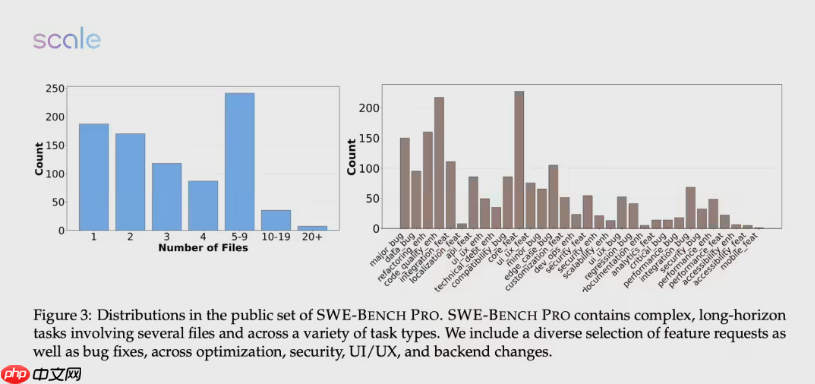

测试库包含1865个来自商业应用、B2B服务和开发者工具的多样化问题,并特别设置保留集,使用活跃的开源代码库防止过拟合。同时引入人工增强机制,确保任务复杂度逼近真实开发环境。正是这种严苛设计,使得以往“刷榜式”的优化策略失效,迫使模型展现真正的工程理解能力。
更引人深思的是GPT-5高达63.1%的未回答率。这意味着超过六成的任务,模型选择不作答,而非冒险出错。这种高度保守的行为反映出先进AI系统正具备某种形式的自我判断力,但也暴露了其泛化能力的局限。
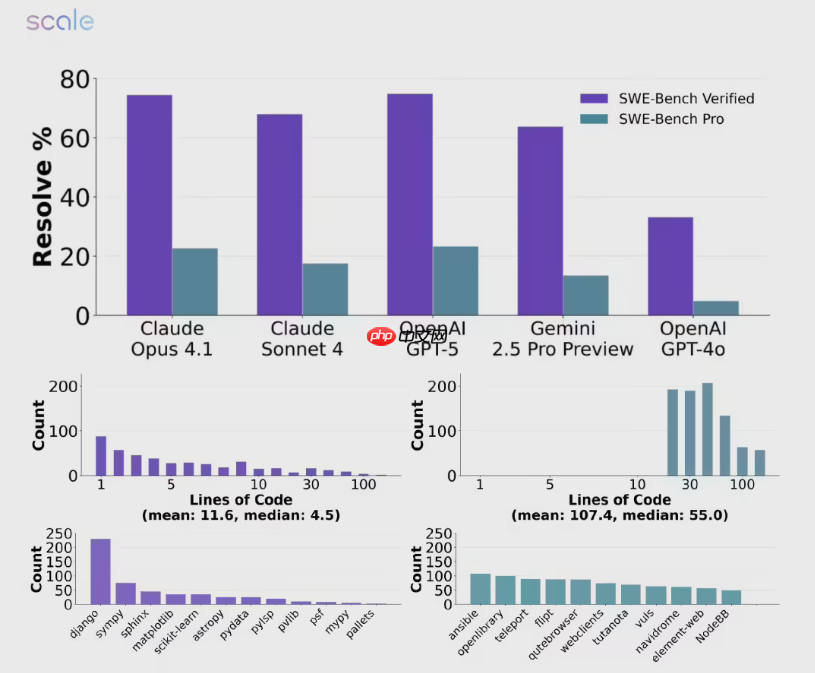
尤其在JavaScript和TypeScript等主流语言上,各模型表现波动剧烈,显示出技术路线差异带来的不均衡性。这场测评不仅是对模型能力的检验,更是对整个AI评估体系的反思:当旧基准逐渐饱和,唯有像SWE-BENCH PRO这样贴近实战的新标准,才能真正推动技术向实用化迈进。





























