Qwen3-TTS-Flash是什么
qwen3-tts-flash 是由阿里通义实验室推出的最新一代语音合成模型,具备多音色、多语言与多方言支持能力,是当前tts技术的旗舰级成果。该模型在中英文语音稳定性方面表现卓越,拥有出色的多语言合成能力以及高度拟人化的音色表现力。提供多达17种可选音色,每种音色均能流畅支持10种语言,并兼容普通话、粤语、闽南语等多种方言。模型可根据输入文本智能调整语调和情感,对复杂或不规范文本具有强大鲁棒性,语音生成速度快,首包延迟最低可达97ms。目前可通过qwen api进行调用,为用户带来自然、生动且富有表现力的语音合成体验。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

Qwen3-TTS-Flash的主要功能
-
丰富音色选择:支持17种不同风格的音色,每种音色均可跨语言使用,满足多样化场景下的个性化需求。
-
广泛语言覆盖:涵盖普通话、英语、法语、德语、俄语、意大利语、西班牙语、葡萄牙语、日语、韩语等主流语言,同时支持闽南语、吴语、粤语、四川话、北京话、南京话、天津话、陕西话等地方方言。
-
情感化表达:语音输出自然流畅,富有情感色彩,能够根据上下文自动调节语气语调,增强听觉感染力。
-
强文本适应能力:可有效处理标点混乱、格式复杂或含有专业术语的文本,自动提取关键信息并正确朗读。
-
低延迟高效率:语音生成响应迅速,首包延迟低至97ms,适用于实时交互场景,显著提升用户体验。
-
跨语言音色一致性:在不同语言间保持高度一致的音色特征,确保多语种播报时的声音连贯性和辨识度,优于同类竞品。
Qwen3-TTS-Flash的技术原理
-
深度神经网络架构:
-
文本编码模块:将输入文本转化为深层语义向量,精准捕捉词汇、语法及上下文语义信息。
-
语音解码模块:基于语义表示逐帧生成高质量语音波形,保障语音的自然度与节奏感。
-
注意力机制优化:采用先进的对齐算法,实现文本与语音帧之间的精确匹配,提升发音准确率和语句流畅性。
-
多语言多方言训练策略:模型在涵盖多种语言和方言的大规模语音数据集上进行联合训练,学习各语种特有的发音规律与韵律特征;结合音色嵌入(Speaker Embedding)技术,实现同一音色在不同语言间的无缝切换。
-
高鲁棒性设计:通过前端文本预处理系统完成分词、词性识别、数字单位转换等操作,增强模型对异常输入的容错能力,确保复杂文本也能被准确理解和朗读。
Qwen3-TTS-Flash的性能表现
-
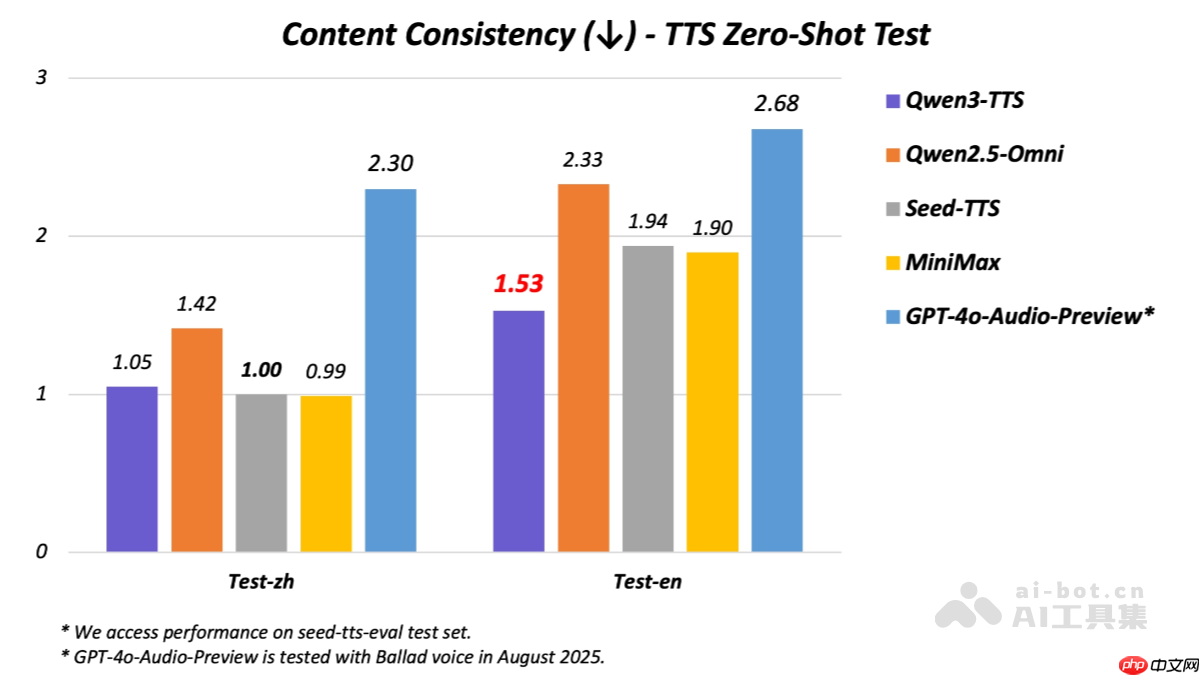
中英文稳定性领先:在seed-tts-eval测试集上,Qwen3-TTS-Flash的中英文语音稳定性达到行业顶尖水平(SOTA),优于SeedTTS、MiniMax及GPT-4o-Audio-Preview等主流模型。
-
多语言WER优势明显:于MiniMax TTS多语言测试集中,其在中文、英文、意大利语和法语上的词错误率(WER)均为最低,显著优于MiniMax、ElevenLabs和GPT-4o-Audio-Preview。
-
音色相似度卓越:在英文、意大利语和法语的说话人相似度评测中,Qwen3-TTS-Flash表现超越多个国际先进模型,展现出更强的音色还原能力和跨语言一致性。
 Qwen3-TTS-Flash的项目地址
Qwen3-TTS-Flash的项目地址
Qwen3-TTS-Flash的应用场景
-
智能客服系统:为自动化服务提供拟人化语音回复,提升用户沟通体验,如自动应答、业务引导等。
-
有声内容创作:将书籍、新闻、课件等内容转化为高质量音频,广泛应用于有声书、播客、知识付费等领域。
-
语音助手集成:赋能智能家居、可穿戴设备等终端,实现高效语音交互,方便用户语音操控设备。
-
语言教学辅助:为教育平台提供标准、多样化的语音讲解,助力学生进行听力训练与口语模仿。
-
数字娱乐制作:服务于动画配音、游戏角色语音、影视旁白等场景,打造更具沉浸感的声音体验。
以上就是Qwen3-TTS-Flash— 阿里通义推出的文本转语音模型的详细内容,更多请关注php中文网其它相关文章!



 广告
广告







 294
294
























