







近日,苹果公司公布了一项关于图像处理技术的最新研究成果,推出了一款名为manzano的全新图像模型。这一动向被广泛解读为苹果在生成式ai赛道上加速布局,意在与openai、谷歌等领军企业展开正面竞争的重要举措。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

Manzano的核心创新在于成功整合了图像理解与图像生成两大功能。目前多数开源模型在这两项能力之间难以兼顾,往往只能侧重其一,而主流商业闭源系统则普遍具备双优表现。苹果的研究指出,Manzano通过独特架构设计,有效缩小了这一差距,在运行效率和输出质量方面已可媲美GPT-4o以及谷歌的先进图像技术。

虽然苹果尚未正式发布Manzano,也未上线公开演示平台,但研究团队发布的论文及附带的低分辨率示例图像,已初步展现了该模型的强大潜力。面对复杂或高难度的文本提示,其生成结果在视觉质量和语义准确性上,与GPT-4o和谷歌Nano Banana模型的表现相当接近。

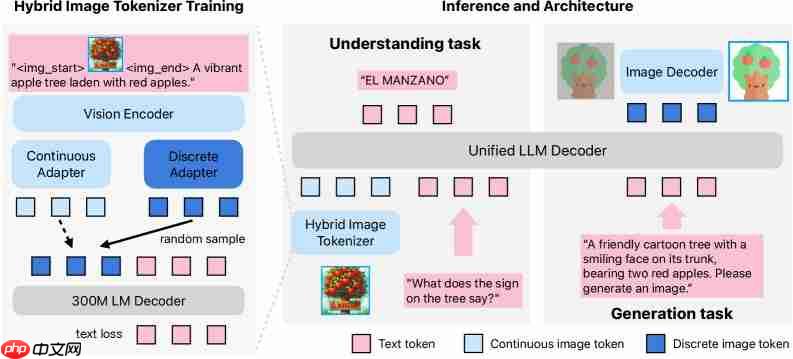
推动Manzano实现性能突破的关键,是其采用的一种新型混合图像标记器。该设计允许模型从同一编码器中同时生成两类标记:一类为连续标记,以浮点数形式用于精确的图像内容理解;另一类为离散标记,归类明确,专用于图像重建与生成。这种统一编码机制有效避免了传统多模块系统中存在的结构冲突和信息衰减问题。


从整体架构来看,Manzano由三个核心组件构成:混合分词器、统一的语言模型主干,以及一个独立负责图像输出的解码器。为适配多样化的应用场景,苹果还开发了三种不同规模的图像解码器,参数量分别为9000万、1.75亿和3.52亿,支持从256×256到2048×2048像素范围内的多种分辨率输出。
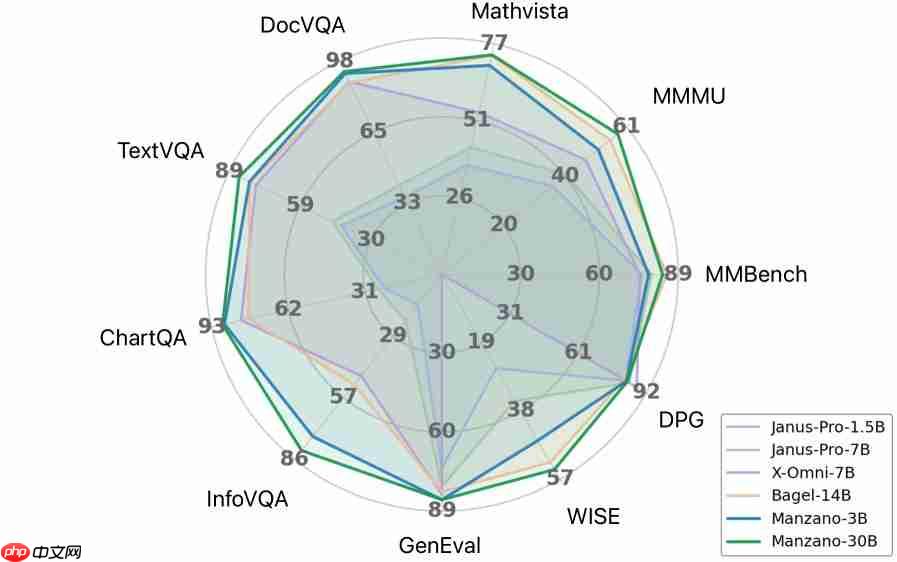
实测数据充分验证了Manzano架构的高效性。在多项权威基准测试中,该模型均取得了优异成绩。尤其在涉及文字识别与图文匹配的复杂任务中,其30亿参数版本表现尤为抢眼。研究还发现,随着模型参数从3亿逐步扩展至30亿,各项性能指标均呈现稳定且显著的增长趋势。
除了常规的图像编辑功能外,Manzano还能胜任更复杂的高级任务,例如基于自然语言指令进行图像内容修改、实现艺术风格转换、智能补全缺失区域、无限扩展画面边界,甚至可估算场景的深度信息。
苹果方面表示,Manzano不仅有望成为当前主流图像模型的有力替代者,其模块化、一体化的设计理念,也可能为未来多模态AI的发展提供新的技术范式,标志着人工智能正迈向一个更高集成度与效率的新阶段。





























