







- 引言
对抗训练(adversarial training)是一种增强神经网络鲁棒性的有效方法。在对抗训练过程中,样本会加入微小的扰动(虽然改变很小,但可能导致误分类),以使神经网络适应这些变化,从而增强对对抗样本的抵抗力。
在图像领域,采用对抗训练通常可以提高模型的鲁棒性,但往往会降低其泛化能力,即虽然对抗样本的抵抗力增强了,但可能影响到普通样本的分类性能。然而,在语言模型领域却观察到不同的现象——对抗训练不仅提升了鲁棒性,还增强了泛化能力。因此,对抗训练仍值得进一步研究,因为它确实能提升模型的性能。
首先,我们来探讨对抗训练的一般原理。对抗训练可以概括为以下最大最小化公式:
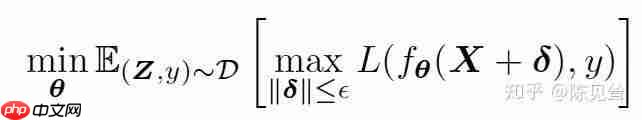
 2. FGSM/FGM方法
2. FGSM/FGM方法 3. PGD方法
3. PGD方法 4. FreeAT(Free Adversarial Training)在PGD的计算过程中,每次进行前向和后向计算时,无论是参数的梯度还是输出的梯度都会被计算出来。然而,在梯度下降过程中只使用参数的梯度,而在梯度提升过程中只使用输入的梯度,这实际上是一种浪费。我们能否在一次前向后向计算中同时利用参数的梯度和输入的梯度?这就是FreeAT[4]文章的核心思想。
4. FreeAT(Free Adversarial Training)在PGD的计算过程中,每次进行前向和后向计算时,无论是参数的梯度还是输出的梯度都会被计算出来。然而,在梯度下降过程中只使用参数的梯度,而在梯度提升过程中只使用输入的梯度,这实际上是一种浪费。我们能否在一次前向后向计算中同时利用参数的梯度和输入的梯度?这就是FreeAT[4]文章的核心思想。
具体如何实现呢?这里有一个小问题,即普通训练与PGD对抗训练的方式略有不同。普通训练中相邻的batch是不同的,而PGD对抗训练在计算梯度提升时,需要对同一个mini-batch的样本反复求梯度。FreeAT仍然采用PGD这种训练方式,即对于每个mini-batch的样本会求K次梯度,每次求得的梯度既用来更新扰动,也用来更新参数。原始的PGD训练方法,每次内层计算只用梯度来更新扰动,等K步走完后才重新计算一次梯度,更新参数。这种不同可以通过下图形象地表示。
 需要注意的是,如果内层进行K次迭代,对于外层计算,FreeAT会将总体的迭代epoch除以K,以保证总体的梯度计算次数与普通训练相同。从外层训练的角度来看,每个mini-batch被训练的次数与普通训练相同,只是训练顺序有所变化,K个相同的mini-batch会被顺序训练。这样做带来的问题是连续相同的mini-batch对参数更新的扰动不如随机mini-batch大,这可能影响模型最终的收敛效果。但论文通过实验证明,这种担忧是多余的。详细的算法代码如下:
需要注意的是,如果内层进行K次迭代,对于外层计算,FreeAT会将总体的迭代epoch除以K,以保证总体的梯度计算次数与普通训练相同。从外层训练的角度来看,每个mini-batch被训练的次数与普通训练相同,只是训练顺序有所变化,K个相同的mini-batch会被顺序训练。这样做带来的问题是连续相同的mini-batch对参数更新的扰动不如随机mini-batch大,这可能影响模型最终的收敛效果。但论文通过实验证明,这种担忧是多余的。详细的算法代码如下:
 5. YOPO(You can Only Propagate Once)YOPO[5]的出发点是利用神经网络的结构来减少梯度计算的计算量。从PMP(Pontryagin's maximum principle)的角度来看,对抗扰动只与神经网络的第一层有关。因此,论文提出固定前面的基层,只对第一层求梯度,并据此来更新扰动。
5. YOPO(You can Only Propagate Once)YOPO[5]的出发点是利用神经网络的结构来减少梯度计算的计算量。从PMP(Pontryagin's maximum principle)的角度来看,对抗扰动只与神经网络的第一层有关。因此,论文提出固定前面的基层,只对第一层求梯度,并据此来更新扰动。
基于这一想法,作者考虑复用后几层的梯度,假设p为定值:
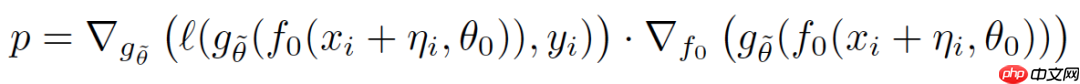 则对扰动的更新可以变为:
则对扰动的更新可以变为:

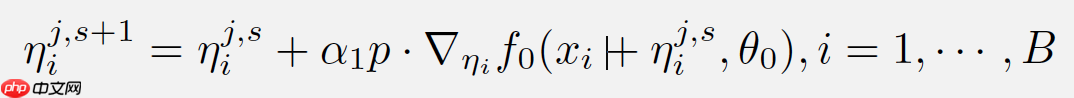 详细的算法代码如下:
详细的算法代码如下:
 尽管YOPO-m-n只完成了m次完整的正反向传播,但却实现了mn次扰动的更新。而PGD-r算法完成r次完整的正反向传播只能实现r次扰动的更新。从这个角度看,YOPO-m-n算法的效率明显更高,而实验也表明,只要使得mn略大于r,YOPO-m-n的效果就能与PGD-r相媲美。
尽管YOPO-m-n只完成了m次完整的正反向传播,但却实现了mn次扰动的更新。而PGD-r算法完成r次完整的正反向传播只能实现r次扰动的更新。从这个角度看,YOPO-m-n算法的效率明显更高,而实验也表明,只要使得mn略大于r,YOPO-m-n的效果就能与PGD-r相媲美。
- FreeLB(Free Large Batch Adversarial Training)

 7. 参考文献[1] EXPLAINING AND HARNESSING ADVERSARIAL EXAMPLES
7. 参考文献[1] EXPLAINING AND HARNESSING ADVERSARIAL EXAMPLES
[2] ADVERSARIAL TRAINING METHODS FOR SEMI-SUPERVISED TEXT CLASSIFICATION
[3] Towards Deep Learning Models Resistant to Adversarial Attacks
[4] Adversarial Training for Free!
[5] You Only Propagate Once: Accelerating Adversarial Training via Maximal Principle
[6] FREELB: ENHANCED ADVERSARIAL TRAINING FOR NATURAL LANGUAGE UNDERSTANDING




























