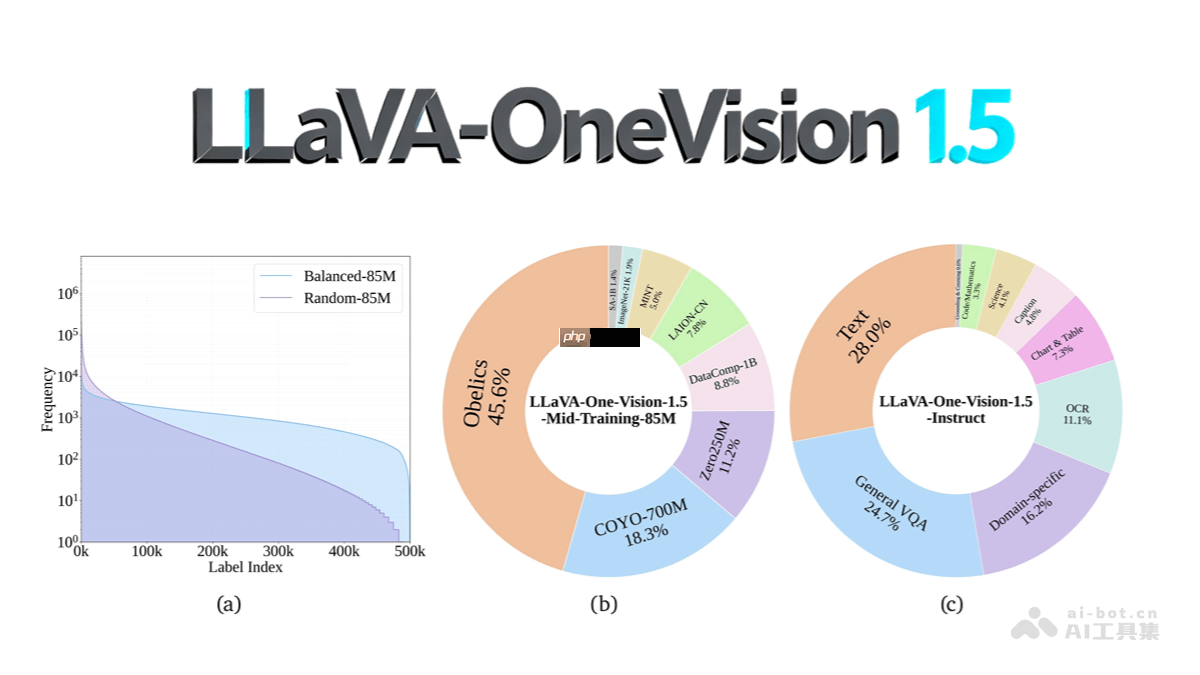
llava-onevision-1.5 是一款开源的先进多模态大模型,凭借高效的训练策略与高质量的数据构建,在性能、成本控制和可复现性方面表现出色。该模型采用自研的 rice-vit 视觉编码器,融合了2d旋转位置编码与区域感知注意力机制,支持可变分辨率输入,显著增强了对图像中对象及文字(ocr)的理解能力。语言部分基于强大的 qwen3 模型,通过三阶段渐进式训练流程——包括语言-图像对齐、高质量知识中期预训练以及视觉指令微调——实现深度跨模态融合。训练过程中引入离线并行数据打包与混合并行技术,大幅提升计算资源利用率和显存效率。在数据层面,构建了包含8500万样本的预训练数据集,采用“概念均衡”采样策略,覆盖多样化来源;同时打造了2200万条指令微调数据,涵盖八大任务类别,并经过多源聚合与格式标准化处理。llava-onevision-1.5 在多项多模态基准测试中表现优异,具备低成本部署潜力,且全链路开放,提供完整的代码、数据与模型权重,助力研究者和开发者轻松复现与二次开发。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
LLaVA-OneVision-1.5的核心功能
-
多模态理解与生成:能够综合处理图像与文本信息,生成连贯、准确的自然语言响应,支持复杂推理与内容生成。
-
视觉问答(VQA):根据图像内容回答用户提出的问题,适用于物体识别、属性判断、场景解析等多种视觉理解任务。
-
图像描述生成:为输入图像自动生成详尽、语义丰富的描述文本,提升图像可访问性与信息传达效率。
-
指令遵循能力:精准理解并执行多轮或多步骤指令,支持图像编辑建议、信息提取、分类等多样化操作。
-
跨模态检索:实现文本到图像或图像到文本的高效检索,满足内容搜索与匹配需求。
-
长尾概念识别:对低频出现的对象或抽象概念仍具备良好识别能力,增强模型在真实场景中的泛化表现。
-
多语言支持:支持多种语言的输入与输出,具备基础的跨语言多模态理解与生成能力。
-
知识增强推理:通过引入富含常识与专业知识的大规模数据进行预训练,提升模型在复杂任务中的逻辑与推理水平。
-
高效训练与开放复现:采用优化的数据流水线与分布式训练策略,降低训练开销,并公开全部资源,便于社区复现与扩展。
LLaVA-OneVision-1.5的技术架构
-
视觉编码器设计:采用自主研发的 RICE-ViT(Region-aware Cluster Discrimination Vision Transformer),结合区域感知注意力机制与统一区域簇判别损失函数,强化局部语义建模能力,兼容不同分辨率输入。
-
特征对齐投影器:使用多层感知机(MLP)结构将视觉特征映射至语言模型的嵌入空间,确保图像与文本表征的有效对齐。
-
语言主干模型:以 Qwen3 作为核心语言模型,提供强大的上下文理解与文本生成能力,支撑复杂的多模态交互任务。
-
三阶段训练范式:依次经历语言-图像对齐预训练、知识增强中期训练和视觉指令微调,逐步深化模型的跨模态理解与任务适应能力。
-
离线并行数据处理:利用特征驱动的“概念均衡”策略构建大规模预训练数据集,并通过离线并行打包减少填充(padding)浪费,提高训练吞吐量。
-
混合并行训练架构:集成张量并行、流水线并行与序列并行技术,配合长上下文优化手段,显著提升大规模训练的稳定性与效率。
-
数据工程体系:构建高质量、多样化的85M预训练与22M指令微调数据集,经过多源整合、格式归一化与安全过滤,保障数据可靠性与模型安全性。
LLaVA-OneVision-1.5的官方资源链接
LLaVA-OneVision-1.5的实际应用方向
-
智能客服系统:结合用户上传的截图或照片,自动识别问题并提供精准解答,提升服务效率与用户体验。
-
创意内容生成:辅助图文内容创作者生成标题、文案、故事脚本或社交媒体内容,加速内容生产流程。
-
教育技术支持:用于解释教材中的图表、科学图像或历史资料,帮助学生更直观地理解学习材料。
-
医学影像辅助诊断:协助医生分析X光、CT或MRI图像,生成初步报告或提示异常区域,提高诊疗效率。
-
自动驾驶感知模块:融入智能驾驶系统,实时解析道路环境图像,支持决策规划与风险预警。
-
图像编辑与设计助手:根据自然语言指令完成图像裁剪、风格迁移、元素添加等操作,降低图像处理门槛。
以上就是LLaVA-OneVision-1.5— EvolvingLMMS-Lab开源的多模态模型的详细内容,更多请关注php中文网其它相关文章!



 广告
广告







 543
543
























