
deepseek-ai 团队近日发布了题为《deepseek-ocr:contexts optical compression》的研究论文,提出一种通过视觉模态实现长文本上下文压缩的创新方法。根据 hugging face 页面信息,该模型参数规模为 3b。
开源地址:https://www.php.cn/link/32ce0ec3ee6f3951004c8ebb7511ffc1https://www.php.cn/link/b3f1ba764509b453d6cc48e0969e5cb7
据官方介绍,此次发布的 DeepSeek-OCR 包含两个核心组件:专用编码器 DeepEncoder 和解码器 DeepSeek3B-MoE-A570M。其中,DeepEncoder 针对高分辨率输入进行了优化设计,在确保低计算激活的同时实现高效压缩,有效将视觉 token 数量控制在合理范围内。
实验结果表明,当文本 token 数量不超过视觉 token 的 10 倍(即压缩比低于 10×)时,模型 OCR 准确率可达 97%;即使压缩比提升至 20×,准确率仍能维持在约 60% 的水平,展现出其在历史文档处理、长上下文压缩以及大语言模型记忆机制探索方面的广阔应用前景。同时,DeepSeek-OCR 具备出色的实用价值。
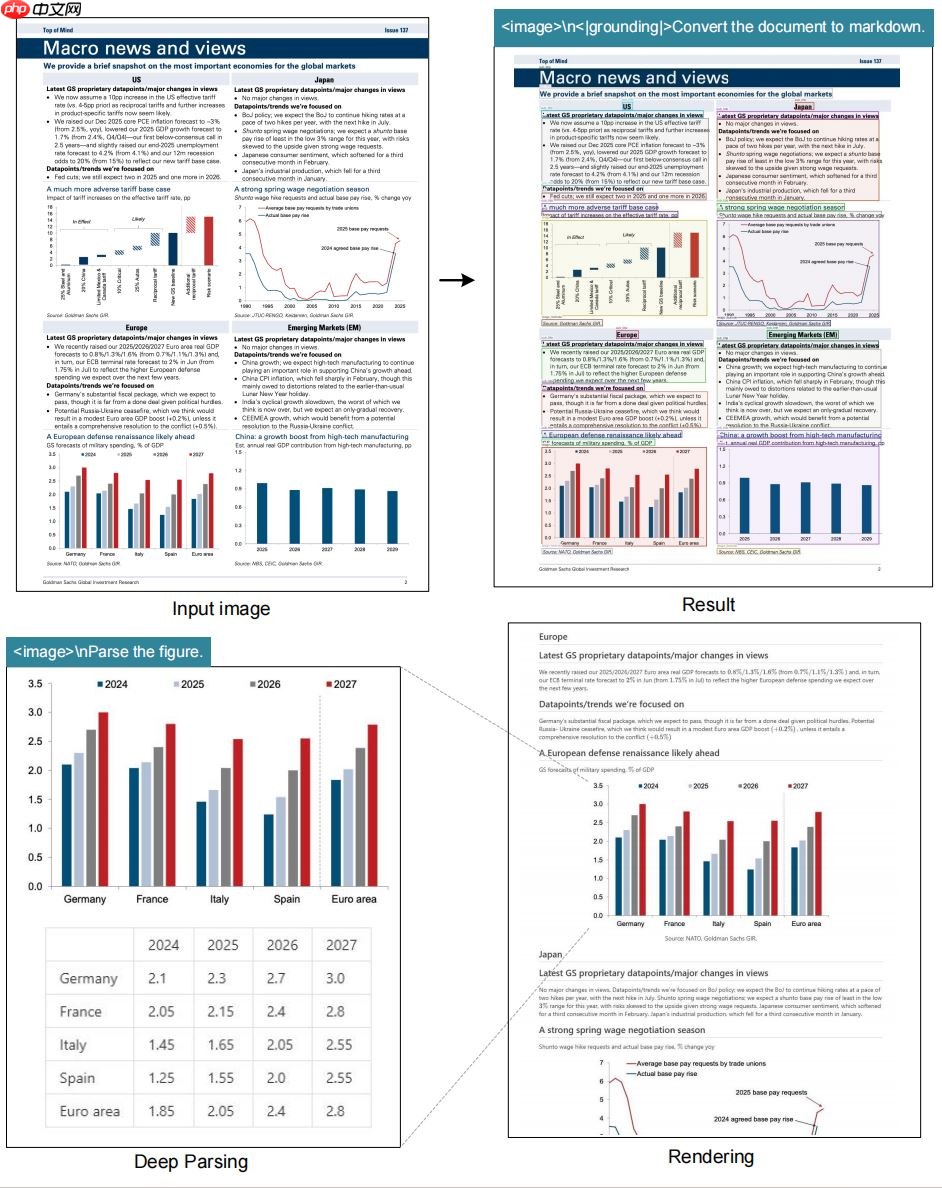
在 OmniDocBench 基准测试中,DeepSeek-OCR 仅用 100 个视觉 token 就超越了 GOT-OCR2.0(每页使用 256 个 token),而当视觉 token 不足 800 时,性能已优于 MinerU2.0(平均每页消耗超过 6000 个 token)。
在实际部署场景中,DeepSeek-OCR 可在单张 A100-40G 显卡上每日生成逾 20 万页高质量训练数据,适用于大规模视觉语言模型或大语言模型的训练需求。
源码地址:点击下载
以上就是DeepSeek 团队发布最新开源模型 DeepSeek-OCR的详细内容,更多请关注php中文网其它相关文章!

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号









 988
988
























