
大家好,我是老章,专注 ai 学习与实践。
先来直观体验一下 200 Tokens/s 的生成速度——没有加速,文字飞驰而过,眼睛几乎跟不上输出节奏。
在之前的文章中我提到过,不要再用 Ollama,也不要再依赖 llama.cpp。原因是在测试过程中我发现,虽然 llama.cpp 单请求推理速度极快,但一旦并发上升,性能就出现断崖式下滑。
 根本原因在于,llama.cpp 并未对张量并行(Tensor Parallelism)和批处理推理(Batch Inference)进行优化,而且未来大概率也不会支持张量并行。因此,它仅适合用于将模型部分或全部卸载到 CPU 的场景。如果你有多块 GPU,更推荐使用 vLLM 或 SGLang 这类专为高性能推理设计的引擎。
根本原因在于,llama.cpp 并未对张量并行(Tensor Parallelism)和批处理推理(Batch Inference)进行优化,而且未来大概率也不会支持张量并行。因此,它仅适合用于将模型部分或全部卸载到 CPU 的场景。如果你有多块 GPU,更推荐使用 vLLM 或 SGLang 这类专为高性能推理设计的引擎。
事实上,我在之前的多篇本地部署教程中,一直使用的都是 vLLM。
有作者曾指出:张量并行通过将模型每一层的计算拆分到多个 GPU 上执行,使得每块 GPU 只需完成一部分矩阵运算,从而实现各层在不同设备上的并行计算,最终让整体推理速度呈指数级提升。
对此说法,我一直存疑。于是本文就来做一次实测:分别测试单卡、双卡、四卡配置下的推理性能表现。
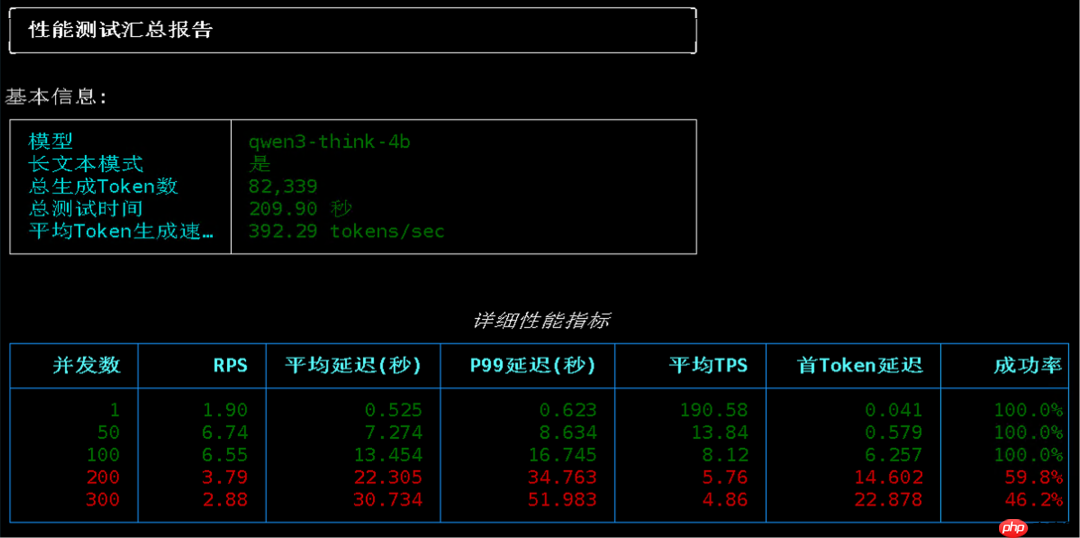
测试模型选用我最钟爱的 DeepSeek-R1-0528-Qwen3-8B。此前在双 4090 上部署该模型时已验证过其性能,上下文长度默认设为 128K。由于显存需求高达 24GB,单张 4090 难以承载,双卡才能顺利运行,最高推理速度约为 90 Tokens/s。
本次测试硬件为 H200,单卡配备 141GB 显存。
测试工具采用 LLM-Benchmark。
启动命令如下:
 显存占用直接飙升至 126GB。可见若不加限制,模型会尽可能占满可用显存。可通过参数
显存占用直接飙升至 126GB。可见若不加限制,模型会尽可能占满可用显存。可通过参数 --gpu-memory-utilization 控制显存使用率。
 性能测试结果如下:
性能测试结果如下:
 在 50 并发下,平均 TPS 达到 83;
在 50 并发下,平均 TPS 达到 83;
100 并发时,系统每秒可处理 47 个请求,平均生成速度为 49 Tokens/s。
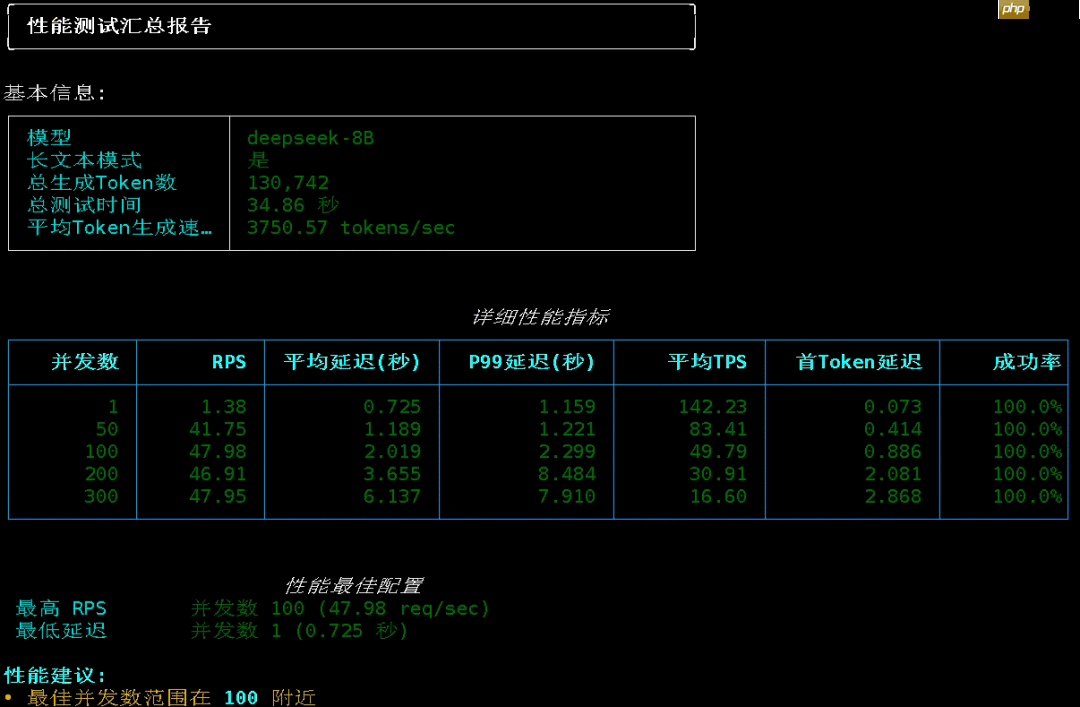
双卡模式下,启动方式基本一致,仅增加 --tensor-parallel-size 2 参数,并指定两张 GPU。
每张卡同样占用约 126GB 显存。
 测试结果如下:
测试结果如下:
 单并发情况下,TPS 从 142 提升至 172;
单并发情况下,TPS 从 142 提升至 172;
50 并发时,平均 TPS 由单卡的 83 上升到 91;
100 并发下,每秒仍处理 47 个请求,平均生成速度为 50 Tokens/s,提升微弱。
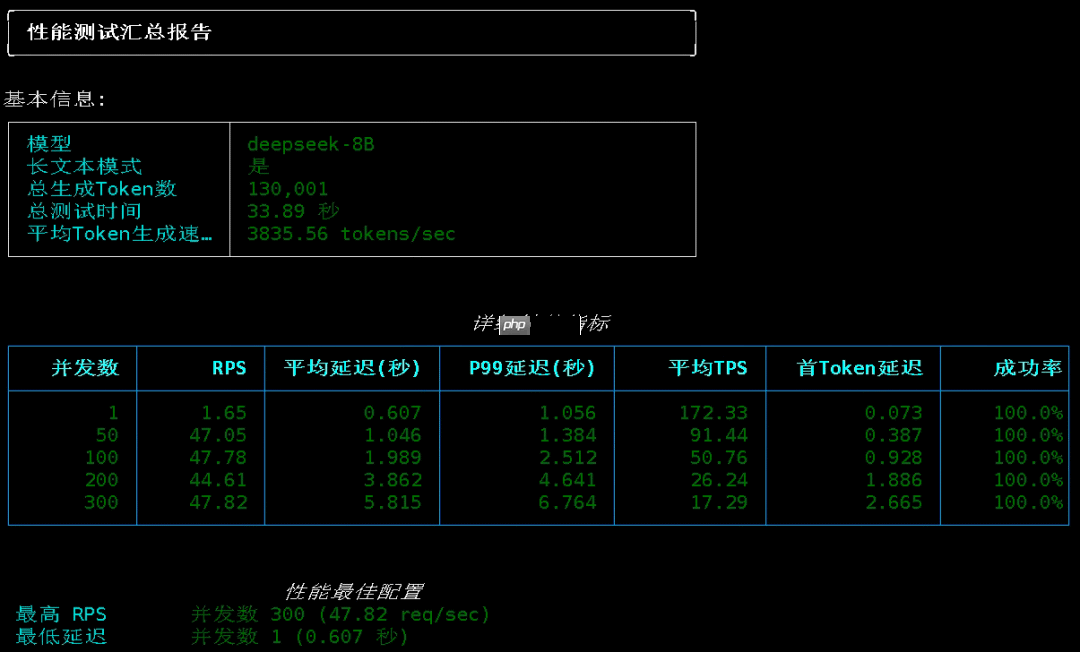
设置 --tensor-parallel-size 4
需要注意的是,我的第 4 和第 5 张 GPU 上还运行着其他模型任务。
 测试结果如下:
测试结果如下:
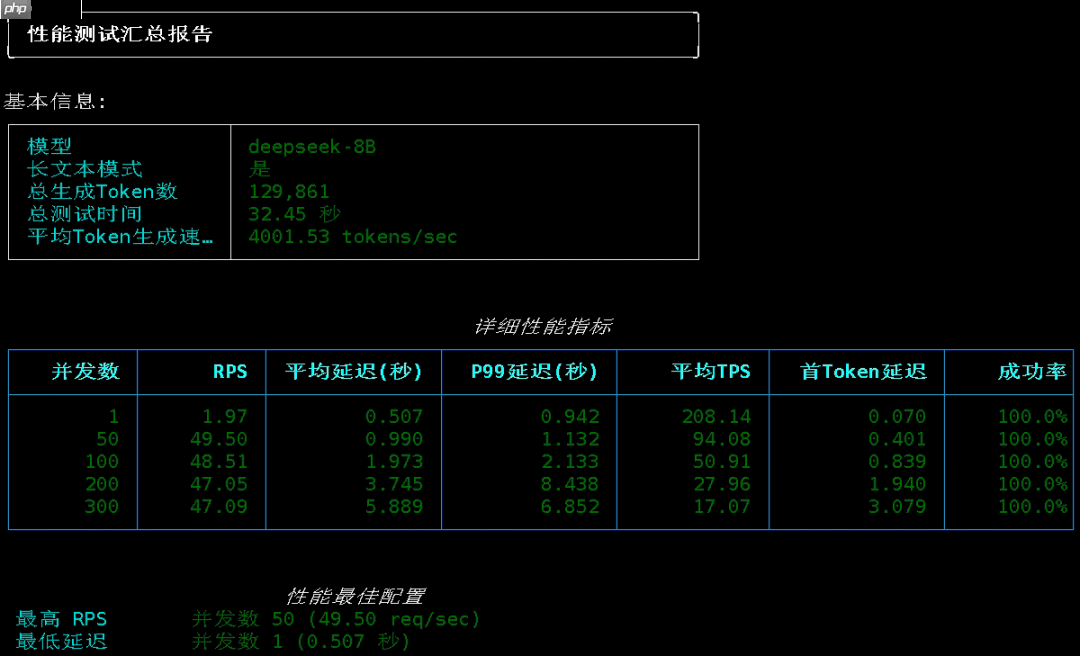 单并发 TPS 进一步提升至 208;
单并发 TPS 进一步提升至 208;
50 并发下,平均 TPS 达到 94;
100 并发时,每秒处理请求数为 48,平均生成速度维持在 50 Tokens/s,依旧无明显增长。
八卡并行未做测试,因其余 GPU 已被其他服务占满,不便停机调整。
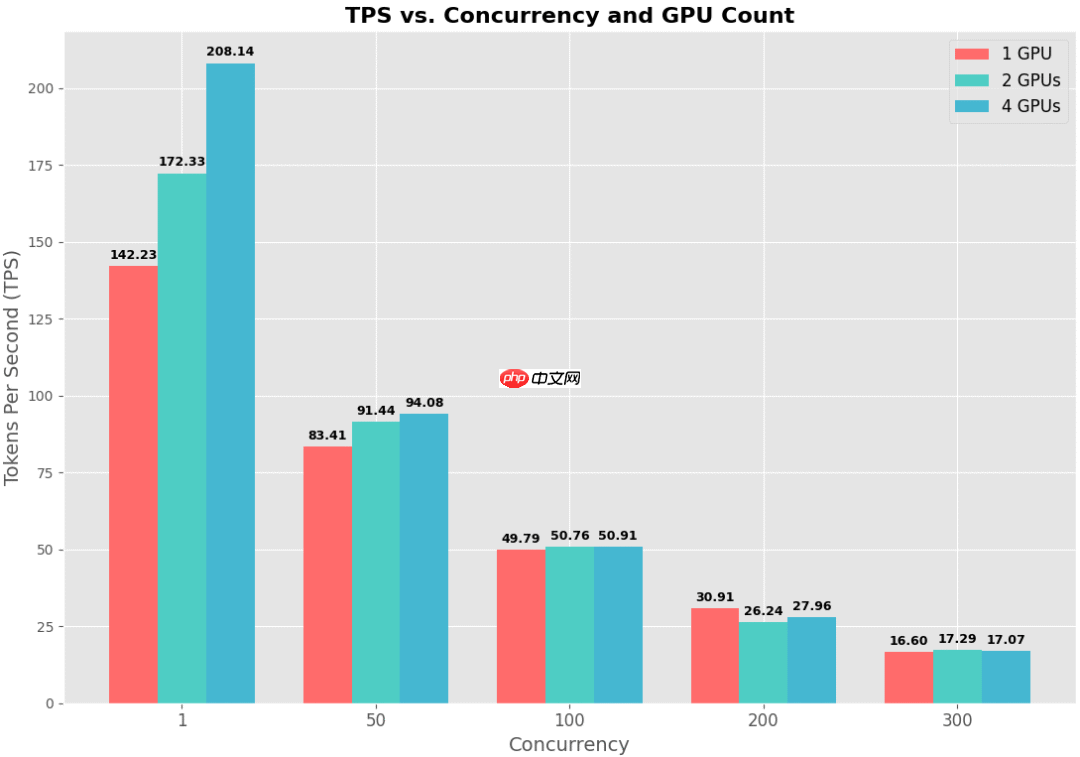
我用 Gemini 绘制了一张柱状图,用于对比不同并行策略下的 TPS 表现:
 总结:
总结:
在本地部署大模型时启用张量并行,确实能显著提升单请求的推理速度(TPS),但在高并发场景下,整体吞吐能力的提升趋于平缓,并不具备线性扩展效应。不过相比 llama.cpp 在并发压力下性能骤降的表现,vLLM 的稳定性无疑要优秀得多。
以上就是DeepSeek 8B 极限测试,200 Tokens每秒,眼球跟不上了的详细内容,更多请关注php中文网其它相关文章!

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号









 236
236
























