
美团longcat团队发布了uno-bench,这是一个用于评估多模态大语言模型统一能力的综合性基准测试。
该基准致力于系统化衡量模型在单模态与全模态理解方面的表现,覆盖44种任务类型以及5种不同的模态组合,并通过实验揭示了全模态性能与单模态能力之间的组合规律。
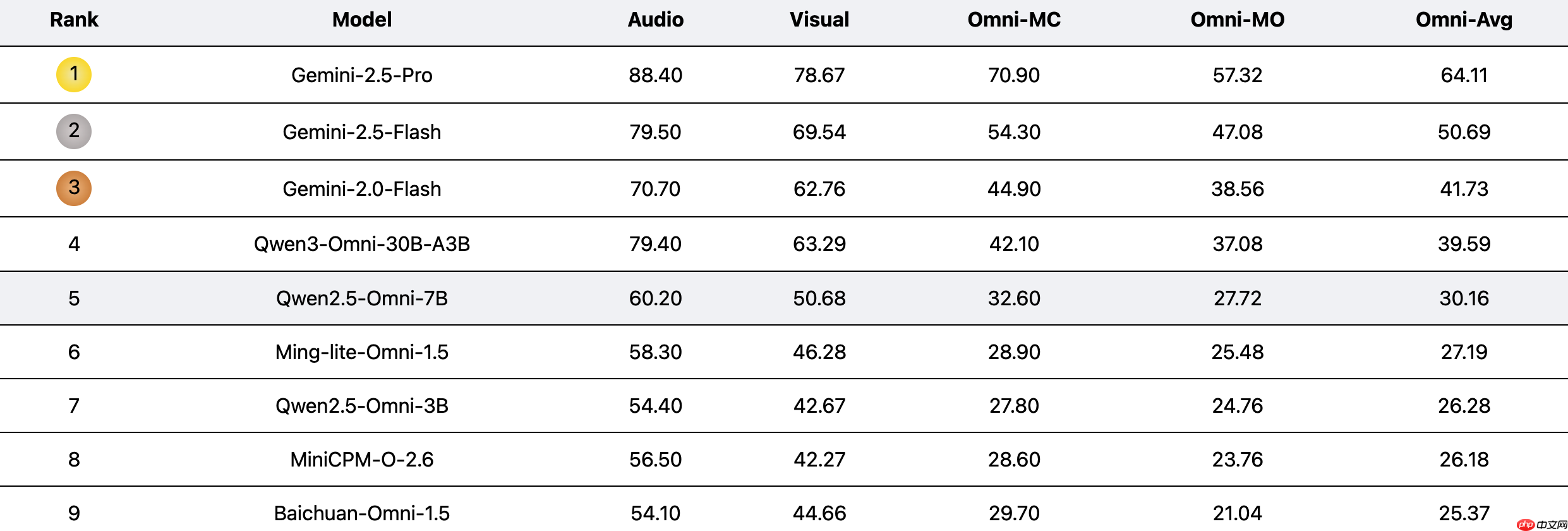
据悉,UNO-Bench包含1250个经过人工精心筛选的全模态样本(跨模态可解性高达98%)和2480个增强型单模态样本。其中,人工构建的数据集更贴近真实应用场景,尤其适用于中文环境;而自动压缩版本则提升了90%的运行效率,在保持与原始数据一致性的前提下,在18项公开基准上实现了98%的结果一致性。除了传统选择题外,团队还提出了一种新颖的多步骤开放式问题形式,以评估模型在复杂推理任务中的表现。这一形式结合了一个通用评分模型,支持对6类题型进行自动化评估,准确率高达95%。
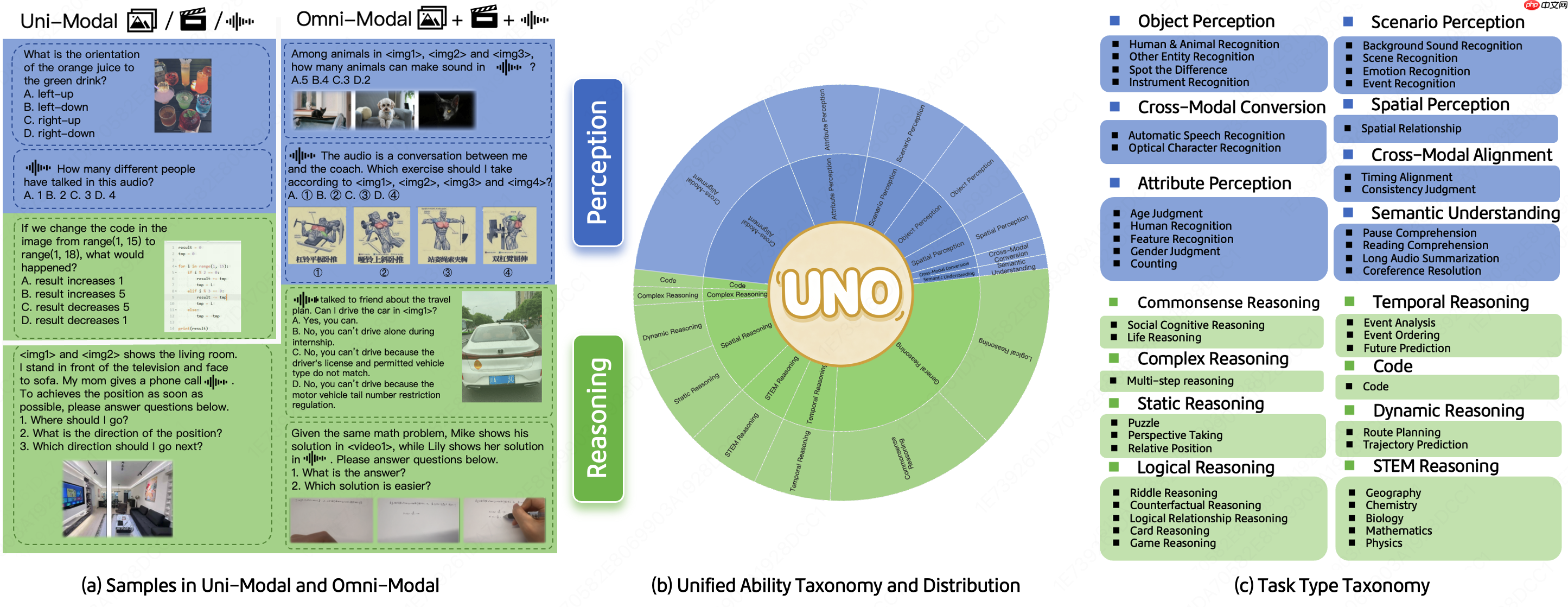
目前,UNO-Bench主要聚焦于中文场景,团队正积极寻求合作,推动英语及多语言版本的开发。UNO-Bench数据集已发布于Hugging Face平台,相关代码、论文及项目详情均已开源。
https://www.php.cn/link/455c8959885c1b38871319571e9ab72c
https://www.php.cn/link/36a213dec58f9ae20b81cd14d3358981
https://www.php.cn/link/db17bc578c383f5bb0cb9be70c42331c
以上就是美团 LongCat 发布 UNO-Bench,统一的多模态模型基准测试的详细内容,更多请关注php中文网其它相关文章!

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号









 875
875
























