OmniVinci是什么
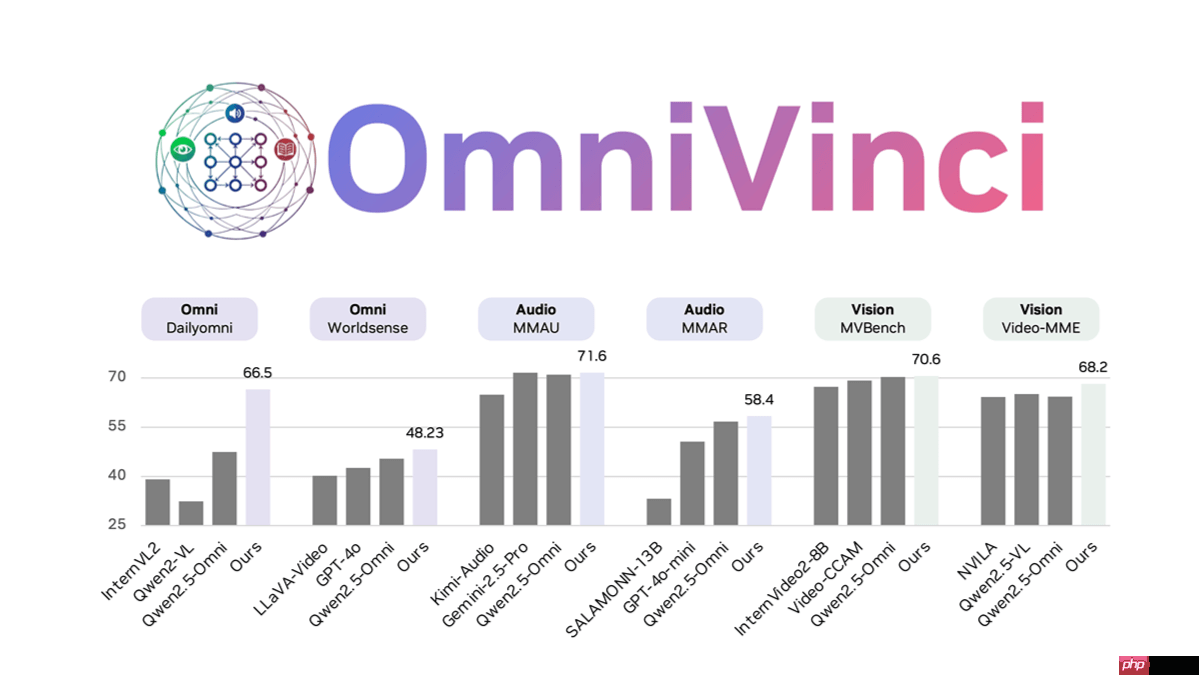
omnivinci是由nvidia推出的一款全模态大语言模型,专注于处理视觉、听觉、语言及推理等多模态任务。该模型通过创新的omnialignnet技术实现跨模态语义对齐,利用temporal embedding grouping机制解决时序同步难题,并引入constrained rotary time embedding来增强时间感知能力。在dailyomni等基准测试中,其表现优于qwen2.5等主流模型,尤其在音画同步理解方面展现出卓越性能。仅用0.2万亿tokens完成训练,效率显著高于同类产品,适用于媒体分析、游戏开发等多种场景。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
OmniVinci的主要功能
-
多模态理解 OmniVinci具备同时处理图像、视频、音频和文本信息的能力,实现跨模态联合理解。能够精准融合多种数据类型,例如解析视频中人物动作、语音内容与环境背景之间的关联。
-
跨模态对齐 借助OmniAlignNet模块,模型可强化视觉与音频嵌入在共享全模态潜在空间中的对齐效果,有效缓解传统模型中存在的模态语义割裂问题,提升融合精度。
-
时间信息处理 通过Temporal Embedding Grouping与Constrained Rotary Time Embedding技术,OmniVinci能精确捕捉视觉与音频信号的时间对齐关系,并编码绝对时间信息,适用于视频监控、语音分析等依赖时序的任务。
-
广泛的应用场景 支持包括视频内容解析、医疗AI辅助、机器人导航、语音转录翻译以及工业质检在内的多种应用,为各行业提供强大的多模态智能支持。
-
开源与社区共建 项目代码、训练数据及在线演示均已公开,便于研究人员与开发者使用、优化与二次开发,推动全模态人工智能生态的发展。
OmniVinci的技术原理
-
OmniAlignNet模块 利用OmniAlignNet实现视觉与音频特征在统一潜在空间中的深度对齐,增强不同模态间的语义一致性,从而提升整体理解能力。
-
Temporal Embedding Grouping 引入Temporal Embedding Grouping技术,用于建模视觉与音频流之间的相对时间关系,提升模型对动态多模态序列的理解水平。
-
Constrained Rotary Time Embedding 采用维度敏感的旋转式时间编码方式,精准标记绝对时间戳,使模型在处理长序列或多段输入时仍保持高精度时间感知。
-
数据优化与合成 构建了包含2400万条单模态与全模态对话的数据集,其中15%为显式构造的全模态合成样本。结合多模型协同纠错机制,有效抑制“模态幻觉”,保障数据质量。
-
高效训练策略 全程仅使用0.2T token进行训练,远低于其他同类模型(如1.2T),大幅降低计算资源消耗。同时优化训练流程,在多项任务中实现更优性能。
-
强化学习增强 在GRPO强化学习框架下训练,结合视听反馈信号加速收敛过程,提升模型在复杂多模态任务中的决策与表达能力。
-
模型架构创新 模型整体架构集成了OmniAlignNet、Temporal Embedding Grouping和Constrained Rotary Time Embedding等多项原创设计,显著增强了跨模态理解与时序建模能力。
OmniVinci的项目地址
OmniVinci的应用场景
-
视频内容分析 :可详细描述视频中的人物行为、对话内容及场景变化,广泛应用于视频解说生成、体育赛事分析、新闻摘要提取等场景,提供深层次的内容洞察。
-
医疗AI :结合医学影像(如CT、MRI)与医生口述记录,OmniVinci能准确回答临床相关问题,辅助诊断决策,提升医疗服务的智能化与精准化水平。
-
机器人导航 :支持通过自然语言语音指令控制机器人移动与操作,实现更直观的人机交互,适用于家庭服务、仓储物流、智能制造等机器人应用场景。
-
语音转录与翻译 :具备高精度语音识别与多语言互译能力,可用于实时会议记录、跨语言交流、在线教育等场景,提升沟通效率。
-
工业检测 :融合视觉图像与设备运行声音,应用于半导体检测、产线异常监测等工业场景,提高缺陷识别率与自动化水平,减少人工干预。
-
智能安防 :集成于视频监控系统,可实时分析画面与音频信息,自动识别可疑行为或突发事件,提升公共安全系统的响应速度与智能化程度。
以上就是OmniVinci— NVIDIA推出的全模态大语言模型的详细内容,更多请关注php中文网其它相关文章!



 广告
广告







 474
474






















