







Grafana 做 Linux 运维可视化核心是让关键指标一眼可读、异常能定位、趋势可预判;需先明确5–8个核心维度,用 Prometheus+Node Exporter 打牢数据底座,按运维动线布局仪表盘,并配置带业务语义的告警与联动下钻。

用 Grafana 做 Linux 运维数据可视化,核心不是堆图表,而是让关键指标一眼可读、异常能定位、趋势可预判。仪表盘设计得当,能大幅减少半夜被 CPU 爆满告警叫醒的次数。
明确监控目标:先想清楚“看什么”,再决定“怎么画”
别一上来就拖拽面板。先梳理你最关心的 5–8 个核心维度,比如:
- CPU 使用率(分用户/系统/等待,带 5 分钟 & 15 分钟负载对比)
- 内存实际可用量(非“free”值,而是 MemAvailable 或 free + buffers + cached)
- 磁盘 I/O 延迟(await、r_await/w_await,比 %util 更反映真实瓶颈)
- 根分区和关键挂载点的使用率(带 7 天增长趋势线)
- 活跃连接数(ESTABLISHED)、TIME_WAIT 数量及变化速率
每个指标对应一个明确运维动作——比如 I/O await > 20ms 就该查慢盘或应用写行为,而不是只看“磁盘快满了”。
用 Prometheus + Node Exporter 打好数据底座
Grafana 是画布,数据源才是颜料。Linux 基础指标推荐固定组合:
- Node Exporter(v1.6+)跑在每台服务器上,暴露 /metrics 端点
- Prometheus 定期抓取(scrape_interval: 15s),保留 15 天数据足够日常分析
- 关键指标优先用内置 exporter 指标,少自己写 shell 脚本暴露——维护成本高且易出错
例如查内存压力,直接用 node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100,比解析 free -h 输出稳定得多。
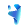
仪表盘布局:信息密度与视觉动线要匹配运维习惯
运维盯屏是“扫视—聚焦—下钻”过程,面板排布要顺应这个节奏:
- 顶部横栏放全局摘要:主机在线状态、最高负载主机、最近 1 小时告警数(用 Stat 面板+条件阈值着色)
- 中间分三列:左列 CPU/内存(高频查看),中列磁盘/网络(中频诊断),右列进程/服务(低频下钻)
- 所有时间序列图开启“Tooltip → Shared crosshair”,鼠标悬停时所有图同步显示同一时刻数值
- 对关键指标(如 root 分区使用率)加“Alert”图标链接到对应 Alertmanager 页面,点击直达告警详情
让告警真正有用:指标+阈值+上下文缺一不可
别只设“CPU > 90%”这种裸阈值。Grafana 中配合 Prometheus Rule 写有业务意义的告警:
- “过去 5 分钟平均负载 > CPU 核数 × 1.5,且持续 3 个周期”——过滤毛刺
- “/var/log 磁盘使用率 24 小时增长 > 15%,预测 48 小时内将满”——带预测逻辑
- 在 Grafana 面板里用变量(如 $host)联动,点击某台机器的异常指标,自动跳转到它的专属仪表盘
这样,值班时看到告警,不只是知道“哪里高了”,而是立刻明白“为什么高、影响面多大、下一步查哪”。
不复杂但容易忽略:定期删掉半年没点开过的仪表盘,合并语义重复的视图,给每个面板加一句简短说明(hover 提示即可)。可视化不是越多越好,是让正确的人,在正确的时间,看到正确的数字。




























