
新智元报道
编辑:LRS
【新智元导读】为了在用户体验中突出关键部分,首先需要吸引用户的注意力。人每时每刻都在处理大量信息,例如每秒钟视网膜接收到的数据量高达10的10次方比特,但人类会选择性地专注于与任务相关或感兴趣的区域,以便进一步处理,例如记忆、理解和采取行动。
 对人类注意力的建模,即显著性模型(saliency model),在神经科学、心理学、人机交互(HCI)和计算机视觉等领域正受到越来越多的关注。
对人类注意力的建模,即显著性模型(saliency model),在神经科学、心理学、人机交互(HCI)和计算机视觉等领域正受到越来越多的关注。
预测「哪些区域可能吸引注意力」的能力在图形、摄影、图像压缩和处理以及视觉质量测量等领域具有许多重要的应用。
然而,使用机器学习和基于智能手机的凝视估计来加速眼动研究需要专门的硬件,每台成本高达三万美元,这限制了其广泛应用。
最近,谷歌的研究人员发表了两篇相关领域的研究论文,分别在CVPR 2022和CVPR 2023上发布,研究了如何利用「人类注意力预测模型」来提升用户体验。例如,通过图像编辑操作最大限度地减少视觉混乱、分心或伪影,使用图像压缩加快网页或应用程序的加载,并引导机器学习模型实现更直观的类人解释和模型性能。
这两篇论文主要关注图像编辑和图像压缩,并讨论了在具体应用场景下,关于注意力建模的最新进展。
注意力引导的图像编辑对人体注意力的建模,通常需要将眼睛看到的图像作为输入,如自然图像或网页的屏幕截图,并将预测的热力图作为输出。
预测得到的热力图会根据「眼球跟踪器」或「鼠标悬停/点击」等收集到的实时注意力近似值进行评估。
之前的模型主要利用手工制作的视觉线索特征,如颜色/亮度对比度、边缘和形状等,但最近一些方法开始转向基于深度神经网络来自动学习判别特征,使用的模型包括卷积、递归神经网络以及视觉Transformer网络等。
在CVPR 2022上,谷歌发表的一篇论文中,利用深度显著性模型(deep saliency models)进行视觉逼真的编辑(visually realistic edits),可以显著改变观察者对不同图像区域的注意力。
 论文链接:https://www.php.cn/link/c644332952f476c37daa950b502c850e
论文链接:https://www.php.cn/link/c644332952f476c37daa950b502c850e
例如,移除背景中分散注意力的物体可以减少照片的杂乱程度,从而提高用户满意度;同样,在视频会议中,减少背景中的混乱度也可以增加对主要发言者的关注度。
为了探索哪些类型的编辑效果是可实现的,以及这些效果如何影响观众的注意力,研究人员开发了一个优化框架,用于使用可区分的预测显著性模型来引导图像中的视觉注意力。
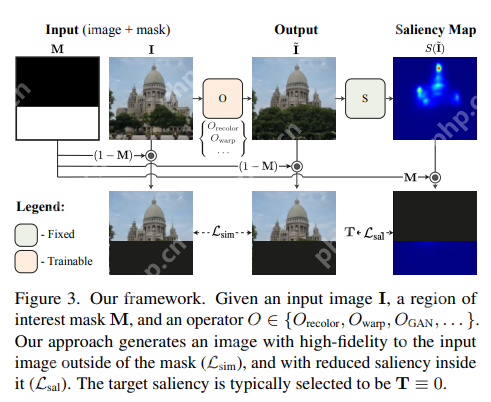 给定输入图像和表示干扰物区域的二元遮罩,使用显著性预测模型对遮罩内的像素提供指导并编辑图像,降低遮罩区域内的显著性。
给定输入图像和表示干扰物区域的二元遮罩,使用显著性预测模型对遮罩内的像素提供指导并编辑图像,降低遮罩区域内的显著性。
为了确保编辑后的图像自然且逼真,研究人员精心选择了四种图像编辑操作符,包括两个标准图像编辑操作(即重新着色和图像扭曲);以及两个可学习的操作符,即多层卷积滤波器和生成模型(GAN)。
利用这些操作符,该框架可以产生各种强大的效果,包括重新着色、修复、伪装、对象编辑、插入以及面部属性编辑,并且所有这些效果都是由单个预训练的显著性模型驱动的,没有任何额外的监督或训练。
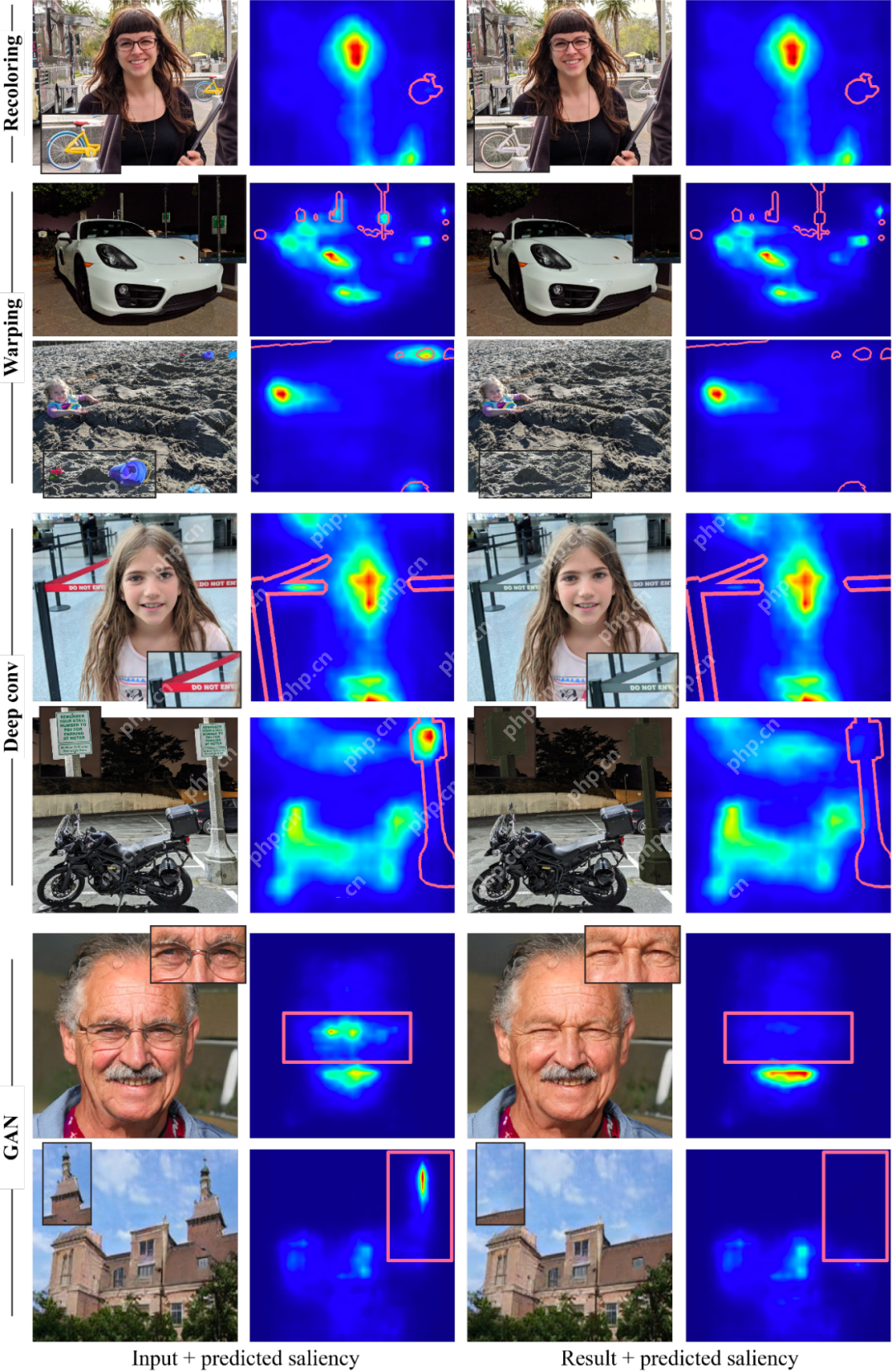 减少视觉干扰的例子,由显著性模型与几个操作符引导,干扰物区域被标记在显著性图(红色边框)的顶部。
减少视觉干扰的例子,由显著性模型与几个操作符引导,干扰物区域被标记在显著性图(红色边框)的顶部。
需要注意的是,研究人员的目标不是与产生每种效果的专用方法竞争,而是演示如何通过嵌入在深度显著性模型中的知识来指导多个编辑操作。
个性化的显著性建模之前的研究假定单个显著性模型即可完成对全部人群的预测任务,但人类的注意力在个体之间是有差异的:虽然对显著线索的检测是一致的,但具体的顺序、解释和注视分布可能有很大差异,这也为个人或团体提供了创建个性化用户体验的机会。
在CVPR 2023的一篇论文中,谷歌的研究人员引入了一个用户感知的显著性模型,这是首个仅用单模型即可预测某个用户、一组用户和通用人群注意力的框架。
 论文链接:https://www.php.cn/link/f40fe967870174ded9323bae71c5ce50
论文链接:https://www.php.cn/link/f40fe967870174ded9323bae71c5ce50
该框架的核心是将每个参与者的视觉偏好与每个用户的注意力热力图和自适应用户遮罩进行组合,需要在训练过程中每个用户的注意力标注都是可用的,可用的数据集包括用于自然图像的OSIE移动的凝视数据集、网页的FiWI和WebSaliency数据集。
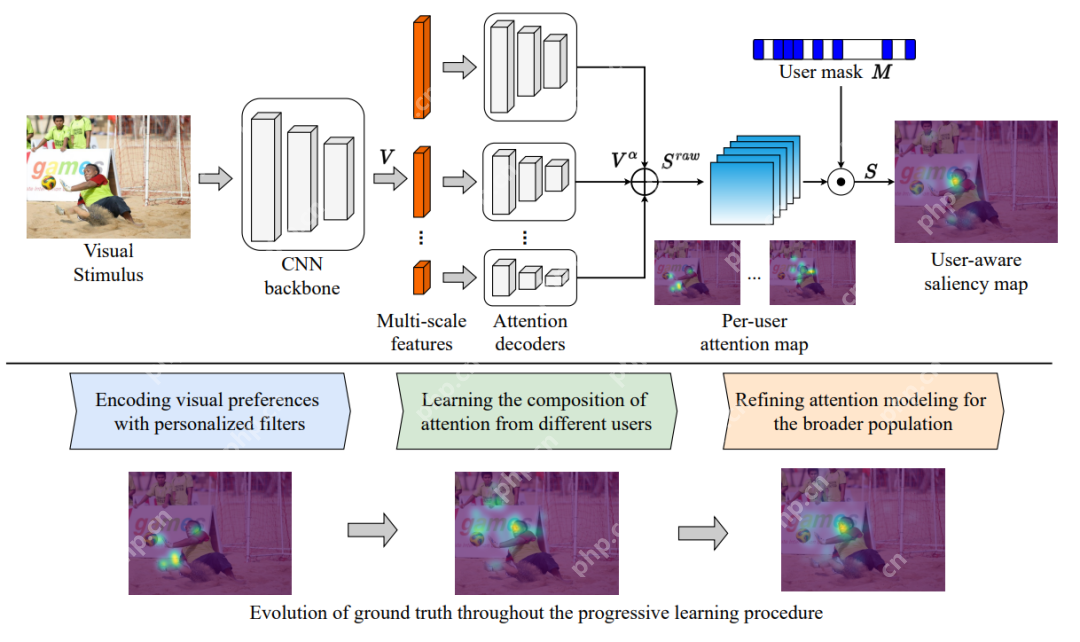 该模型并不预测表示所有用户的注意力的单个显著性热力图,而是预测每个用户的注意力图以编码个体的注意力模式。
该模型并不预测表示所有用户的注意力的单个显著性热力图,而是预测每个用户的注意力图以编码个体的注意力模式。
此外,该模型采用用户掩码(大小等于参与者数量的二进制向量)来指示当前样本中参与者的存在,使得模型可以选择一组参与者,并将偏好组合成单个热力图。
 预测注意力与GT值,EML-Net是最先进模型的预测,对于两个参与者/组具有相同的预测;我们提出的用户感知显著性模型的预测,可以正确预测每个参与者/组的独特偏好。第一个图像来自OSIE图像集,第二个图像来自FiWI。
预测注意力与GT值,EML-Net是最先进模型的预测,对于两个参与者/组具有相同的预测;我们提出的用户感知显著性模型的预测,可以正确预测每个参与者/组的独特偏好。第一个图像来自OSIE图像集,第二个图像来自FiWI。
以显著特征为中心的渐进式图像解码除了图像编辑,人类注意力模型也可以改善用户的浏览体验。
在上网时,最让人感到不舒服的用户体验之一就是等待加载带有图像的网页,特别是在网速很慢的情况下,一种改善用户体验的方式是图像的渐进式解码,可以随着数据逐渐下载再解码,并显示越来越高分辨率的图像,直到全分辨率图像准备就绪。
渐进式解码通常按顺序进行(例如,从左到右、从上到下),使用预测注意力模型,就可以基于显著性对图像进行解码,从而可以首先发送显示最显著区域的细节所需的数据。
例如,在肖像中,用于面部的字节可以优先于用于失焦背景的字节,因此用户更早地感知到更好的图像质量,并体验到显著减少的等待时间。
基于这个想法,预测注意力模型可以帮助图像压缩和更快地加载具有图像的网页,改善大型图像和流媒体/VR应用的渲染。
结论上面两篇论文展示了人类注意力的预测模型如何通过具体的应用场景实现令人愉快的用户体验,例如图像编辑操作,可以减少用户图像或照片中的混乱、分心或伪影,以及渐进式图像解码,可以大大减少用户在图像完全渲染时的感知等待时间。
文中提出的用户感知显著性模型可以进一步为个人用户或群体个性化上述应用程序,从而实现更丰富、更独特的体验。
参考资料:
https://www.php.cn/link/0e99eacf79d6fee9b99f889e6da46c0a
以上就是真·抓住用户「眼球」:无需专用硬件,谷歌教你用「注意力」提升产品体验|CVPR 2023的详细内容,更多请关注php中文网其它相关文章!

谷歌浏览器Google Chrome是一款可让您更快速、轻松且安全地使用网络的浏览器。Google Chrome的设计超级简洁,使用起来得心应手。这里提供了谷歌浏览器纯净安装包,有需要的小伙伴快来保存下载体验吧!

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 895
895



















