
minimax-m1是minimax团队发布的全新开源推理模型,结合了混合专家架构(moe)与闪电注意力机制(lightning attention),总参数规模达到4560亿,每token激活459亿参数。该模型在性能上超越国内主流闭源模型,接近国际顶尖水平,具备极高的性价比。minimax-m1原生支持长达100万token的上下文长度,并提供40k和80k两种推理预算版本,适用于处理长输入和复杂推理任务。基准测试显示,它在多个指标上优于deepseek等开源模型,在软件工程、长上下文理解和工具调用方面表现尤为突出。其高效的计算能力和强大的推理能力为下一代语言模型代理提供了坚实基础。

Ke361是一个开源的淘宝客系统,基于最新的ThinkPHP3.2版本开发,提供更方便、更安全的WEB应用开发体验,采用了全新的架构设计和命名空间机制, 融合了模块化、驱动化和插件化的设计理念于一体,以帮助想做淘宝客而技术水平不高的朋友。突破了传统淘宝客程序对自动采集商品收费的模式,该程序的自动 采集模块对于所有人开放,代码不加密,方便大家修改。集成淘点金组件,自动转换淘宝链接为淘宝客推广链接。K
 0
0

☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 MiniMax-M1的核心功能
MiniMax-M1的核心功能
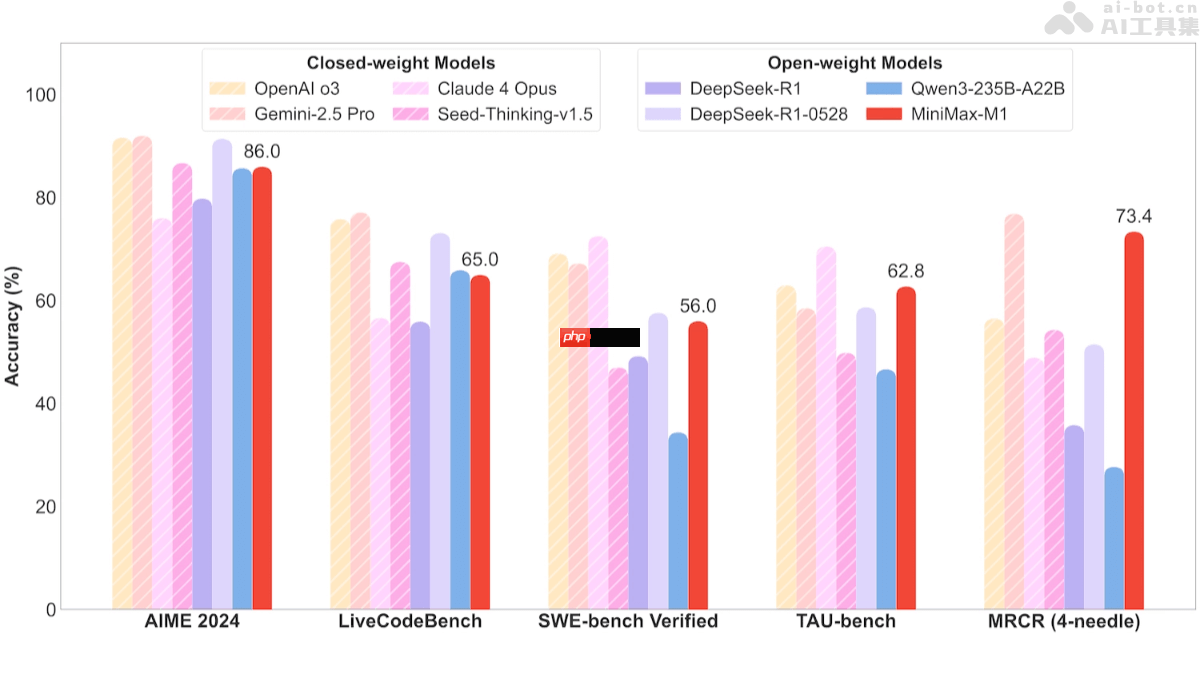 MiniMax-M1的项目资源
MiniMax-M1的项目资源以上就是MiniMax-M1— MiniMax最新开源的推理模型的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号





 861
861
























