







apache flink:探索数据流编程模型 | 从入门到精通 - 第2期(每日一学)
Apache Flink作为一款备受瞩目的实时计算引擎,在实际应用和编程之前,掌握其数据流编程模型至关重要。这将帮助你建立对核心概念的整体理解,从而更深入地学习具体细节。
Apache Flink:数据流编程模型
▾点击播放视频教程▾
 https://www.php.cn/link/002fdf1e30206e2b0289c5bdc7d5a369
https://www.php.cn/link/002fdf1e30206e2b0289c5bdc7d5a369
在Flink 1.9的最新版本中,数据流编程模型涵盖的概念包括:抽象层次、程序与数据流、并行数据流、窗口、时间概念、有状态计算以及容错检查点。
| 抽象层次Flink为开发流/批处理应用程序提供了不同的抽象层次。
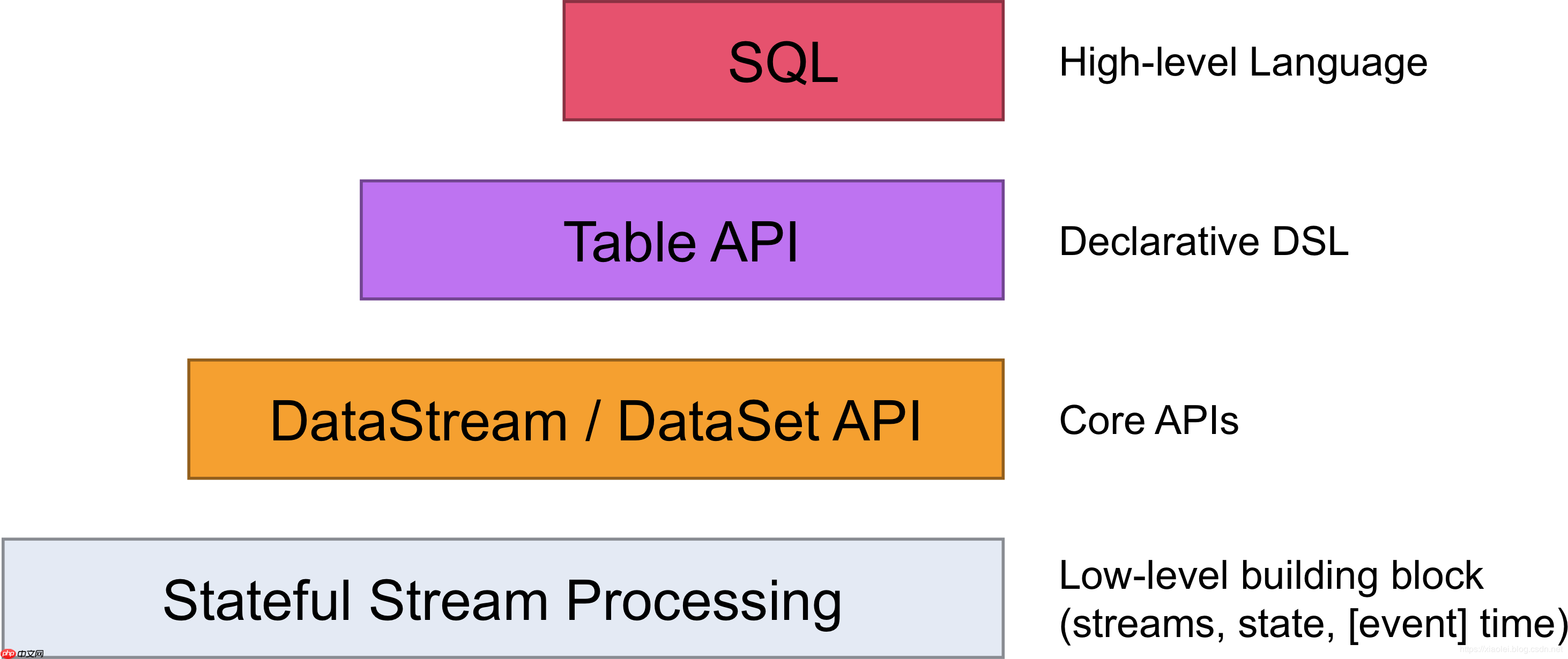 最基础的抽象层次仅提供有状态流,通过Process Function嵌入到DataStream API中,允许用户自由处理来自一个或多个流的事件,并使用一致的容错状态。此外,用户可以注册事件时间和处理时间回调,使得程序能够实现复杂的计算。然而,许多应用无需这种低级抽象,而是利用Core APIs进行开发,例如DataStream API(用于有界/无界流)和DataSet API(用于有界数据集)。这些API提供了数据处理的通用构建块,如各种形式的用户定义转换、连接、聚合、窗口和状态等。处理的数据类型在相应的编程语言中以类表示。 低级的Process Function与DataStream API集成,因此仅能对某些操作进行低级抽象。DataSet API在有界数据集上提供了额外的基本操作,如循环/迭代。 Table API是一种以表为中心的声明性DSL,支持动态更改表(表示流时)。Table API遵循(扩展)了关系模型:表附加了一个模式(类似于关系数据库中的表),API提供了可比较的操作,如select、project、join、group-by、aggregate等。Table API程序以声明方式定义逻辑操作,而非具体指定代码的外观。尽管Table API可以通过多种类型的用户定义函数进行扩展,但其表现力不如Core API,但使用起来更加简洁(编写代码更少)。此外,Table API程序在执行前还会应用优化规则进行优化。 表与DataStream/DataSet之间可以无缝转换,使得程序能够混合使用Table API以及DataStream和DataSet API。 Flink提供了最高级别的抽象,即SQL。这种抽象在语义和表达上与Table API类似,但程序以SQL查询表达式形式表示。SQL抽象与Table API紧密交互,SQL查询可以在Table API定义的表上执行。 | 程序与数据流Flink程序的基本构建块是流和转换。(请注意,Flink的DataSet API中使用的DataSet内部也是流 - 稍后会详细介绍。)从概念上讲,流是(可能永无止境的)数据记录流,而转换操作将一个或多个流作为输入,并产生一个或多个输出流作为结果。
最基础的抽象层次仅提供有状态流,通过Process Function嵌入到DataStream API中,允许用户自由处理来自一个或多个流的事件,并使用一致的容错状态。此外,用户可以注册事件时间和处理时间回调,使得程序能够实现复杂的计算。然而,许多应用无需这种低级抽象,而是利用Core APIs进行开发,例如DataStream API(用于有界/无界流)和DataSet API(用于有界数据集)。这些API提供了数据处理的通用构建块,如各种形式的用户定义转换、连接、聚合、窗口和状态等。处理的数据类型在相应的编程语言中以类表示。 低级的Process Function与DataStream API集成,因此仅能对某些操作进行低级抽象。DataSet API在有界数据集上提供了额外的基本操作,如循环/迭代。 Table API是一种以表为中心的声明性DSL,支持动态更改表(表示流时)。Table API遵循(扩展)了关系模型:表附加了一个模式(类似于关系数据库中的表),API提供了可比较的操作,如select、project、join、group-by、aggregate等。Table API程序以声明方式定义逻辑操作,而非具体指定代码的外观。尽管Table API可以通过多种类型的用户定义函数进行扩展,但其表现力不如Core API,但使用起来更加简洁(编写代码更少)。此外,Table API程序在执行前还会应用优化规则进行优化。 表与DataStream/DataSet之间可以无缝转换,使得程序能够混合使用Table API以及DataStream和DataSet API。 Flink提供了最高级别的抽象,即SQL。这种抽象在语义和表达上与Table API类似,但程序以SQL查询表达式形式表示。SQL抽象与Table API紧密交互,SQL查询可以在Table API定义的表上执行。 | 程序与数据流Flink程序的基本构建块是流和转换。(请注意,Flink的DataSet API中使用的DataSet内部也是流 - 稍后会详细介绍。)从概念上讲,流是(可能永无止境的)数据记录流,而转换操作将一个或多个流作为输入,并产生一个或多个输出流作为结果。
在执行时,Flink程序被映射为流式数据流,由流和转换算子组成。每个数据流都以一个或多个源开始,并以一个或多个接收器结束。数据流类似于任意有向无环图(DAG)。尽管通过迭代结构允许特殊形式的循环,但为了简单起见,我们将在大多数情况下对其进行掩盖。
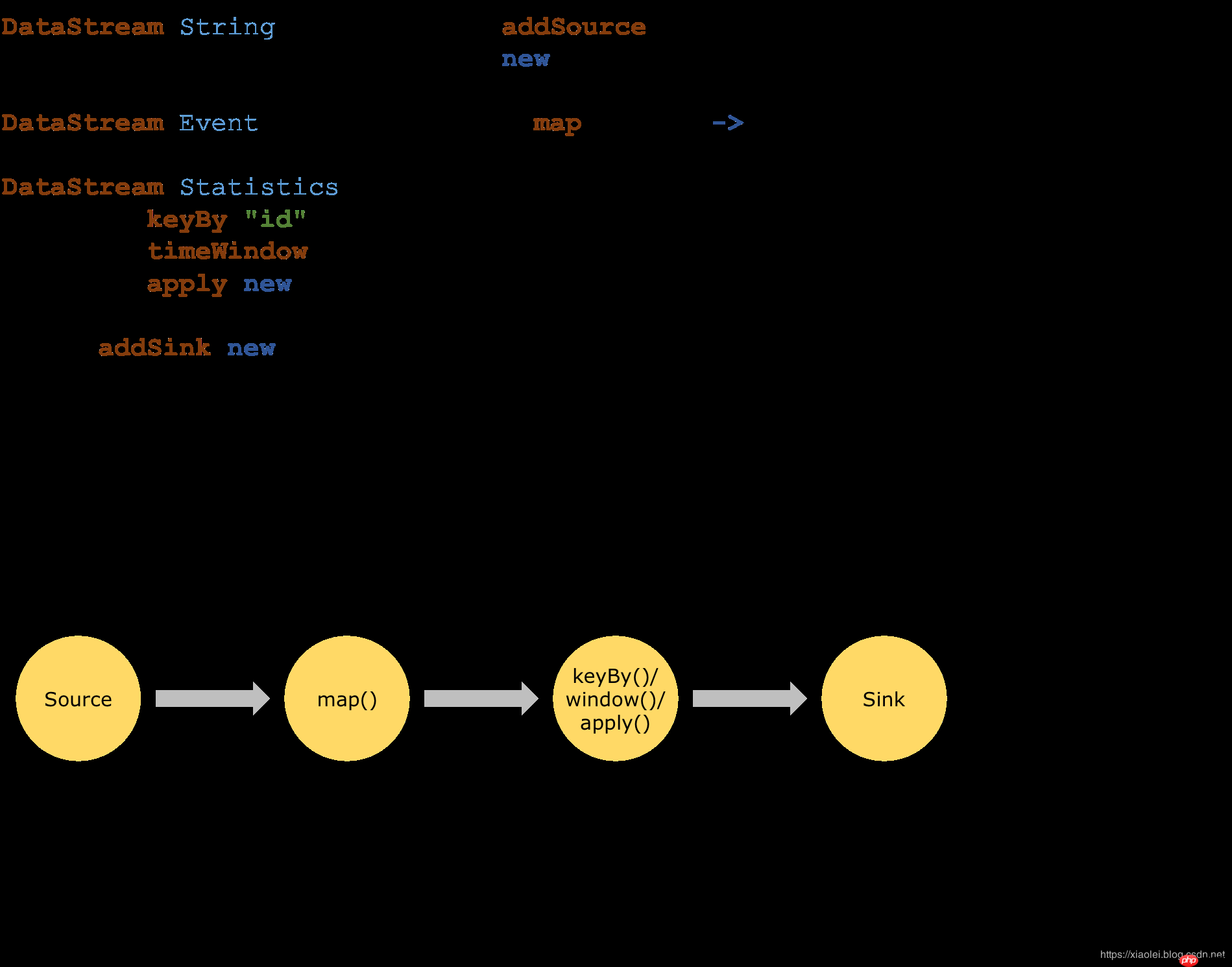 通常,程序中的转换与数据流中的算子之间存在一对一的对应关系。但有时一个转换可能包含多个转换算子。源和接收器的记录可以在流连接器和批处理连接器文档中找到。转换则在DataStream operators算子和DataSet转换文档中。
通常,程序中的转换与数据流中的算子之间存在一对一的对应关系。但有时一个转换可能包含多个转换算子。源和接收器的记录可以在流连接器和批处理连接器文档中找到。转换则在DataStream operators算子和DataSet转换文档中。
| 并行数据流Flink中的程序本质上是并行和分布式的。在执行期间,流具有一个或多个流分区,每个算子具有一个或多个算子子任务。算子子任务彼此独立,可以在不同的线程中执行,并可能在不同的机器或容器上运行。 算子子任务的数量即该特定算子的并行度。流的并行度始终是其生成算子的并行度。同一程序中的不同算子可能具有不同的并行级别。
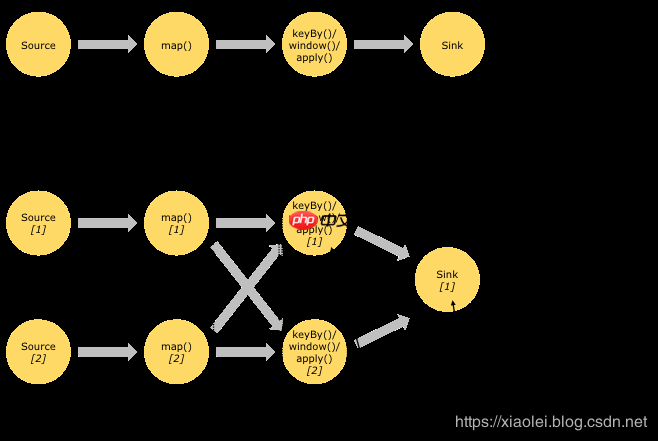 流可以在两个算子之间以一对一(或转发)模式或重新分发模式传输数据:
流可以在两个算子之间以一对一(或转发)模式或重新分发模式传输数据:

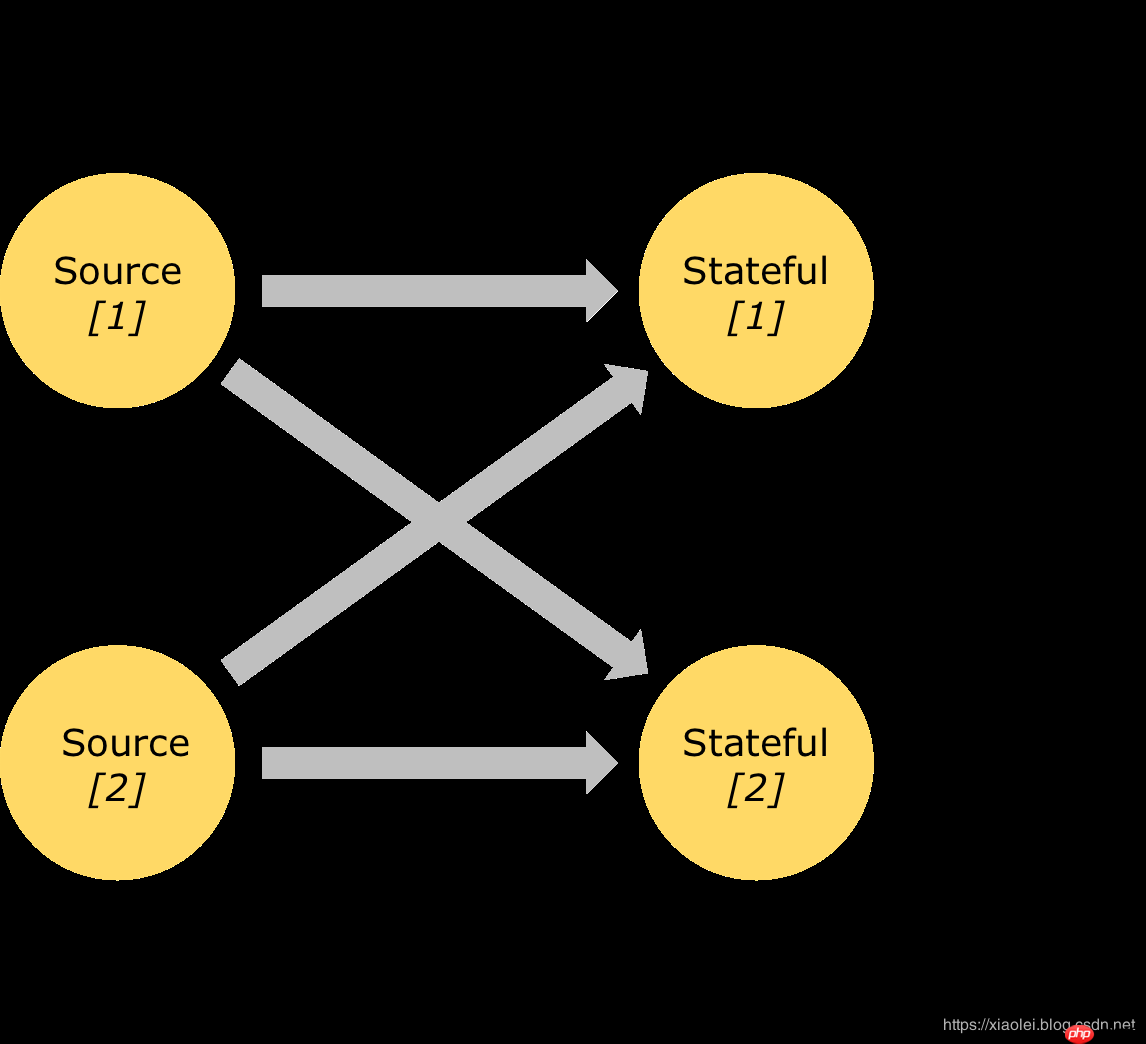
一对一流(例如,上图中的Source和map()算子之间)保留元素的分区和排序。这意味着source算子的子任务[1]生成的元素顺序,在map()算子的子任务[1]中看到的是一样的。 重新分配流(在上图中的map()和keyBy/window之间,以及keyBy/window和Sink之间)重新分配流的分区。每个算子子任务将数据发送到不同的目标子任务,具体取决于所选的转换。例如keyBy()(通过散列键重新分区),broadcast()或rebalance()(随机重新分区)。在重新分配交换中,元素之间的排序仅在每对发送和接收子任务中保留(例如,map()的子任务[1]和keyBy/window的子任务[2])。因此,在此示例中,每个键内的排序被保留,但并行性确实引入了关于不同键的聚合结果到达接收器的顺序的非确定性。 | 窗口聚合事件(例如,计数,总和)在流上的工作方式与批处理方式不同。例如,不可能计算流中的所有元素,因为流通常是无限的(无界)。相反,流上的聚合(计数,总和等)由窗口限定,例如“在最后5分钟内计数”或“最后100个元素的总和”。
窗口可以是时间驱动的(例如:每30秒)或数据驱动(例如:每100个元素)。人们通常区分不同类型的窗口,例如翻滚窗口(没有重叠),滑动窗口(具有重叠)和会话窗口(由不活动间隙打断)。
 | 时间概念当在流程序中引用时间(例如定义窗口)时,可以参考不同的时间概念:
| 时间概念当在流程序中引用时间(例如定义窗口)时,可以参考不同的时间概念:
事件时间(Event Time)是事件的创建时间。它通常由事件中的时间戳来描述,例如由生产传感器或生产服务来附加。Flink通过时间戳分配器访问事件时间戳。接入时间(Ingestion time)是事件在源操作员处输入Flink数据流的时间。处理时间(Processing Time)是执行基于时间的操作的每个操作员的本地时间。 | 有状态计算虽然数据流中的许多计算只是一次查看一个单独的事件(例如事件解析器),但某些操作会记住多个事件(例如窗口操作符)的信息。这些操作称为有状态。
| 有状态计算虽然数据流中的许多计算只是一次查看一个单独的事件(例如事件解析器),但某些操作会记住多个事件(例如窗口操作符)的信息。这些操作称为有状态。
状态计算的状态保持在可以被认为是嵌入式键/值存储的状态中。状态被严格地分区和分布在有状态计算读取的流中。因此,只有在keyBy()函数之后才能在有键的流上访问键/值状态,并且限制为与当前事件的键相关联的值。对齐流和状态的键可确保所有状态更新都是本地操作,从而保证一致性而无需事务开销。此对齐还允许Flink重新分配状态并透明地调整流分区。
 | 容错检查点Flink使用流重放和检查点(checkpointing)的组合实现容错。检查点与每个输入流中的特定点以及每个操作符的对应状态相关。通过恢复算子的状态并从检查点重放事件,可以从检查点恢复流数据流,同时保持一致性(恰好一次处理语义)。 检查点间隔是在执行期间用恢复时间(需要重放的事件的数量)来折中容错开销的手段。 容错内部的描述提供了有关Flink如何管理检查点和相关主题的更多信息。
| 容错检查点Flink使用流重放和检查点(checkpointing)的组合实现容错。检查点与每个输入流中的特定点以及每个操作符的对应状态相关。通过恢复算子的状态并从检查点重放事件,可以从检查点恢复流数据流,同时保持一致性(恰好一次处理语义)。 检查点间隔是在执行期间用恢复时间(需要重放的事件的数量)来折中容错开销的手段。 容错内部的描述提供了有关Flink如何管理检查点和相关主题的更多信息。
| 流地批处理Flink流程序上执行批处理,其中流是有界的(有限数量的元素)。DataSet在内部被视为数据流。因此,上述概念以相同的方式应用于批处理程序,并且除了少数例外它们适用于流程序:
批处理程序的容错不使用检查点(checkpointing)。通过完全重放流来进行恢复。因为输入有限所以是可行的。这会使成本更多地用于恢复,但使常规处理更代价更低,因为它避免了检查点。DataSet API中的有状态操作使用简化的内存/核外数据结构,而不是键/值索引。DataSet API引入了特殊的同步(超级步骤)迭代,这些迭代只能在有界流上进行。| 上期回顾初识Apache Flink - 数据流上的有状态计算
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://www.php.cn/link/10f99288a55b29b14bd6bc156d37f692





























