
 官网: https://www.php.cn/link/e624ee446bd5711b139afe335485a2d8
官网: https://www.php.cn/link/e624ee446bd5711b139afe335485a2d8
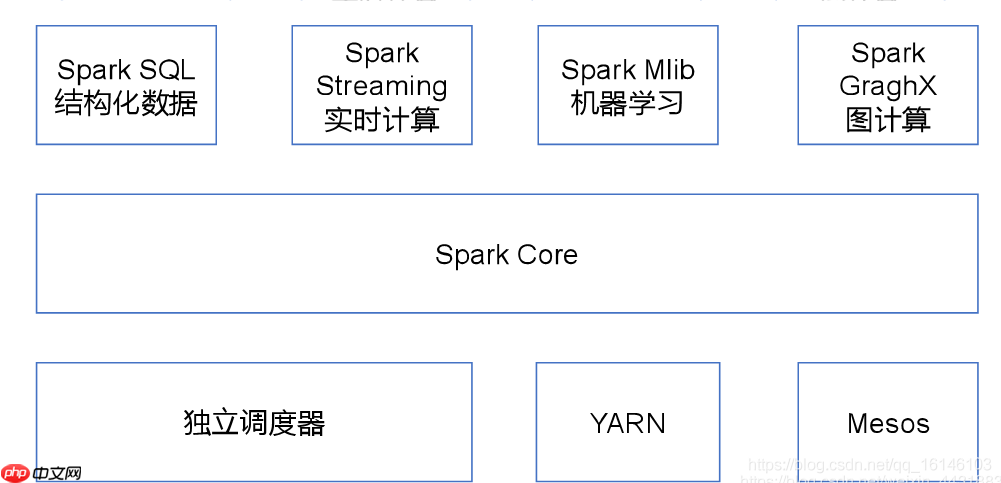
一. Spark Streaming 是什么?Spark Streaming 是 Spark 核心 API 的延伸,用于构建具有弹性、高吞吐量和容错能力的流式处理程序。简而言之,Spark Streaming 用于处理流式数据。
数据可以来自多种来源,如 Kafka、Flume、Kinesis 或 TCP 套接字。接收到的数据可以利用 Spark 的高级操作来处理,特别是那些高阶函数如 map、reduce、join 和 window。
最终,处理后的数据可以发布到文件系统、数据库或在线 dashboard。
此外,Spark Streaming 还可以与 MLlib(机器学习)和 GraphX 完美结合。
 在 Spark Streaming 中,数据处理的单位是一批而非单条,但数据采集是逐条进行的。因此,Spark Streaming 系统需要设置一个间隔,使得数据在达到一定量后进行批处理。这个间隔是批处理间隔,是 Spark Streaming 的核心概念和关键参数,它决定了 Spark Streaming 提交作业的频率、数据处理的延迟,同时也影响数据处理的吞吐量和性能。
在 Spark Streaming 中,数据处理的单位是一批而非单条,但数据采集是逐条进行的。因此,Spark Streaming 系统需要设置一个间隔,使得数据在达到一定量后进行批处理。这个间隔是批处理间隔,是 Spark Streaming 的核心概念和关键参数,它决定了 Spark Streaming 提交作业的频率、数据处理的延迟,同时也影响数据处理的吞吐量和性能。
 Spark Streaming 提供了一个高级抽象:离散化流(DStream),DStream 代表一个连续的数据流。
Spark Streaming 提供了一个高级抽象:离散化流(DStream),DStream 代表一个连续的数据流。
DStream 可以由来自数据源的输入数据流创建,也可以通过在其他 DStream 上应用高阶操作来生成。
在内部,一个 DStream 由一系列 RDD 表示。

Easily find JSON paths within JSON objects using our intuitive Json Path Finder
 193
193

二. Spark Streaming 的特点
 2. 容错性
2. 容错性
 3. 易于整合到 Spark 生态系统中
3. 易于整合到 Spark 生态系统中
 4. 缺点:Spark Streaming 采用“微批处理”架构,与基于“逐条记录处理”架构的系统相比,其延迟相对较高。
4. 缺点:Spark Streaming 采用“微批处理”架构,与基于“逐条记录处理”架构的系统相比,其延迟相对较高。
三. Spark Streaming 架构
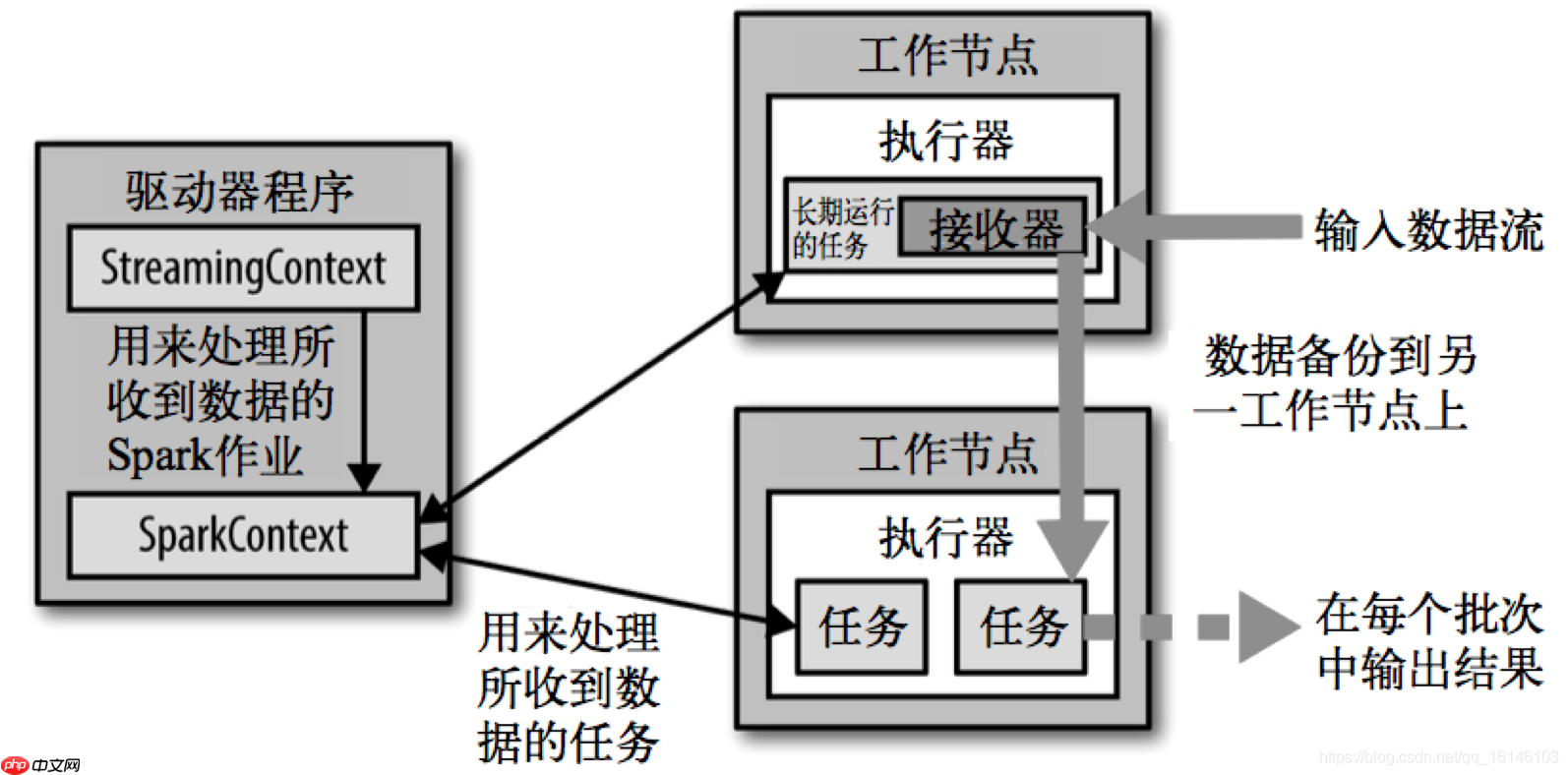 背压机制:在 Spark 1.5 之前的版本中,用户可以通过设置静态配置参数 spark.streaming.receiver.maxRate 来限制 Receiver 的数据接收速率。虽然这种方法可以通过限制接收速率来适应当前的处理能力,防止内存溢出,但也会带来其他问题。例如,当 producer 的数据生产速度高于 maxRate 且当前集群的处理能力也高于 maxRate 时,会导致资源利用率下降等问题。
背压机制:在 Spark 1.5 之前的版本中,用户可以通过设置静态配置参数 spark.streaming.receiver.maxRate 来限制 Receiver 的数据接收速率。虽然这种方法可以通过限制接收速率来适应当前的处理能力,防止内存溢出,但也会带来其他问题。例如,当 producer 的数据生产速度高于 maxRate 且当前集群的处理能力也高于 maxRate 时,会导致资源利用率下降等问题。
为了更好地协调数据接收速率与资源处理能力,Spark Streaming 从 1.5 版本开始可以动态控制数据接收速率以适应集群的数据处理能力。背压机制(即 Spark Streaming Backpressure)根据 JobScheduler 反馈的作业执行信息来动态调整 Receiver 的数据接收率。
通过属性 spark.streaming.backpressure.enabled 来控制是否启用背压机制,默认值为 false,即不启用。
本次分享到此结束。
以上就是Spark Streaming 快速入门系列(1) | Spark Streaming 的简单介绍!的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号





 290
290





















