
8月29日消息,nvidia近期发布了其第二季度财报,业绩持续呈现爆发式增长。备受瞩目的新一代ai显卡blackwell系列中的旗舰型号gb300,预计将在今年第四季度正式上市。与此同时,下一代rubin架构已有6款产品正在规划推进中。
关于GB300的详细规格可参考此前发布的资讯,而更值得关注的是其背后可能引发中美AI技术路线分化的趋势——在算法标准的选择上,国产AI生态与NVIDIA已显现分歧。国内主流选择的是UE8M0 FP8标准,而NVIDIA在Blackwell架构上则重点强化了NVFP4算法标准。
UE8M0 FP8标准近日在国产算力圈内引发热议,起因是Deepseek在发布其3.1版本模型时正式宣布,该标准已全面适配即将面世的新一代国产AI芯片。
尽管未明确点名具体厂商,但包括华为昇腾、摩尔线程、砺算科技、芯原科技、海光科技在内的多家国产芯片企业,其新一代AI算力产品几乎都已支持这一标准。
相较于以往国产AI芯片普遍采用的FP16+INT8组合,UE8M0 FP8带来了显著优势:性能提升可达2至3倍,同时大幅缓解显存压力并有效降低功耗,实际表现将取决于各厂商的具体实现能力。
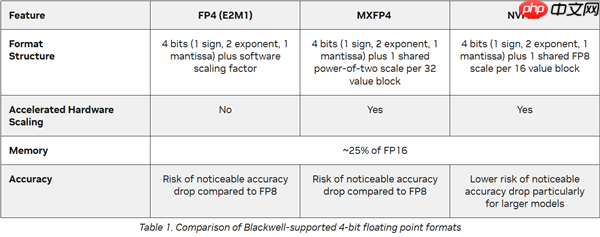
反观AI领域的领军者NVIDIA,与国内由模型厂商牵头推动标准不同,NVIDIA长期以算力上游主导者的身份引领行业,其产品一直兼容FP64、FP32、FP16、INT8、FP8等多种精度标准。在Blackwell架构中,NVIDIA同样支持FP4与MXFP4,但主推的是NVFP4标准,其结构类似于E2M1 FP4,但在精度上几乎没有明显损失。
NVFP4究竟有哪些优势?首先从性能来看,GB300在采用该标准后,稠密计算性能实现了50%的跃升,达到15PFlops,值得注意的是,其核心架构与GB200相比并无根本性变化。

50%的性能提升或许已足够亮眼,但其精度表现更令人关注。
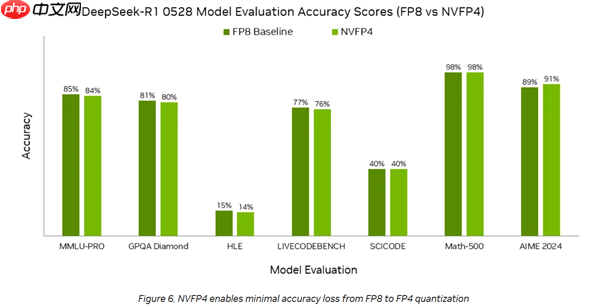
对比FP8基准,NVFP4在DS 0528模型上的精度几乎持平,多数情况下差距不足1个百分点,而在AIME 2024测试中甚至反超2个百分点。
在内存占用方面,NVFP4相比FP16减少了3.5倍,相比FP8也减少了1.8倍。与此同时,GB300的HBM显存容量从GB200的186GB提升至288GB,在NVL72机柜中,系统总内存容量可达40TB,足以支撑3000亿参数以上的大模型运行。
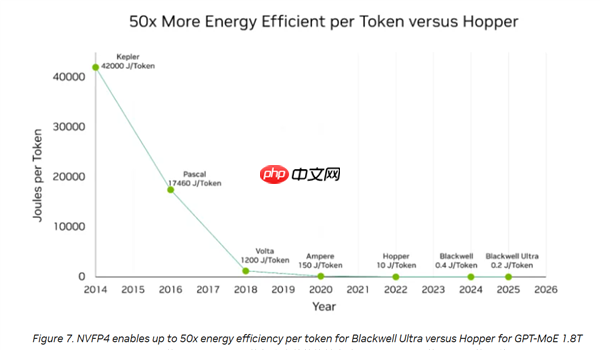
第三大优势体现在能效上。在NVFP4的支持下,GB300每生成一个Token仅消耗0.2焦耳能量,而GB200为0.4焦耳,H100架构的H100则高达10焦耳,能效相较提升达50倍。
综上所述,NVIDIA此次主推的NVFP4标准实现了50%的性能提升,精度与FP8基本持平,内存占用减少2至3倍,能效更是提升了50倍。
凭借NVIDIA在行业内的巨大影响力,NVFP4极有可能成为前沿大模型广泛采纳的标准,国内大型AI企业预计也将大规模采用。
然而,在国产AI芯片阵营中,UE8M0 FP8已成为新一代产品的主流标准。尽管在整体生态上尚难匹敌NVIDIA的CUDA体系,但这标志着国产AI软硬件协同迈出了关键一步,未来仍有机会开辟属于自己的技术路径,一切皆有可能。

以上就是与国产AI分裂 NVIDIA最强AI显卡GB300强化FP4:能效暴增50倍的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号







 277
277























