
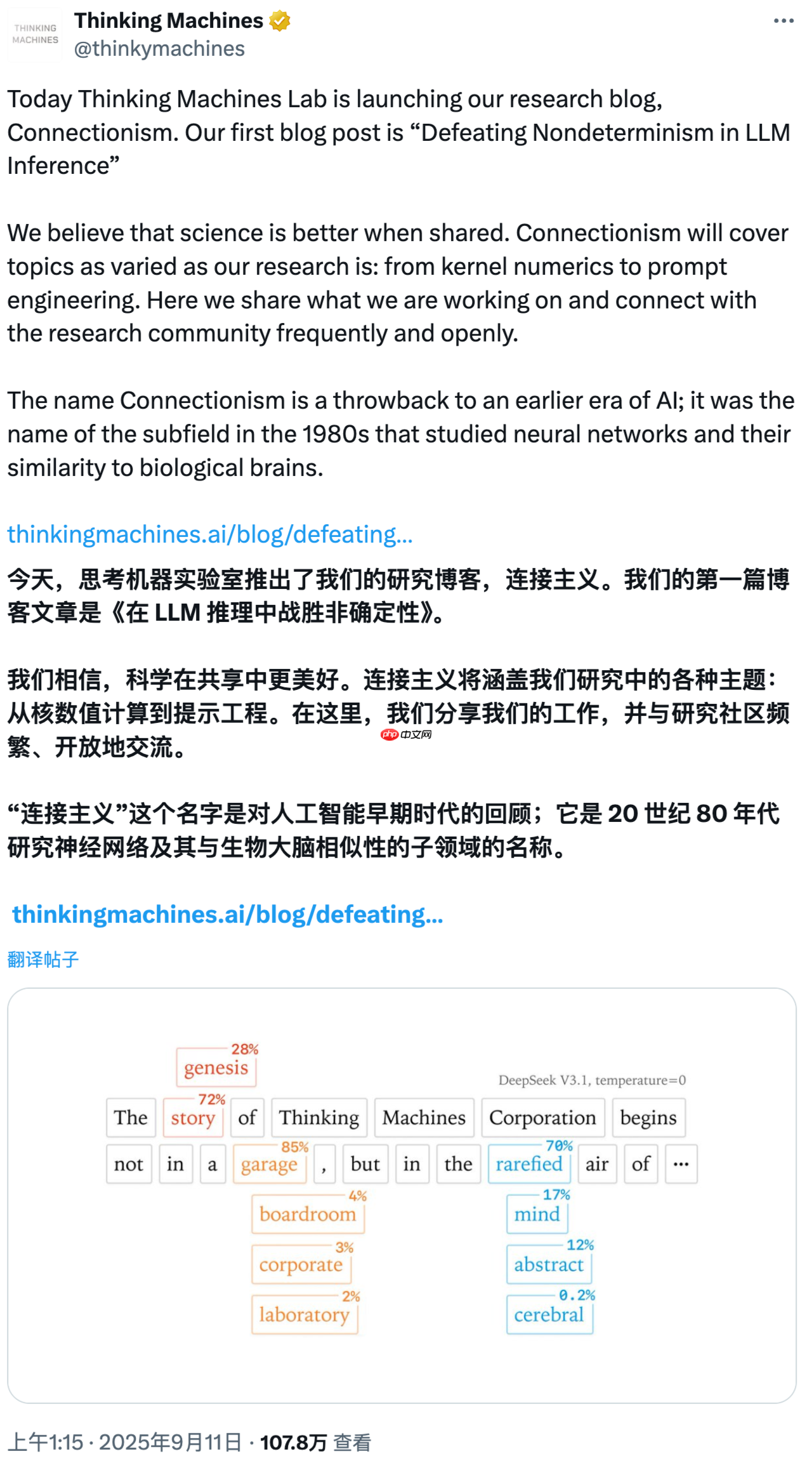
由前 OpenAI 首席技术官 Mira Murati 创立的 Thinking Machines Lab 近日发布了其首篇技术博客:《在 LLM 推理中战胜不确定性》("Defeating Nondeterminism in LLM Inference")。
尽管将大语言模型的温度设置为 0,并使用完全相同的输入、模型和硬件,输出结果仍可能出现差异。这篇博客深入探讨了这一现象背后的原因,并提出了解决方案——如何实现 100% 可重复的大模型推理输出。
文章指出,造成这种不确定性的因素主要有两个:
1. 浮点数加法不具备结合律特性(floating-point non-associativity)
即 (a + b) + c 与 a + (b + c) 在浮点运算中可能产生不同结果。由于并行计算时求和顺序不一致,会引入微小数值偏差。不过,作者认为这并非问题的主要根源。
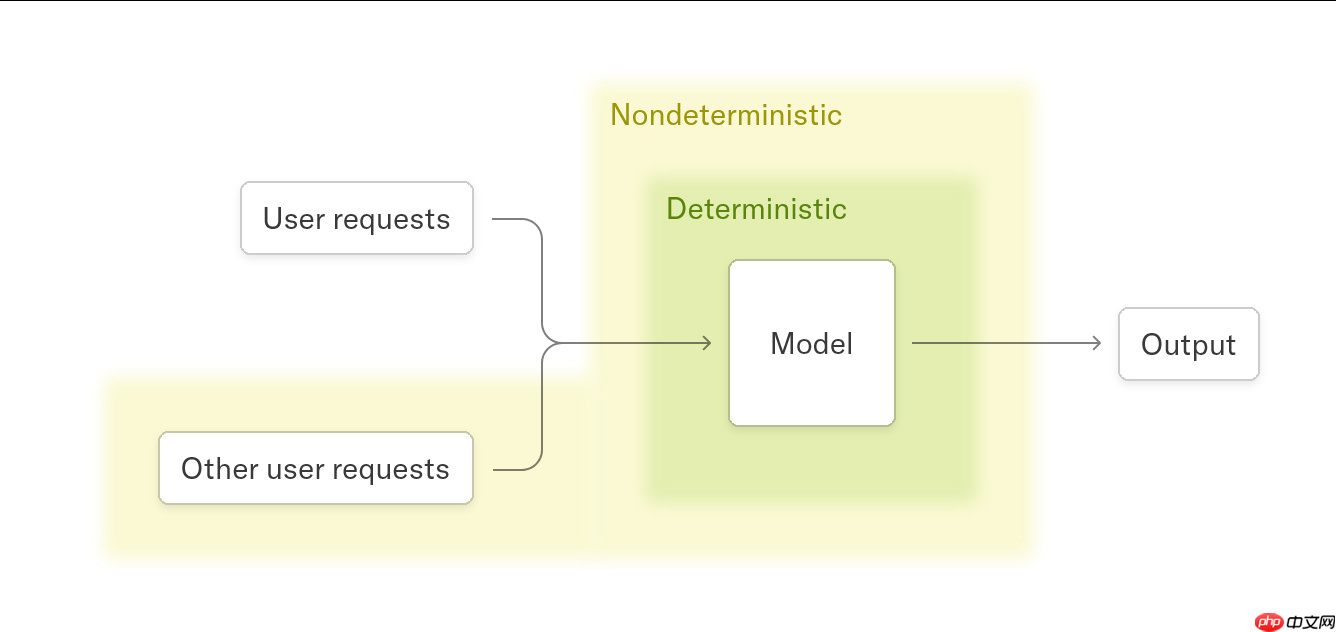
2. 并行计算策略的动态变化(Dynamic Parallelization Strategies)
这是导致输出不一致的核心原因。当 batch size、序列长度或 KV-cache 的状态发生变化时,GPU 内核可能会选择不同的并行执行路径,进而改变计算顺序,最终影响输出结果。
为解决此问题,作者提出必须确保所有关键计算内核(kernel)具备 batch-invariant 特性——无论输入批次大小或序列如何分割,计算过程和结果都应保持完全一致。
针对三大核心组件,团队提出了相应的改进方法:
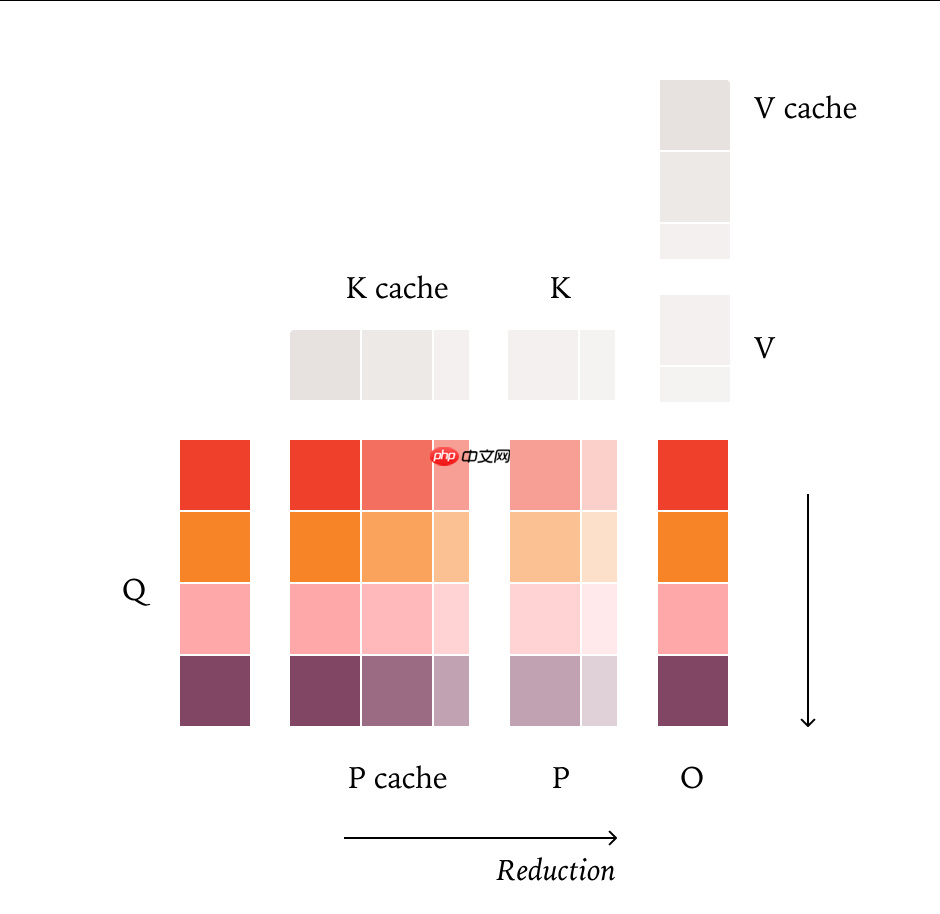
实验部分,研究团队选用 Qwen3-235B-A22B-Instruct-2507 模型进行测试。在应用上述优化后,连续运行 1000 次相同请求,模型每次输出均完全一致,实现了真正意义上的确定性推理。
以上就是Thinking Machines Lab 发文,揭示 LLM 推理过程不确定性的真相的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 359
359






















