
9月11日,摩尔线程正式推出并开源其大模型分布式训练仿真工具simumax v1.0,在显存占用与性能仿真精度方面实现重大突破,同时新增多项核心功能,显著提升对各类模型的兼容性与使用灵活性。
SimuMax是一款专为大语言模型(LLM)分布式训练负载打造的仿真工具,能够为从单张显卡到上万张GPU集群的场景提供高效模拟支持。
该工具无需实际完成整个训练流程,即可高精度预测训练过程中的显存消耗和性能表现,帮助开发者提前评估训练效率,优化资源配置与计算策略。
依托自研的静态分析架构,摩尔线程通过融合成本模型、内存模型以及屋顶模型(Roofline Model),构建出高度精准的训练过程仿真系统。

SimuMax全面支持多种主流分布式并行方式及优化技术,适用于以下典型应用场景:
1、并行策略支持:
数据并行(DP)、张量并行(TP)、序列并行(SP)、流水线并行(PP)、专家并行(EP)
2、优化技术覆盖:
ZeRO-1、完整重计算、选择性重计算、融合内核等
3、目标用户群体:
希望探索最优训练配置以提升效率的研究人员与工程师;
从事AI框架或大模型算法开发的技术团队,可用于调试与性能优化;
芯片设计厂商,用于硬件性能预估与架构迭代参考。
本次发布的SimuMax 1.0版本最突出的升级在于仿真准确性的大幅提升,为用户提供更可信的分析依据。
针对Dense模型和MoE(混合专家)结构,显存使用预测误差稳定控制在1%以内。
实测结果显示,在多种主流GPU平台上,当前最佳性能预测误差持续低于4%。
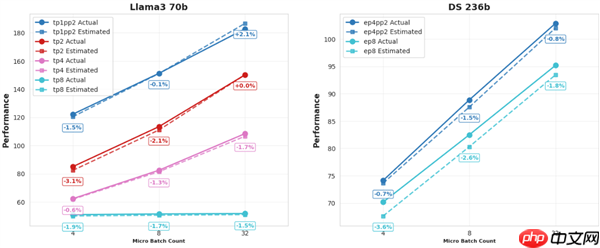
此外,SimuMax 1.0还引入了一系列关键新特性,适配更复杂的模型结构与高效训练需求:
MLA架构支持:
新增对MLA(Multi-Head Latent Attention)模型结构的支持;
增强流水线并行(PP)能力:
支持对模型首层与末层的细粒度划分控制,优化流水线阶段间的负载均衡;
提升MoE灵活性:
在混合专家模型中允许自定义Dense层配置,增强模型设计自由度;
Megatron生态兼容:
提供便捷的模型迁移路径,可快速导入并分析基于Megatron框架构建的模型,强化与现有开发生态的协同能力;
重计算策略精细化:
实现更细粒度的选择性重计算机制,便于在内存节省与计算开销之间进行精确权衡;
全面效率评估功能:
新增对不同张量形状与内存布局下计算效率、资源利用率的深度分析模块。
以上就是摩尔线程发布大模型训练仿真工具SimuMax v1.0:显存误差仅1%的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 233
233





















