
阿里巴巴通义实验室近日正式发布了 funaudio-asr —— 一款面向企业级应用场景的端到端语音识别大模型。该模型不仅具备出色的通用语音识别精度,更通过独创的 context 增强模块,有效应对工业落地中的“语义幻觉”、“多语种混杂”等核心挑战。
其核心技术亮点在于引入了创新性的“Context 模块”,显著提升了在高噪声环境下的识别稳定性与准确性。实测数据显示,模型的幻觉率从原先的78.5%大幅下降至10.7%,降幅接近70%,为行业树立了新的性能标杆。这一突破尤其适用于会议现场、交通枢纽等复杂声学场景。
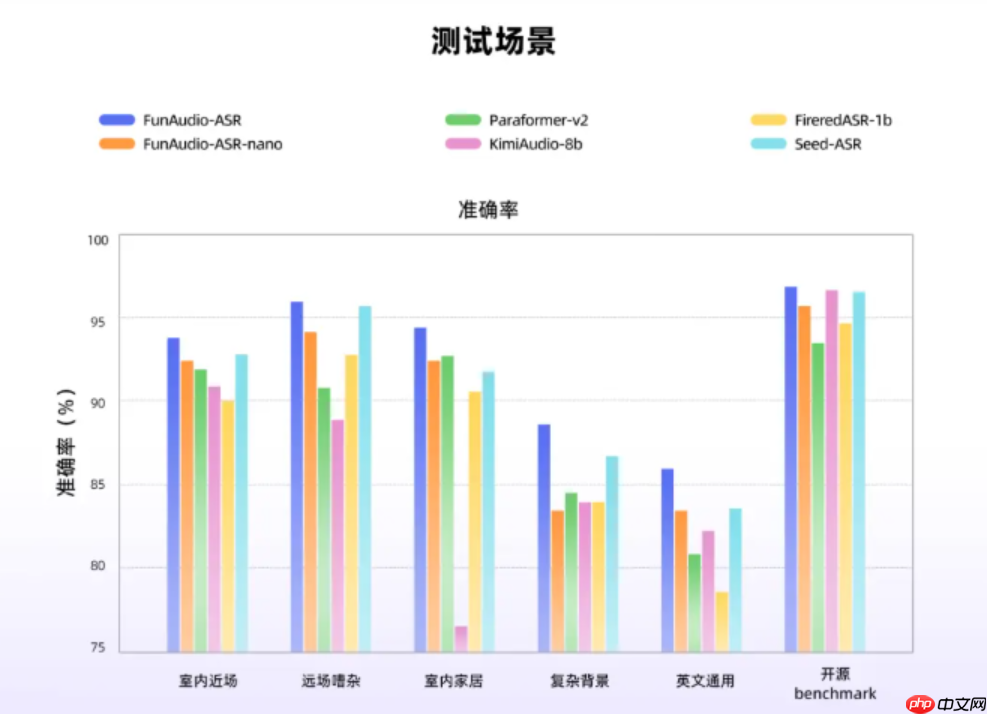
FunAudio-ASR 在训练过程中融合了数千万小时的真实音频数据,并深度整合大语言模型的语义理解能力,使其在远场拾音、背景嘈杂、多人交替发言等典型难题下,表现优于 Seed-ASR、KimiAudio-8B 等主流系统。用户因此可以获得更加清晰、连贯且精准的转录结果。
为满足多样化部署需求,阿里同步推出了轻量版模型 FunAudio-ASR-nano。该版本在保证识别质量的同时,大幅优化了计算资源消耗和推理延迟,特别适合边缘设备或资源受限环境下的快速部署,为企业及中小型开发团队提供了灵活高效的解决方案。

目前,FunAudio-ASR 已成功应用于钉钉“AI 听记”功能、在线视频会议系统以及 DingTalk A1 硬件设备中。同时,其开放 API 已上线阿里云百炼平台,开发者可便捷调用并集成至自有应用。对企业而言,这项技术将显著提升会议记录效率,强化信息捕捉能力,推动智能办公迈向新阶段。

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 674
674





















