



腾讯混元团队近日公布了一项重要技术突破 —— SRPO(Semantic Relative Preference Optimization,语义相对偏好优化),该方法为文生图模型提供了一种高效的强化学习优化方案,成功解决了开源模型Flux在生成人像时常见的皮肤“过油”问题,使人像真实感提升达3倍以上。
针对Flux.dev.1模型输出图像中人物肌肤质感过于油腻的现象,SRPO通过在线调整奖励机制、优化生成过程早期轨迹等手段,有效改善了视觉质量。相比传统方法依赖固定奖励模型的方式,SRPO展现出更强的灵活性和适应性。
在文生图领域,传统的在线强化学习方法如ReFL和DRaFT虽具备较高的训练效率,但严重依赖预先训练的奖励模型。这类模型不仅需要大量标注数据进行训练,成本高昂,且泛化能力有限,难以满足复杂多变的高质量后训练需求。
为此,腾讯混元团队联合香港中文大学(深圳)与清华大学共同提出SRPO,引入语义偏好的动态调节机制,实现对奖励模型的实时优化。
具体而言,SRPO通过向奖励模型注入特定控制提示词(例如“真实感”、“自然肤色”等),引导其关注图像生成中的关键质量维度。实验表明,这些语义信号能显著增强模型在真实度方面的判断能力,从而更精准地指导生成过程。

然而研究人员发现,仅依靠正向语义引导容易引发“奖励破解”现象,即模型可能通过捷径欺骗奖励函数,导致生成结果失真。为此,团队创新性地提出了“语义相对偏好优化”策略:同时使用正向与负向语义提示作为对比信号,利用负向梯度抑制奖励模型的固有偏差,保留真正有意义的语义差异偏好。
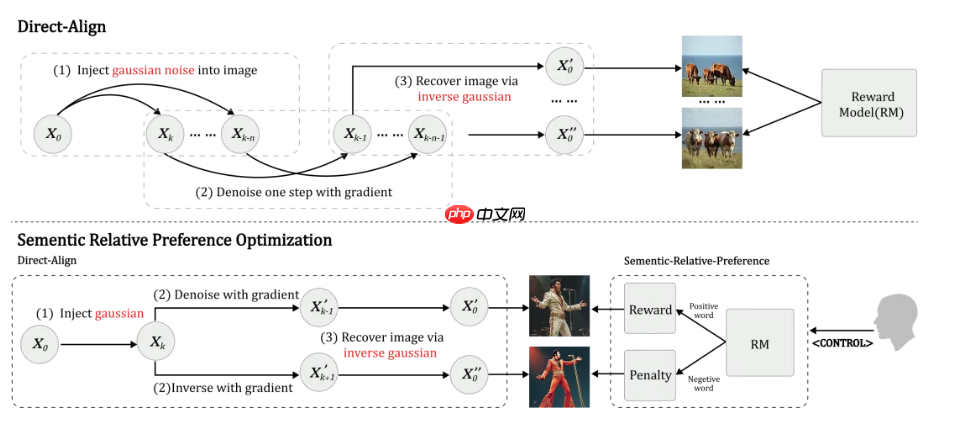
此外,团队还设计了Direct-Align策略,通过对输入图像施加可控噪声,并以该噪声作为“参考锚点”,在单步推理中完成图像重建。这一机制大幅降低了重建误差,提升了奖励信号传递的准确性,使得对生成轨迹前半段的优化成为可能,有效缓解了过拟合问题。

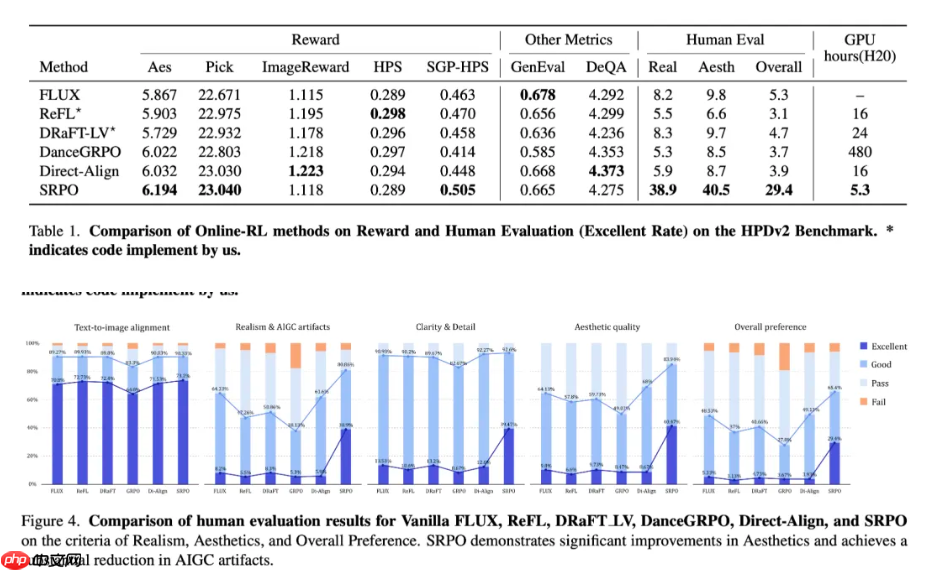
SRPO在训练效率方面表现极为突出,仅需10分钟训练即可超越DanceGRPO的性能表现。

在定量评估中,SRPO达到当前最优(SOTA)水平,人类评审结果显示其在图像真实感与美学质量上的优秀率提升超过3倍,训练耗时相较DanceGRPO减少75倍。

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 1004
1004




















