
前言
2018年11月15日,简书迎来了重大变革,取消了原有的积分制度,转而采用去中心化的简书钻,每天发放一万简书钻。首先,简书详细说明了获取钻石的方式:通过写文和点赞,与过去通过阅读、评论、点赞、关注和写作获取不同数量积分的模式不同,现在的获取方式更为简单和便捷。其次,简书也指出,获取钻石的数量取决于用户的投票(钻石越多,投票权重越大)。简书每天公布前一天的排名,我们将通过编写代码获取2018年11月15日至2018年11月26日的数据,并进行分析。
 为了获取简书钻的排行数据,我们采用了异步加载的爬虫技术,通过包获取数据。数据分为文章排名和用户排名,我们分别编写代码和存储。
为了获取简书钻的排行数据,我们采用了异步加载的爬虫技术,通过包获取数据。数据分为文章排名和用户排名,我们分别编写代码和存储。
 以下是用于获取文章排名的代码:
以下是用于获取文章排名的代码:
import requests
import json
import csv
import time
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
def get_info(url):
res = requests.get(url, headers=headers)
json_data = json.loads(res.text)
notes = json_data['notes']
for note in notes:
title = note['title']
author_nickname = note['author_nickname']
author_fp = note['author_fp']
voter_fp = note['voter_fp']
fp = note['fp']
print(title, author_nickname, author_fp, voter_fp, fp)
writer.writerow([title, author_nickname, author_fp, voter_fp, fp])
if __name__ == '__main__':
fp = open('article.csv', 'w+', encoding='utf-8')
writer = csv.writer(fp)
writer.writerow(['title', 'author_nickname', 'author_fp', 'voter_fp', 'fp'])
urls = ['https://www.jianshu.com/asimov/fp_rankings/voter_notes?date={}'.format(i) for i in range(20181115, 20181127)]
for url in urls:
get_info(url)
time.sleep(1)以下是用于获取用户排名的代码,这部分代码还包括了对用户是否为简书会员的判断:
立即学习“Python免费学习笔记(深入)”;
import requests
import json
import csv
import time
from lxml import etree
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
def get_info(url):
path = 'https://www.jianshu.com/u/'
res = requests.get(url, headers=headers)
json_data = json.loads(res.text)
users = json_data['users']
for user in users:
slug = user['slug']
author_url = path + slug
style = jug_vip(author_url)
author_nickname = user['nickname']
author_fp = user['author_fp']
voter_fp = user['voter_fp']
fp = user['fp']
print(author_nickname, author_url, author_fp, voter_fp, fp, style)
writer.writerow([author_nickname, author_url, author_fp, voter_fp, fp, style])
def jug_vip(url):
res = requests.get(url, headers=headers)
html = etree.HTML(res.text)
infos = html.xpath('//ul[@class="list user-dynamic"]/li')
str = ''
for info in infos:
jug = info.xpath('string(.)').strip()
str = str + jug
if str.find('简书尊享会员') != -1:
return '简书尊享会员'
elif str.find('简书会员') != -1:
return '简书会员'
else:
return '非会员'
if __name__ == '__main__':
fp = open('user.csv', 'w+', encoding='utf-8')
writer = csv.writer(fp)
writer.writerow(['author_nickname', 'author_url', 'author_fp', 'voter_fp', 'fp', 'style'])
urls = ['https://www.jianshu.com/asimov/fp_rankings/voter_users?date={}'.format(i) for i in range(20181115, 20181127)]
for url in urls:
get_info(url)
time.sleep(1)数据分析文章TOP10首先,我们来看看获取简书钻最多的前10篇文章。
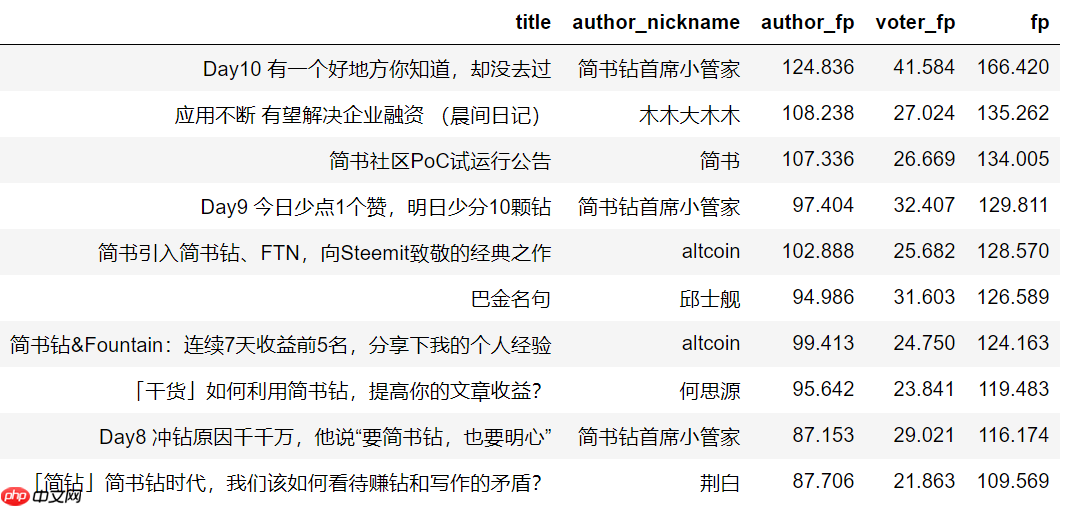 这些文章的内容大多与简书钻的分享有关。由于简书钻是最近才开始运营的,跟随这一热点,文章的曝光率和投票数也会相应增加。
这些文章的内容大多与简书钻的分享有关。由于简书钻是最近才开始运营的,跟随这一热点,文章的曝光率和投票数也会相应增加。
文章词云为了更全面地了解哪些文章容易上榜,我们制作了词云图来分析文章中的关键词。

快速学习python书第二版是一本简洁清晰介绍python3的书籍,目标是新学习python 的程序员。这本更新版本囊括了所有python3版本的变化,即python从早期版本到新版本的特性变化 本书一开始用基础但是很有用的程序来传授给读者关于python的核心特性,包括语法,控制流程和数据结构。然后本书使用大型的应用程序包括代码管理,面向对象编程,web开发和转换老版本的python程序到新的版本等等。 忠实于作者的经验十足的开发者的观众,作者仔细检查普通程序特点,同时增加了更多细节关于这些python
 0
0

 通过关键词,我们可以将它们分为两类:
通过关键词,我们可以将它们分为两类:
初步分析表明,结合热点和自身行业背景,有助于文章上榜(当然,这并不简单)。
用户TOP10仅仅了解文章标题的规律,对于普通人来说,要上榜仍是困难的。接下来,我们通过分析上榜用户来寻找规律。首先是前10名用户。
 这些用户在排行榜上名列前茅,大家可以参考这些用户平时的作品,进行学习。
这些用户在排行榜上名列前茅,大家可以参考这些用户平时的作品,进行学习。
霸屏用户通过12天的数据爬取,我们发现许多用户在这12天内都上了榜,这些霸屏用户让人羡慕。
'书院的夫子', 'linwood', '那個長江', '達士通人', '我是北崖君', '简书钻首席小管家', '宿醉弥生', '乐健君', '思维导图实战派_汪志鹏', 'altcoin', '淡月6688', '临湖风徐徐道来', '小尘2016', '我是四海szw', '中本葱老爷爷', 'weiblock', '蒋坤元', '且行且影', '荆白', '苍天鸭', '脸谱大叔', '肆月初陆', '币圈Tesla', '无戒', '段维Tina', '紫萤石', '陈天宇123', 'Jianan嘉楠', '春木sky', '梦之蓝色', '杀个程序猿祭天', '霖山', '雪球薅羊毛', 'Carykive', '木木大木木', '大琦有钻', '李砍柴', '杰夫1', '写手圈', '静夜思007'
简书会员or非会员前文提到过,获取的钻石数量很大程度上取决于你已拥有的简书钻,而简书尊享会员通常拥有更多的简书钻,这导致上榜用户中,简书会员的比例相当高。
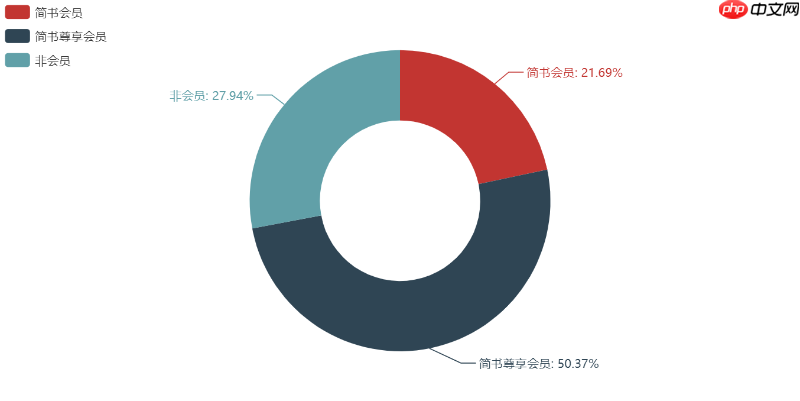 总结结合简书钻的热点来上榜,你是否也考虑成为简书尊享会员呢?当然,自身的努力同样重要,坚持写作,分享干货,这就是简书的精神。
总结结合简书钻的热点来上榜,你是否也考虑成为简书尊享会员呢?当然,自身的努力同样重要,坚持写作,分享干货,这就是简书的精神。
以上就是Python玩转简书钻的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号





 214
214






















