
9月29日,DeepSeek正式推出DeepSeek-V3.2-Exp大模型,距离此前发布DeepSeek-V3.1-Terminus仅过去不久,再次展现了其在重大节点前更新模型的节奏。此次发布的v3.2版本带有“Exp”(Experimental)后缀,表明其主要定位为技术探索性质,并非追求性能全面超越,而是为后续重大升级铺路。
本次更新的核心亮点在于引入了DeepSeek Sparse Attention(DSA),该机制首次实现细粒度稀疏注意力,在几乎不牺牲输出质量的前提下,显著提升了长文本场景下的训练与推理效率,为处理更长上下文和降低计算开销提供了新的技术路径。
尽管V3.2本身属于小步迭代,业界更关注的是传闻中的DeepSeek-V4基座大模型及其可能带来的革命性升级。有推特账号“DeepSeek News Commentary”声称,V4将于10月发布,或将支持高达100万token的上下文长度,采用GRPO驱动推理、NSA/SPCT等新技术,在数学与编程能力上大幅提升,同时具备更快的响应速度和更低的成本。
不过该账号虽位于杭州,但并非官方认证渠道,消息尚未得到证实。尽管如此,10月发布V4并非全无可能——当前V3.2的技术验证正为此积累经验。早在此前,DeepSeek已明确表示下一代模型将支持FP8算法,并全面适配国产AI芯片。
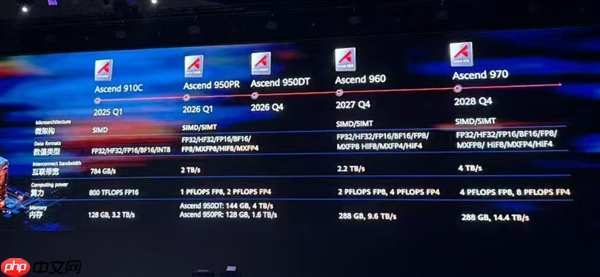
目前,包括华为昇腾、寒武纪、海光信息在内的多家国产芯片厂商均已宣布完成对DeepSeek-V3.2-Exp的适配。特别是华为昇腾,不仅实现了0day支持,还开源了推理代码。结合昇腾近期公布的路线图,预计明年Q1发布的昇腾950PR将支持FP8/FP4等多种精度格式,算力强劲,互联带宽高达2TB/s,内存带宽达4TB/s,堪称国产算力的里程碑产品。

因此,不少观点认为,DeepSeek-V4的最佳亮相时机或与昇腾950PR等先进国产芯片的成熟部署同步。此前已有消息称DeepSeek正在使用国产芯片进行模型训练,V3.2已同时支持CUDA与华为CANN,预示着V4在国产化适配上将更加深入,未来也有望陆续推出针对寒武纪、海光等平台的优化版本。
以上就是DeepSeek V4被曝下月发布:100M上下文 全面用国产AI芯片训练的详细内容,更多请关注php中文网其它相关文章!

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号









 279
279
























