







在之前的强化学习系列中我们介绍了强化学习的基础知识,也在系列十和系列十一中介绍了强化学习rl在llm中的应用。
最近我在介绍DeepResearch Agent的论文分享中讨论过从高质量数据合成,Agentic增量预训练(CPT),有监督微调(SFT)冷启动,到强化学习(RL)全流程的方法。但是介绍过程中重点在数据和论文方案思路框架上,RL算法部分都略过了。因为我发现每篇论文都在使用不同的RL方法,每个都详细介绍篇幅太长,不如将这些RL方法单独做一篇详细聊聊。
PPO在LLM的应用就不用再介绍了,系列十已经聊过,所以本文就介绍一些PPO的优化方案。
GRPO:Group Relative Policy Optimization
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
论文链接:https://arxiv.org/pdf/2402.03300
论文主要介绍的DeepSeekMath 7B的模型,在 MATH 和 GSM8K 等基准测试上超越了参数量更大的闭源模型。而提升的原因除了精心设计的数据工程,另一个重要原因就是引入PPO的优化算法GRPO(Group Relative Policy Optimization ),这种方法不仅提升了数学推理能力,也显著降低了训练过程中的显存占用。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

问题和背景
前文介绍过PPO框架中,我们需要有三个模型:
Actor策略模型:负责实际生成内容,是被优化的策略模型。
Reward Model奖励模型:负责给模型生成的完整输出打分,提供训练时的奖励信号。
Critic评论模型:负责估计当前生成状态的价值,用来计算优势,稳定训练过程。

上面就是PPO的优化目标函数。
PPO 的问题在于:Actor 和 Critic 都是大型神经网络,二者需要同时更新,显存开销大;并且 Advantage 的计算依赖一个学习到的价值函数,训练容易不稳定。
论文方案
GRPO的解决方案就是直接去掉了Critic网络。GRPO的核心创新思路很简单:直接剔除Critic,启用群体相对优势。PPO中Critic存在主要就是为了计算优势函数,而什么是优势呢?就需要用Critic模型的值和奖励函数的值作比较得到,也就是它需要一个base基线。PPO用了模型,GRPO认为不就是要base么,我每次取一批数据,将平均值作为base不就好了。所以,它通过在一个批次(Group)的样本中对奖励进行归一化来计算优势函数。
计算公式: 优势函数 \hat{A}_{i,t} ,被计算为当前奖励与组内平均奖励之差,再除以该组奖励的标准差:
核心代码:
import torchimport torch.nn.functional as Fdef compute_grpo_loss( current_logits: torch.Tensor, old_log_probs: torch.Tensor, ref_log_probs: torch.Tensor, rewards: torch.Tensor, input_ids: torch.Tensor, attention_mask: torch.Tensor, beta: float = 0.04, # KL 惩罚系数 epsilon: float = 0.2, # Clip 范围 group_size: int = 4 # 每组采样的数量 (G)): """ 计算 GRPO Loss (无需 Critic 模型) 参数形状说明: B: Batch Size (Prompts 数量) G: Group Size (每个 Prompt 采样的回答数量) S: Sequence Length V: Vocabulary Size Total Batch = B * G Args: current_logits: [B*G, S, V] 当前策略模型的输出 Logits old_log_probs: [B*G, S] 采样时旧策略的 Log Probs ref_log_probs: [B*G, S] 参考模型 (SFT模型) 的 Log Probs rewards: [B*G] 每个样本的最终奖励值 (标量) input_ids: [B*G, S] 输入的 Token IDs attention_mask: [B*G, S] 掩码 (1为有效token, 0为padding) group_size: int, 必须能被 batch_size 整除 """ rewards = rewards.view(-1, group_size) # --- 核心步骤 1: 计算 Group Relative Advantage --- # 论文公式: A_i = (r_i - mean(r)) / (std(r) + eps) # 在每一组 (Group) 内部计算均值和方差 mean_rewards = rewards.mean(dim=1, keepdim=True) std_rewards = rewards.std(dim=1, keepdim=True) # 计算优势并恢复形状 -> [B*G] advantages = (rewards - mean_rewards) / (std_rewards + 1e-8) advantages = advantages.view(-1) # 优势需要扩展到序列长度维度 [B*G, 1] -> [B*G, S-1] (假设预测的是下一个token) #为了简化代码,假设 mask 处理了 prompt 部分 advantages = advantages.unsqueeze(1) # --- 核心步骤 2: 获取当前策略的 Log Probabilities --- # 使用 gather 获取实际生成 token 对应的 log_prob # Logits: [B*G, S, V] -> LogProbs: [B*G, S] log_probs = F.log_softmax(current_logits, dim=-1) # 获取目标 token 的 log_prob # input_ids 对应的是下一个 token token_log_probs = torch.gather(log_probs, -1, input_ids.unsqueeze(-1)).squeeze(-1) # --- 核心步骤 3: 计算 KL 散度 (用于正则化) --- # 近似 KL: log(\pi) - log(\pi_ref) kl_divergence = torch.exp(ref_log_probs - token_log_probs) - (ref_log_probs - token_log_probs) - 1 per_token_kl = token_log_probs - ref_log_probs # --- 核心步骤 4: PPO Clipping Loss --- # ratio = \pi / \pi_old = exp(log_\pi - log_\pi_old) ratio = torch.exp(token_log_probs - old_log_probs) # PPO Surrogate Loss surr1 = ratio * advantages surr2 = torch.clamp(ratio, 1.0 - epsilon, 1.0 + epsilon) * advantages p_loss = torch.min(surr1, surr2) # --- 核心步骤 5: 组合 Loss --- # Loss = - (PPO_Objective - Beta * KL) # 注意:我们要最大化 Objective,所以 Loss 取负 aux_loss = -beta * per_token_kl total_loss = p_loss + aux_loss # 应用 Mask 并求平均 weighted_loss = total_loss * attention_mask loss = -weighted_loss.sum() / attention_mask.sum() return loss
GRPO是在DeepSeek出圈时受到更多人关注,DeepResearch Agent的论文中WebWatcher,WebSailor-V2,ReSum就是用的GRPO。
DAPO:Decoupled Clip and Dynamic Sampling Policy Optimization
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
论文链接:https://arxiv.org/pdf/2503.14476
DAPO该方法是字节跳动出品,论文为了解决LLM的RL在长思维链场景下遇到的问题而设计的。
Tongyi DeepResearch的WebDancer方法中数据存在Long-CoT,所以采用了 DAPO 算法来优化策略,以增强泛化能力。
问题和背景
论文介绍了经典的PPO:用于策略优化,利用 clip 机制控制更新幅度。
GPRO:在 RLHF/LLM 推理场景中,GRPO利用一组 G 个样本计算 group‑relative reward 值,再做 clip 及 KL 惩罚。
但是,论文指出在长链推理任务中,使用 GRPO 会遭遇一些问题,比如样本级别的 loss 计算方式、KL 散度限制(在推理时可能不必要)。
论文方案
DAPO的四个关键技术:
(1) Clip‑Higher
在PPO 和GRPO中,clip机制限制了策略更新的比率,通常为 1−ε, 1+ε。这种对上界同时做了硬限制,反而抑制了低概率 token的探索,从而导致熵快速坍塌:策略变得过确定、样本缺乏多样性。
比如:如果旧策略对某 token 的概率是 0.01,而 ε=0.2,则 0.01×(1+0.2)=0.012 — 提升空间非常有限;而对一个旧概率为 0.9 的 token,则最多可到 1.08,单其实已经饱和。也就是说,高概率还在强制探索,而低概率的探索token被限得太死。
DAPO提出 Clip‑Higher 策略:将 clip 的上界设得更松,对下界保持原来甚至更严格。也就是说,上界放宽,让低概率 token 有更大提升空间,从而促进多样性与探索。
实验上显示:采用 Clip‑Higher 后,模型的生成熵保持得更高,样本多样性更好,从而提高了任务表现。
(2) Dynamic Sampling
在 RL training 中,当 prompt 很容易(模型几乎都答对)或太难(模型几乎都答错)时,优势会变成零,从而该 prompt 对梯度贡献几乎为零。这导致有效 batch 中“有梯度”的样本越来越少,训练效率下降。
DAPO提出动态采样(Dynamic Sampling)机制:对 prompt 输出结果进行筛选和过滤。对于一个 batch,他们会过采样 prompt,直到收集到一批 “既不是全部正确也不是全部错误” 的 样本。这样每个 batch 都含有有效梯度贡献的样本。
这种方案虽然增加了采样成本,但实际训练时间并没有显著增加,反而由于更有效地利用数据、梯度信号更强,收敛更快。
(3) Token‑Level Policy Gradient Loss
在 GRPO算法中,loss 常在样本级别计算:每个样本先在 token 上平均,然后一个batch上再在样本上平均。但是对于长输出,长样本与短样本在贡献上被同等对待,导致长样本中每个 token 的信号变弱。这会导致模型倾向生成更长、但可能质量差的输出,比如出现冗余的无效token输出。
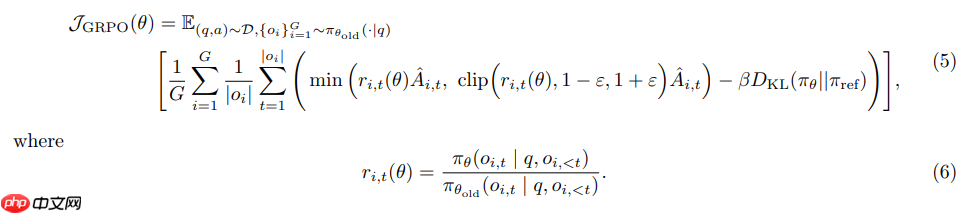
DAPO为了解决这个问题,改为 token‑级别的 loss 计算,把每个 token 看作一个强化学习的决策点,每个 token 都有自己的 policy-gradient 信号,而不是整条序列只用一个优势值。这样在强化过程中,每个token都需要为最终结果承担责任。

DAPO采用 token‑level loss 后,模型的输出长度增长变得健康许多,熵也更稳定。
此外,他们 去掉了 GRPO 中的 KL 散度惩罚项,因为在长 CoT 推理场景中,策略可能合理地从初始模型大幅偏移,KL 限制反而可能抑制探索。
(4) Overlong Reward Shaping
当生成达到最大 token 长度时,传统做法可能直接惩罚或截断。但是作者发现:不恰当的奖励处理(例如,自动惩罚超长输出)会引入大量 奖励噪声,干扰训练稳定性。
DAPO提出两段方案:
Overlong Filtering:对被截断的超长样本,在 loss 计算中“掩蔽”它们
Soft Overlong Punishment:对于超过某长度L_{max}-L_{cache} ,但是小于L_{max} 的输出,按长度惩罚(惩罚随长度增加而增大);若超过则固定 –1 处罚;

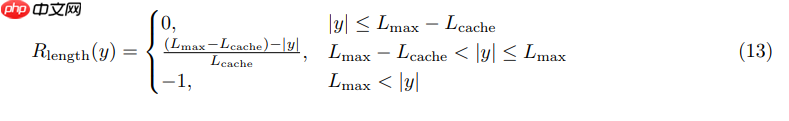
伪代码:

通过这些机制,训练更稳定、输出长度控制更合理。
DUPO:Duplicating Sampling Policy Optimization
WebSailor: Navigating Super-human Reasoning for Web Agent
论文地址:https://arxiv.org/pdf/2507.02592
DUPO是通义在自己的WebSailor 论文中提出的高效的Agent RL 训练算法。DUPO 主要是通过在批次中复制标准差不为 0的样本来填充被移除的样本,以解决 RL 训练速度慢的问题。
问题和背景
DAPO虽然通过动态采样来优化了每个批次的数据,但每个批次内不同样本进行串行 rollout的机制,进一步加剧了训练速度的缓慢,使得在有限时间内进行充分训练变得不切实际。
DAPO等RL在WebAgent的核心问题在于:
稀疏奖励:在WebAgent任务中,一个完整回合可能非常长,多轮交互(迭代的思考 + 工具调用 + 观察 + 推理),真正有价值的信号很稀疏。
采样效率低:标准的RL,尤其是 on-policy 方法,在这种环境里效率非常低,因为每个回合都可能花很多时间,尤其还要web检索,工具又贵又慢,环境的开销非常大。
训练不稳定:如果大部分回合是“非常简单”或“非常困难”,策略优化信号不稳定或方差很大。
论文方案
DUPO 通过整合两种动态采样策略来提高训练的有效性和效率,并进一步完善智能体的推理能力和样本效率。论文指出DUPO方法与 DAPO 的动态采样相比,实现了大约 2 到 3 倍的加速。
DUPO 的具体优化方案:
预训练阶段的样本过滤DUPO 在正式训练之前,首先会过滤掉过于简单的案例。例如,将所有 8 次策略执行(rollouts)都正确的案例筛选出去。
2. 训练阶段的重复采样策略
在训练过程中,DUPO 采取了一种高效的批次填充策略:
移除简单或完全失败的案例: 那些标准差为 0 的案例会被移除。标准差为 0 意味着所有策略执行结果都要么完全正确,要么完全不正确。
动态重复采样: DUPO 不使用填充来扩大批次,而是随机重复同一批次中标准差不为 0 的其他样本来填充被移除的空位。
这种基于标准差的重复采样机制,确保了模型训练专注于那些结果具有不确定性的复杂案例,从而更有效地利用高质量的复杂训练数据。
3. 目标函数策略
策略损失掩码: 与 SFT 类似,在计算策略损失时,将环境的观察结果进行掩码。
优势估计: DUPO 遵循 GPRO 的方法,以组内相对的方式估计优势。
策略梯度损失: DUPO 沿用了token级别损失以及higher clip技术。
奖励机制: 为了避免reward hacking,DUPO 采用了一种结合格式验证(0.1 权重)和答案验证(0.9 权重)的基于规则的奖励机制。格式分数验证策略执行轨迹是否遵循预定义的格式(例如
DUPO通过这种集成方法,WebSailor 能够在强化学习阶段进一步提炼DeepResearch Agent的推理能力,并最终激发其发现和内化复杂问题解决策略的内在潜力,并且在训练速度上有大幅度提升。
GSPO (Group Sequence Policy Optimization)
GSPO:Group Sequence Policy Optimization
论文地址:https://arxiv.org/pdf/2507.18071
GSPO也是通义实验室提出的论文,WebResearcher 项目采用了 GSPO的方案。
问题和背景
随着模型能力与复杂性的提升,例如更长的响应、Mixture‑of‑Experts(MoE)结构等,RL训练变得更加不稳定。论文指出GRPO这种方法训练不稳定问题的根本在于:GRPO 使用 token-level的重要性比率(注意不是token-level的loss和DAPO不要搞混了),但是reward的单位通常是整条 sequence ,这样的不匹配会引入高方差。随着响应长度变长,这种噪声/方差积累严重,对训练极为不利。
此外,对于 MoE 模型 (Mixture-of-Experts),由于结构更复杂(如专家路由、稀疏活跃路径等),训练的稳定性是一个更大的问题。论文指出 GRPO 在这类模型上极不稳定。
论文方案
论文为了解决上诉重要性比率单位和loss的不匹配,以及训练稳定性问题,提出了GSPO(Group Sequence Policy Optimization)。
GSPO的核心思想主要是:
重要性比率的定义GSPO用序列级别的概率来定义重要性比率 (不是 token 级别)。
具体地,对于一个输入 (query) x 和模型生成的响应 (完整序列) y,旧策略 是 {\pi_{\theta_{\text{old}}}(y \mid x)} ,新策略是{\pi_{\theta}(y \mid x)} ,那么重要性比率定义为:
这种定义更符合 重要性采样的基本原理,因为它直接衡量整条序列在新旧策略下的偏差。
优势函数GSPO 使用 group-based (组内) 优势估计:对同一输入 x,生成 G 条响应\{ y_i \}_{i=1}^G ,然后对它们计算回报 r(x,y_i) ,形成组。
对于每条响应 y_i 的优势函数 A_i^b 计算为:
这样的标准化优势使得模型对组内的reward差异敏感,更容易利用这些差异进行优化。
目标函数 (Objective) 和裁剪 (Clipping)和PPO的思路一致,GSPO 使用一个 sequence-level 的clip 机制。

也就是说,对于每条完整response序列,他们对其 “重要性比率 × 优势函数” 做裁剪,防止比率偏离过大引起的不稳定。
相比 GRPO 的 token-level 可能引入高方差,GSPO 更稳定,尤其在训练大模型例如 MoE 时减少崩塌风险。在复杂问题比如WebReasearch中,也用到GSPO提升复杂推理问题的性能和效率。
核心代码:
import torchimport torch.nn.functional as Fdef compute_sequence_likelihood(model, query, response): """ 计算序列似然度 π_θ(y | x) """ input_ids = torch.cat([query, response], dim=1) outputs = model(input_ids=input_ids) logits = outputs.logits # 获取 response 部分的 logits response_log_probs = F.log_softmax(logits, dim=-1)[:, query.size(1)-1:-1, :] token_log_probs = torch.gather( response_log_probs, dim=2, index=response.unsqueeze(-1) ).squeeze(-1) # 序列级别的对数似然度 return token_log_probs.sum(dim=1)def compute_importance_ratio(model, query, response, old_log_probs): """ 计算序列级别的重要性比率 s_i(θ) = π_θ(y_i | x) / π_θ_old(y_i | x) """ current_log_probs = compute_sequence_likelihood(model, query, response) return torch.exp(current_log_probs - old_log_probs)def compute_normalized_advantages(rewards): """ 计算归一化优势 Ã_i = (r_i - mean(r)) / std(r) """ mean_reward = rewards.mean(dim=-1, keepdim=True) std_reward = rewards.std(dim=-1, keepdim=True).clamp(min=1e-8) return (rewards - mean_reward) / std_rewarddef gspo_loss(model, queries, responses, old_log_probs, rewards, clip_range=0.2): """ GSPO 核心损失函数 J = E[min(s_i * A_i, clip(s_i, 1-ε, 1+ε) * A_i)] """ # 计算重要性比率 importance_ratios = [] for i, response in enumerate(responses): old_log_prob = old_log_probs[:, i] if old_log_probs.dim() > 1 else old_log_probs ratio = compute_importance_ratio(model, queries, response, old_log_prob) importance_ratios.append(ratio) importance_ratios = torch.stack(importance_ratios, dim=1) # [batch, group_size] # 计算归一化优势 advantages = compute_normalized_advantages(rewards) # [batch, group_size] # 序列级别裁剪 clipped_ratios = torch.clamp(importance_ratios, 1.0 - clip_range, 1.0 + clip_range) objective = torch.min( importance_ratios * advantages, clipped_ratios * advantages ) return -objective.mean()




























