
✍ 前面几章我们已经把“大模型架构四件套”(gqa / rope / swiglu / rmsnorm)和 deepseek 系列摸了个大概,知道了一个 llm 从参数形状到注意力细节是怎么设计的。但在实际工程项目中,当我们直接丢给用户一个“只做 next-token prediction 的预训练模型”,它大概率会:胡说八道(hallucination)、不听指令,答非所问、安全性、价值观、风格都不可控。
为了让模型的输出更加符合我们的需求,InstrcutGPT提出了人类偏好训练(RLHF),在【大模型学习 | SFT & PPO原理&代码实现】-PHP中文网开发者社区-PHP中文网文章中也详细描述了具体的训练过程,感兴趣的读者可以前往阅读:
后训练(Post-training) = SFT + 偏好对齐(RLHF / DPO / ...)
所以从 “会说话”到“会听话 + 懂规矩”,中间还差一整块流程——这就是我们本章要讲的:
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

在这一章中,主要讲解后训练的具体内容。
前面我们说过:预训练模型只会做 next-token prediction,本质上就是一个“通用语言模型”,并不知道什么是“指令”“任务”“风格”和“安全边界”。
所以工业界基本都会先对预训练模型进行SFT监督微调,让它先变成一个“懂指令的 ChatBot”**。
在 SFT 中,我们会构造大量形如:
<code class="python"><System> 你是一个有帮助的 AI 助手。<User> 请用通俗的话解释一下注意力机制。<Assistant> 注意力机制可以理解为……</code>
的指令-回复(Instruction–Response)数据,让模型学习:
用户说话是<user></user> 段;模型应该在 <assistant></assistant> 段里 接着往下写。在工程里常见的标注格式(以 Chat 风格为例):
<code class="json">{ "prompt": "<s>[SYSTEM] 你是一个有帮助的 AI 助手。[USER] 请解释一下 DPO 是什么?[ASSISTANT]", "answer": "DPO(Direct Preference Optimization)是一种不用 PPO 就能做偏好对齐的方法,它通过……"}</code>训练时会把 prompt + answer 拼起来喂给模型,并构造 labels:
数学上依然是标准的交叉熵损失:
\mathcal{L}_{\text{SFT}} = - \sum_{t \in \text{assistant tokens}} \log \pi_\theta\big(y_t \mid y_{ 其中 x 是 system+user 内容,y_{1:T} 是 assistant 的回答。 预训练学的是“语言分布”,后训练学的是“人类偏好 + 任务风格” 阶段 训练目标 数据来源 直观理解 预训练 Pretrain 下一个 token 概率(LM Loss) 海量网络文本 / 代码 “把所有语料读一遍,学会说话” SFT 模仿人类写的高质量回答 人工标注 / 高质量指令数据 “学会按指令答题” 偏好对齐(RLHF / DPO) 对人类偏好 / 打分进行优化 人类比较、偏好标注 “学会什么是更好的回答” ✅ 面试可以顺带强调两点: 于是 InstructGPT 提出了经典三步的 RLHF(Reinforcement Learning from Human Feedback)。 1️ 2️ ? 3️ 在传统的PPO场景中,加入KL散度是为了防止学习过偏,导致与采样数据的分布不一致。RLHF 只是把这个想法显式化,并把 KL penalty 直接放进了 reward shaping,而不是像原始 PPO 那样只放在优化目标的正则项里。假设没有 KL penalty,PPO 会不断调整 policy,使得输出 y 得到 RM 尽可能高的分数。这可能导致模型生成异常答案(gaming the reward)而不是合理回答。 伪代码层面长这样(不用细抠每一个 PPO 步骤,重点是流程): RLHF 最大的问题之一就是:工程复杂度高——要训练 RM、要搞 PPO、要处理 KL、还要稳定采样和优势估计。DPO(Direct Preference Optimization) 的想法非常“直男”: DPO 的出发点是:在理想情况下,如果存在某个“真实” reward 函数 r(x, y) ,那么最优策略满足: \pi^*(y \mid x) \propto \pi_{\text{ref}}(y \mid x)\,\exp(\beta r(x, y)) 将这玩意儿反解一下,可以得到偏好数据上的对比 loss,不再显式用 RM,而是直接训练策略模型本身 πθ\pi_\thetaπθ。 对于一个 triple (x, y^+, y^-) (同一个 prompt 的好坏回答对),DPO 的 loss 类似于: \mathcal{L}_\text{DPO}(\theta) = - \log \sigma\Big( \beta \big(\log\pi_\theta(y^+\mid x) - \log\pi_\theta(y^-\mid x)\big) - \beta \big(\log\pi_{\text{ref}}(y^+\mid x) - \log\pi_{\text{ref}}(y^-\mid x)\big) \Big) 直觉上就是: 优点: 缺点: 训练循环就和普通 supervised 差不多: ⭕ 在RLHF中提到了,RL想得到 G_t ,必须先把整条序列 roll 出来,到达最后一个token时才可以得到RM的奖励。这无疑加大价值函数的训练难度。并且,价值函数的大小往往与critical model大小近似,有较大的显存负担。传统 RLHF 里,Reward Model 多数是输入: 然后给一个标量分数: 这就导致: 为此,Deepseek 团队提出了 其中,优势函数不再是通过价值函数计算,而是通过在组内基于相对奖励来计算,避免训练价值函数。 除此之外,在目标损失中,GRPO还修改了KL散度的计算,通过只计算一个采样到的 token就能估计 KL。传统的KL散度计算需要通过计算所有的token,增加优势计算复杂度。 和 PPO 很像,只是 没有 value 网络,每次更新前记得拷一份旧策略: 这一章,我们把“后训练”这一坨东西拆成了四个关键词:? 1. 预训练 vs 后训练 的区别?
? SFT 手撕代码
<code class="python">import torchimport torch.nn as nnclass SimpleDecoderLM(nn.Module): def __init__(self, vocab_size, d_model): super().__init__() self.embed = nn.Embedding(vocab_size, d_model) # 这里只写个占位,实际应替换为 TransformerBlock 堆叠 self.block = nn.Linear(d_model, d_model) self.lm_head = nn.Linear(d_model, vocab_size, bias=False) def forward(self, input_ids, labels=None): """ input_ids: [B, L] labels : [B, L], 非 assistant token 位置 = -100 """ x = self.embed(input_ids) # [B, L, D] h = torch.tanh(self.block(x)) # 简化:假的 Transformer logits = self.lm_head(h) # [B, L, V] loss = None if labels is not None: loss_fct = nn.CrossEntropyLoss(ignore_index=-100) loss = loss_fct( logits.view(-1, logits.size(-1)), # [B*L, V] labels.view(-1) # [B*L] ) return logits, loss</code>
<assistant></assistant> 段算 loss(为什么要 ignore_index=-100);SFT 后模型对“指令形式”的拟合会明显变好,但还没对齐人类偏好(安全性、详略程度、风格等)。二、RLHF:从“会模仿”到“会迎合人类偏好”
SFT只能让模型模仿标注者写的好答案,有两个天然限制:⃣ pre-RM: 在对GPT-3做一次SFT(在一个已经预训练好的大模型(base model,比如 GPT、LLaMA、Falcon)上,再用人工标注的任务数据进行一次监督训练。)后,对SFT后的模型进行输出头替换,从原来的输出的词概率替换为reward标量。⃣ RM: 在之前的RM模型中,是采用pairwise logistic loss对两个回答进行打分评价;作者为了加快对比,做了4-9个输出的对比。作者又提出因为每个回答都是对应了同一个输入,如果直接打乱喂到模型中,模型容易记住pair对,导致过拟合。因此作者是将同一个输入下的所有回答一次性作比较,学到的是“整体排序规律”,而不是死记单个样本的差异,但实际上训练还是两两比较。最后使用偏差对奖励模型进行规范化,以便在进行强化学习之前标记器演示达到平均得分0。
⃣ RL: policy model为175B模型,critic model为训练好的RM模型直接初始化。每一个token的生成就相对于每次行动,因此在每次token生成时计算KL散度散度并累积。LLM PPO场景下,与传统场景不同的是,RL想得到 G_t,必须先把整条序列 roll 出来,到达最后一个token时才可以得到RM的奖励,再从后往前回传。传统模型每个状态都可以进行优势函数的计算。
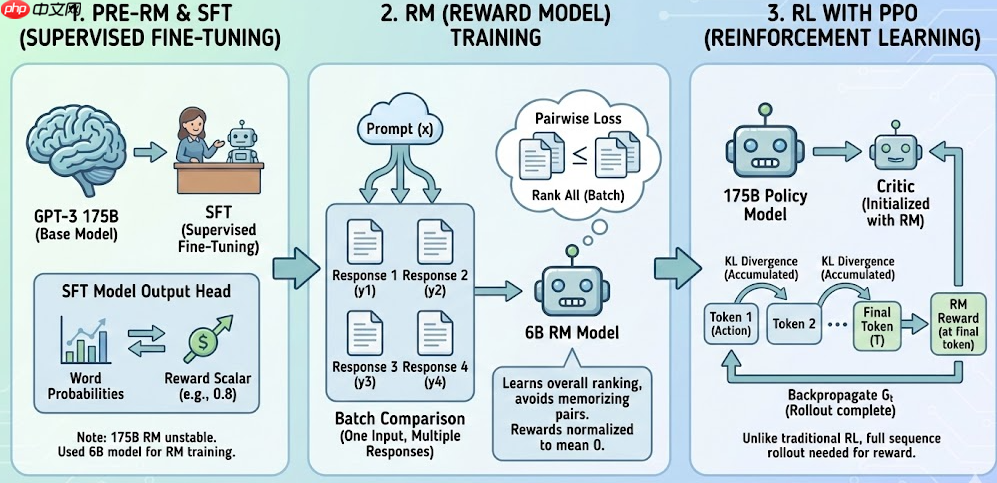
? RLHF 训练代码
<code class="python"># policy_model: 当前策略 π_θ# ref_model : 冻结的 SFT 模型 π_ref# reward_model: RM, 给出标量奖励for batch in prompt_loader: prompts = batch["input_ids"] # [B, L_prompt] with torch.no_grad(): # 1. 用当前策略生成回答 + logprob responses, logprobs = policy_model.generate_with_logprobs(prompts) # logprobs: [B],每个样本完整回复的 log π_θ(y|x) # 2. 参考策略 logprob(用于 KL) ref_logprobs = ref_model.logprob(prompts, responses) # [B] # 3. Reward Model 评分 rewards = reward_model.score(prompts, responses) # [B] # 4. KL 惩罚 kl = logprobs - ref_logprobs # [B] final_reward = rewards - beta * kl # [B] # 5. 基于 final_reward 做 PPO 更新(省略优势函数 & clipping 细节) ppo_loss = compute_ppo_loss( policy_model, prompts, responses, old_logprobs=logprobs.detach(), rewards=final_reward ) ppo_loss.backward() optimizer.step() optimizer.zero_grad()</code>
三、DPO:不用 PPO 的偏好对齐
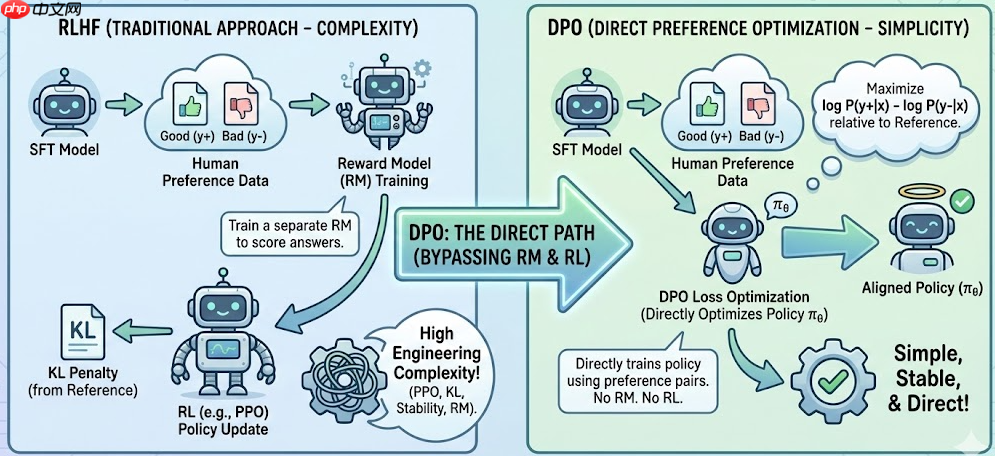
? 2:DPO 相比 RLHF / PPO 有什么优缺点?
? DPO 代码实现
<code class="python">def logprob_sequence(model, input_ids, labels): """ 计算模型对完整序列的 log π(y|x), 这里简单把所有非 -100 的 token 的 logprob 累加。 """ logits, _ = model(input_ids, labels=None) # [B, L, V] logprobs = torch.log_softmax(logits, dim=-1) # [B, L, V] # labels: [B, L], 非预测位置 = -100 mask = (labels != -100) gathered = logprobs.gather(-1, labels.unsqueeze(-1)).squeeze(-1) # [B, L] seq_logprob = (gathered * mask).sum(dim=-1) # [B] return seq_logprobdef dpo_loss(policy_model, ref_model, batch, beta=0.1): """ batch: prompt_ids: [B, Lp] pos_ids : [B, Lp+L+] (prompt+优答案) neg_ids : [B, Lp+L-] (prompt+劣答案) pos_labels: [B, Lp+L+] (非预测位=-100) neg_labels: [B, Lp+L-] """ # 当前策略在好/坏回答上的 log π_θ logp_pos = logprob_sequence(policy_model, batch["pos_ids"], batch["pos_labels"]) logp_neg = logprob_sequence(policy_model, batch["neg_ids"], batch["neg_labels"]) # 参考策略(SFT 模型)在好/坏回答上的 log π_ref with torch.no_grad(): logp_pos_ref = logprob_sequence(ref_model, batch["pos_ids"], batch["pos_labels"]) logp_neg_ref = logprob_sequence(ref_model, batch["neg_ids"], batch["neg_labels"]) # DPO 核心项 # Δ = [logπθ(y+) - logπθ(y-)] - [logπref(y+) - logπref(y-)] delta = (logp_pos - logp_neg) - (logp_pos_ref - logp_neg_ref) # binary logistic loss loss = -torch.log(torch.sigmoid(beta * delta)).mean() return loss</code>
<code class="python">for batch in dpo_dataloader: loss = dpo_loss(policy_model, ref_model, batch, beta=0.1) loss.backward() optimizer.step() optimizer.zero_grad()</code>
四、GRPO:从“答案对不对”到“过程好不好”
Group Relative Policy Optimization (GRPO),使用多个采样输出的平均奖励。具体来说,对于同一个question, GRPO 从old policy model中sample了多个输出,并最大化目标? GRPO 代码实现
policy_model:当前要更新的 LLM(Decoder-only),带 forward 和 generate_with_logprobsref_model:冻结的 SFT 模型,用来算 KL(也可以不用)reward_fn:给完整回答一个标量奖励(RM 或 rule-based 都可以)1️⃣ 计算一条回答的 log π(y|x)
<code class="python">import torchimport torch.nn as nnimport torch.nn.functional as Fdef sequence_logprob(logits, labels): """ 计算模型对完整序列的 log π(y|x) logits: [B, L, V] labels: [B, L], 非预测位置 = -100(比如 prompt 段) 返回: [B],每条样本的 logprob 之和 """ logprobs = F.log_softmax(logits, dim=-1) # [B, L, V] # 只在 labels != -100 的位置取 logprob mask = (labels != -100) # [B, L] # gather: 取出每个 token 的 logprob token_logprobs = logprobs.gather(-1, labels.unsqueeze(-1)).squeeze(-1) # [B, L] token_logprobs = token_logprobs * mask # [B, L] seq_logprob = token_logprobs.sum(dim=-1) # [B] return seq_logprob</code>
2️⃣ 单步 GRPO 更新
<code class="python">class GRPOConfig: def __init__(self, group_size=4, clip_range=0.2, kl_coef=0.01, eps=1e-8): self.group_size = group_size # 每个 prompt 多少条回答 self.clip_range = clip_range # PPO clipping self.kl_coef = kl_coef # KL 正则系数 self.eps = eps # 数值稳定用def grpo_step( policy_model, old_policy_model, ref_model, reward_fn, batch_prompts, cfg: GRPOConfig, max_new_tokens=128,): """ policy_model : 当前策略 π_θ,要更新 old_policy_model : 冻结一份旧策略 π_old,用于 importance sampling ref_model : 冻结的 SFT / 参考策略 π_ref(算 KL 用,也可以为 None) reward_fn : 给完整回答打分的函数: reward_fn(prompt_ids, response_ids) -> [B*G] batch_prompts : [B, L_prompt] 当前这一批的 prompts cfg : GRPOConfig max_new_tokens : 最长生成长度 """ device = batch_prompts.device B, Lp = batch_prompts.shape G = cfg.group_size # ===================================================== # 1. 用 old_policy_model 对每个 prompt 采样 G 条回答 # 这里假设你有 generate_with_logprobs 工具函数 # ===================================================== all_input_ids = [] # prompt + response 的完整序列 all_labels = [] # 对应的 labels(prompt 段 = -100,只训练 assistant 段) all_logprob_old = [] # π_old(y|x) 的 logprob for i in range(B): prompt = batch_prompts[i:i+1] # [1, Lp] for g in range(G): # 假设这个函数返回: # full_ids: [1, Lp+Lr] (prompt + response) # labels: [1, Lp+Lr] (prompt 位置 = -100, response = token_id) # logprob: [1] (整条回答的 log π_old(y|x)) full_ids, labels, logprob = old_policy_model.generate_with_logprobs( prompt, max_new_tokens=max_new_tokens ) all_input_ids.append(full_ids) all_labels.append(labels) all_logprob_old.append(logprob) # 拼成 batch 形式 input_ids = torch.cat(all_input_ids, dim=0).to(device) # [B*G, L] labels = torch.cat(all_labels, dim=0).to(device) # [B*G, L] logprob_old = torch.cat(all_logprob_old, dim=0).to(device) # [B*G] # ===================================================== # 2. 计算 reward,并按 group 做标准化,得到 advantage # ===================================================== with torch.no_grad(): # reward_fn 可以内部用 RM / 规则 / 程序混合 rewards = reward_fn(input_ids, labels) # [B*G] rewards = rewards.view(B, G) # [B, G] mean_r = rewards.mean(dim=1, keepdim=True) # [B, 1] std_r = rewards.std(dim=1, keepdim=True) # [B, 1] adv = (rewards - mean_r) / (std_r + cfg.eps) # [B, G] adv = adv.view(B * G) # [B*G] # ===================================================== # 3. 用当前 policy_model 重新算 log π_θ(y|x) # ===================================================== logits, _ = policy_model(input_ids, labels=None) # [B*G, L, V] logprob_curr = sequence_logprob(logits, labels) # [B*G] # importance sampling ratio ratio = torch.exp(logprob_curr - logprob_old) # [B*G] # PPO-style clip unclipped = ratio * adv clipped = torch.clamp(ratio, 1.0 - cfg.clip_range, 1.0 + cfg.clip_range) * adv policy_loss = -torch.mean(torch.min(unclipped, clipped)) # ===================================================== # 4. 可选:与 ref_model 的 KL 正则(防止偏离 SFT 太远) # ===================================================== kl_loss = torch.tensor(0.0, device=device) if ref_model is not None and cfg.kl_coef > 0: with torch.no_grad(): ref_logits, _ = ref_model(input_ids, labels=None) # [B*G, L, V] logprob_ref = sequence_logprob(ref_logits, labels) # [B*G] # 简化:用 sample-level KL 近似:KL ≈ E[logπθ - logπref] kl_loss = (logprob_curr - logprob_ref).mean() loss = policy_loss + cfg.kl_coef * kl_loss return loss, { "policy_loss": policy_loss.detach(), "kl_loss": kl_loss.detach(), "reward_mean": rewards.mean().detach(), "adv_abs_mean": adv.abs().mean().detach(), }</code>3️⃣ 训练主循环
<code class="python">optimizer = torch.optim.AdamW(policy_model.parameters(), lr=1e-6)cfg = GRPOConfig(group_size=4, clip_range=0.2, kl_coef=0.01)for epoch in range(num_epochs): for batch in prompt_dataloader: prompts = batch["input_ids"].cuda() # [B, L_prompt] # 1. 冻结一份 old_policy(也可以每 N 步更新一次) old_policy_model.load_state_dict(policy_model.state_dict()) old_policy_model.eval() # 2. 单步 GRPO 更新 loss, info = grpo_step( policy_model=policy_model, old_policy_model=old_policy_model, ref_model=ref_model, # SFT 模型,可选 reward_fn=reward_fn, # 你自己实现的 RM / 规则奖励 batch_prompts=prompts, cfg=cfg, max_new_tokens=128, ) loss.backward() optimizer.step() optimizer.zero_grad() # 3. 打一点日志 print(f"loss={loss.item():.4f} " f"R={info['reward_mean']:.3f} " f"|A|={info['adv_abs_mean']:.3f} " f"KL={info['kl_loss']:.4f}")</code>五、总结

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 792
792





















