
定义
大语言模型对比是通过技术指标(参数量、多模态能力)、商业指标(成本、部署方式)和场景适配度(行业解决方案、合规性),系统性评估不同模型的优劣势,帮助用户选择最佳工具。
目的与意义
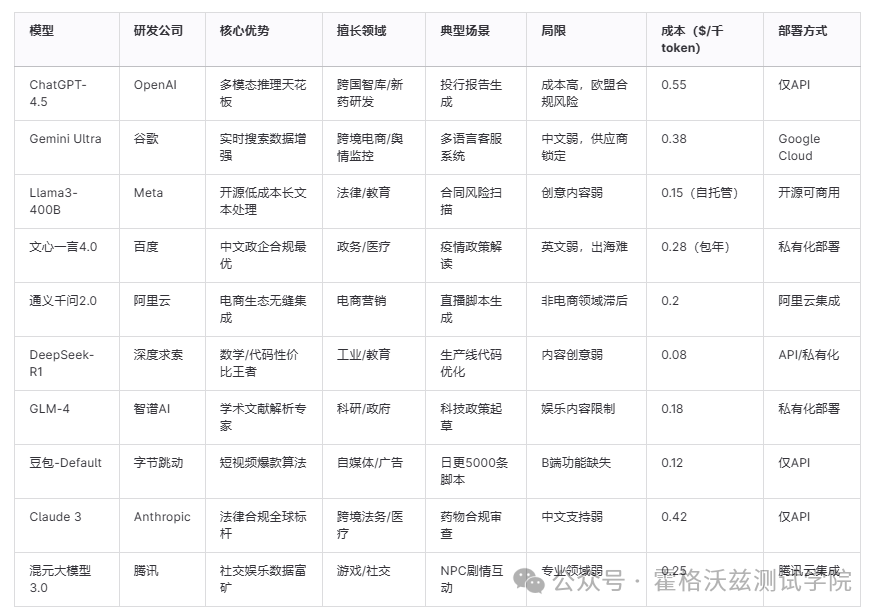
1.OpenAI:ChatGPT-4.5

2.谷歌:Gemini Ultra

3.Meta:Llama3-400B

成本革命: 自托管推理成本仅为GPT-4的1/3,长文本处理效率提升40%。
分层稀疏化架构: 训练所需算力资源减少60%。
创意短板: 生成内容缺乏情感张力,难以替代人类编剧。
盈利困境: 开源模式下企业级支持薄弱。
4.百度:文心一言4.0

中文领域霸权: 行业知识库涵盖医疗、能源、政务等垂直领域。
安全审计API: 嵌套政府监管接口,自动过滤敏感内容。
英文短板: 技术文档处理错误率超30%。
出海限制: 受地缘政治影响,难以拓展国际业务。
5. 阿里云:通义千问2.0

电商场景霸主: 直播脚本生成、竞品舆情分析准确率超90%。
阿里云无缝集成: 一键调用云计算、支付、物流接口。
通用知识滞后: 非电商领域知识库更新周期长达3个月。
创意平庸: 营销文案缺乏爆款基因。
6. 深度求索:DeepSeek-R1

数学/代码优化: 解方程准确率98%,工业软件接口兼容性最佳。
极致性价比: API成本仅为GPT-4的1/7。
内容创意弱: 社交媒体文案生成效果垫底。
生态孤立: 缺乏云计算巨头支持。
7. 智谱AI:GLM-4

研发背景: 清华系团队主导,2025年学术领域占有率第一。
核心优势:
学术文献解析: 支持中英文论文摘要生成,准确率超95%。
私有化部署: 支持国产算力卡,满足政府保密要求。
局限:
娱乐内容限制: 自动过滤“低俗”表述,限制创意自由度。
商业化慢: 企业级功能迭代滞后。
擅长领域: 科研机构论文润色、政策报告撰写。
典型场景: 中科院用于生成国家科技战略草案。
8. 字节跳动:豆包-Default

爆款算法: 内置热点追踪模型,短视频脚本爆款率超同业2倍。
多平台适配: 一键生成抖音、小红书、B站多平台内容。
B端经验不足: 企业定制化功能缺失。
长文本弱: 处理超2000字文档时逻辑混乱。
9. Anthropic:Claude 3
长文本记忆: 支持10万token上下文,合同审查完整率100%。
合规性王者: 内置欧盟GDPR、美国HIPAA合规模块。
中文支持弱: 中文语料占比不足15%,错误率较高。
封闭生态: 仅提供API接口,无法私有化部署。
10. 腾讯:混元大模型3.0

社交数据富矿: 调用微信社交语料,生成“网感”最强内容。
游戏NPC交互: 实时生成剧情对话,玩家留存率提升25%。
专业领域弱: 金融、医疗等场景错误率超40%。
商业化保守: 主要服务内部业务,开放接口有限。
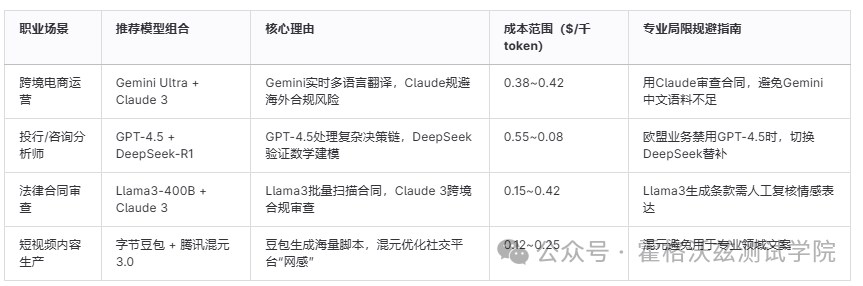
核心逻辑:从业者需根据行业属性、岗位职责、预算水平选择模型组合,拒绝“一刀切”方案。
1. 职业场景分析模型匹配表
2. 典型从业者决策路径
案例1:跨境电商创业者
需求: 低成本生成多语言文案 + 规避广告法风险
方案: Gemini Ultra(主力翻译) + Claude 3(合规审查) + Llama3(非核心文案降本)
案例2:MCN机构内容总监
需求: 日更1000条爆款脚本 + 多平台适配
方案: 字节豆包(热点追踪) + 腾讯混元(优化“网感”) + Llama3(边缘账号降本)
3. 从业者选型流程图
职业场景分析 → 模型能力匹配 → 成本预算评估 → 组合方案测试 → 上线监控
2025年的竞争已从技术单点突破转向“算力+数据+合规+场景”的全维度对抗,选型需匹配自身资源禀赋与战略目标。
注:以上数据基于2025年公开信息,部分商业化案例已脱敏处理,具体选型建议需结合企业实际需求测试验证。

Copyright 2014-2026 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号


















