
1.1 定义与核心特征
大模型是指通过海量数据和巨大参数量(通常10亿以上)训练而成的深度学习模型,具有以下特征:
1.2 与小模型的对比
| 维度 | 大模型 | 传统小模型 |
|---|---|---|
| 数据需求 | 千亿级token | 百万级样本 |
| 计算资源 | 千卡GPU集群训练 | 单卡可训练 |
| 应用方式 | 预训练+微调/提示工程 | 端到端训练 |
| 泛化能力 | 跨任务零样本学习 | 特定任务专用 |
| 可解释性 | 黑箱特性显著 | 相对可解释 |
1.3 与其他AI技术的关系
与深度学习:大模型是深度学习的规模化延伸
与传统NLP:终结了特征工程时代
与知识图谱:互补关系(参数化vs符号化知识)
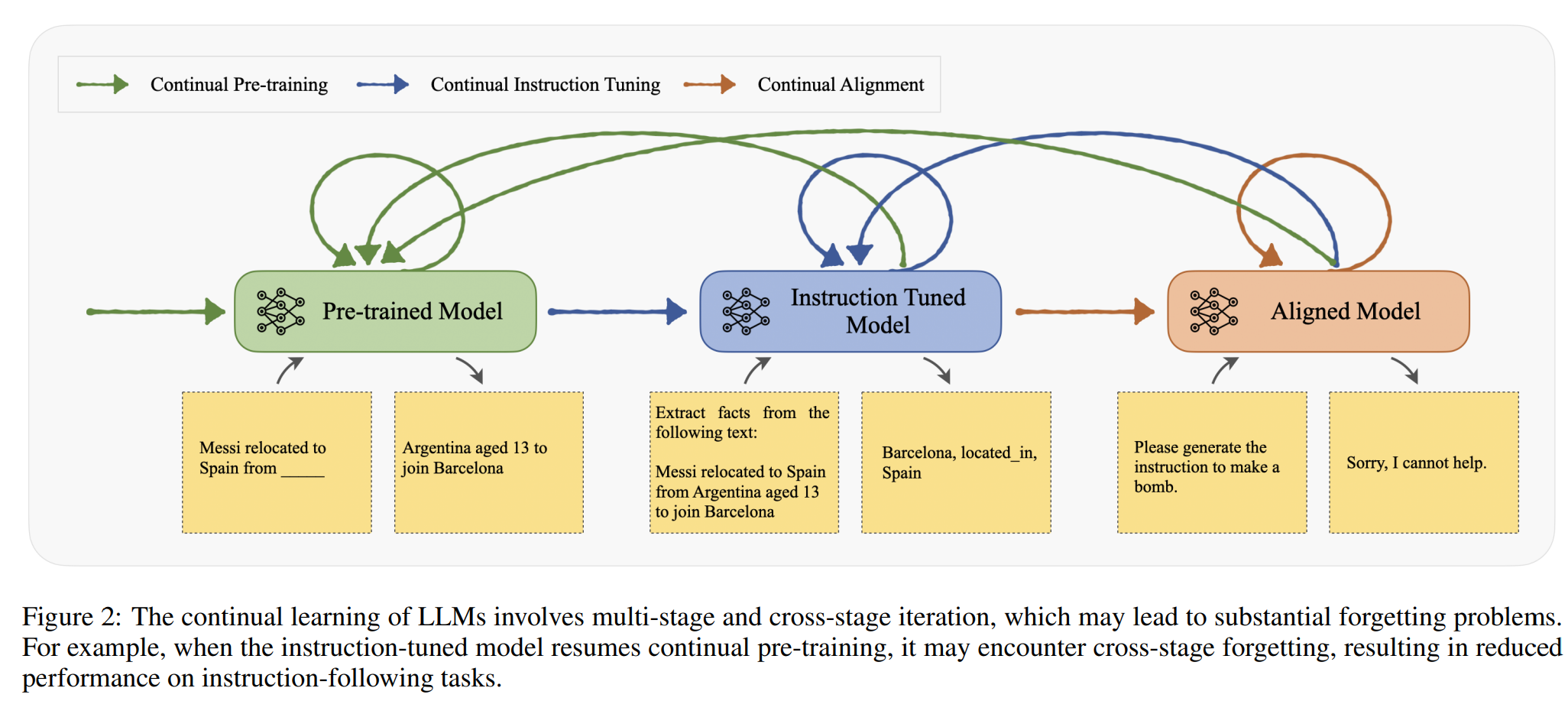
2.1 GPT系列(OpenAI)
技术路线:纯解码器Transformer
代际演进:
核心突破:上下文学习
2.2 BERT系列(Google)
技术路线:编码器Transformer
重要变体:
应用场景:文本分类、语义理解等判别任务
2.3 Transformer架构变体
| 模型类型 | 代表模型 | 核心创新 |
|---|---|---|
| 编码器-解码器 | T5 | 统一文本到文本框架 |
| 稀疏模型 | Switch Transformer | 专家混合(MoE)架构 |
| 多模态 | Flamingo | 视觉-语言交叉注意力 |
2.4 其他重要模型
国际主流模型
国产模型阵营
| 模型 | 研发机构 | 核心特点 |
|---|---|---|
| 文心大模型 | 百度 | 知识增强、产业级应用 |
| 通义千问 | 阿里云 | 多模态、电商场景优化 |
| 盘古大模型 | 华为 | 全栈自主、昇腾硬件适配 |
| DeepSeek | 深度求索 | 长上下文支持(128K)、数学推理强化 |

3.1 微调的定义与目的
微调(Fine-tuning)是在预训练模型基础上,使用领域特定数据进行参数调整的技术过程,主要实现:
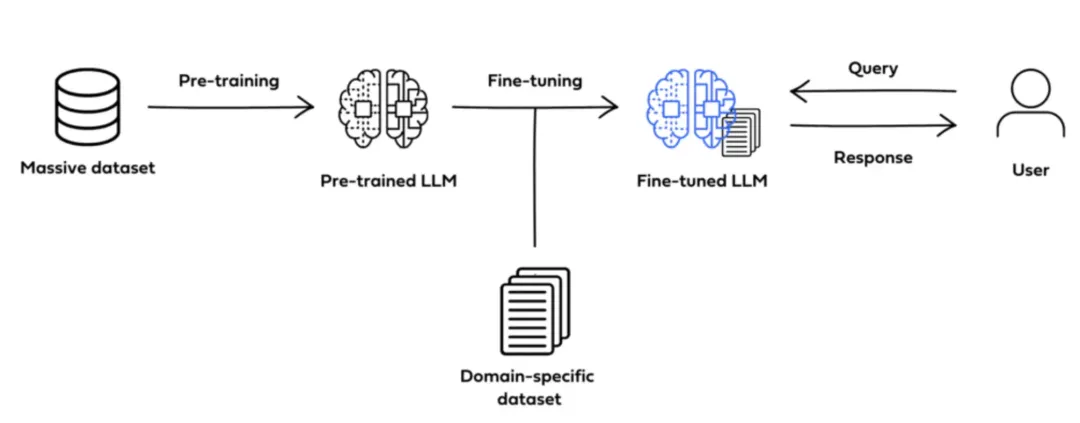
3.2 主流微调方法
3.2.1 全参数微调
3.2.2 参数高效微调(PEFT)
| 方法 | 原理 | 参数量占比 |
|---|---|---|
| LoRA | 低秩矩阵近似参数更新 | 0.1%-1% |
| Adapter | 插入小型神经网络模块 | 1%-5% |
| Prefix Tuning | 学习连续前缀向量 | 0.5%-3% |
| BitFit | 仅调整偏置项参数 | <0.1% |
3.2.3 人类反馈强化学习(RLHF)
三阶段流程:
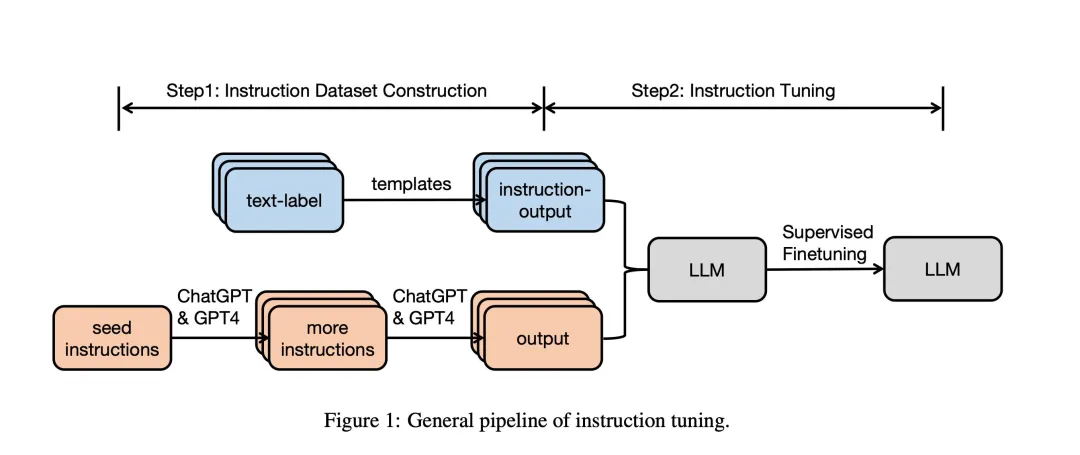
典型应用:ChatGPT对话策略优化
3.3 微调与迁移学习的关系
共同点:都涉及知识迁移
差异点:
4.1 NLP领域应用
金融文本分析:
医疗问答系统:
4.2 计算机视觉应用
工业质检:
遥感图像:
4.3 推荐系统优化
电商推荐:
视频推荐:
4.4 企业数字化转型助力
客服中心:
智能文档:
5.1 当前行业现状
技术采纳:
典型痛点:
5.2 未来技术趋势
5.3 挑战与机遇
主要挑战:
重大机遇:
大模型微调技术正在重塑AI应用开发范式,其发展呈现”轻量化、专业化、自动化”三大趋势。随着技术的不断突破,微调将成为企业获取定制化AI能力的标准路径。

Copyright 2014-2026 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号


















