
机器学习就是一个更加强大的大脑,一个更加强大的专家系统。在这个系统中存在大规模的规则来满足用户的需要。而在人工智能领域中这些规则中的主体就叫做特征,这些特征构成了人工智能最主要的组成部分。
比如还是信用卡反欺诈这个场景,交易城市是一个特征,交易金额是一个特征,交易时间还是一个特征,人工智能的流程就是用户需要筛选可能会对识别结果产生重要影响的特征,然后机器学习则会按照算法去训练出每个特征所占的权重。
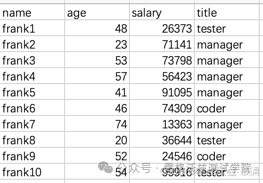
离散特征与连续特征最大的区别在于算法在计算对应字段的时候如何处理,对于离散特征来说算法会将每一个唯一的值作为一个独立的特征,比如我们有用户表, 其中职业这个字段中我们有100种职业,也就是说这张表不论有多少行,职业这个字段的取值就是这100个职业中的一个。
而对于算法来说每一个职业就是一个独立的特征。老师是一个特征,学生是一个特征,程序员、环卫工人、产品经理、项目经理等等这些都是独立的特征。也就是说对于这张表,不论有多少行,算法针对职业这一字段提取出来的特征就是固定的这100个。
而连续特征则完全不同,它是一个数字的数字,算法会把它当成一个独立的特征,也就是当算法把一个字段提取成为连续特征后,不管这张表有多少行,这个字段固定就只有1个特征被提出来。只不过这个特征值是会变动的。
但是一个字段是否是连续特征或者离散特征并不是固定的,职业这样的字段可以被算法进行连续化处理,像薪水这样的字段也可以被算法进行离散化处理。并不是一成不变的。
比如在spark ml中可以将连续特征进行二值化或者分桶来达到转换成离散特征的目的:
# 连续特征二值化from pyspark.sql import SparkSessionfrom pyspark.ml.feature import Binarizerspark = SparkSession.builder.config("spark.Driver.host", "192.168.1.4") \.config("spark.ui.showConsoleProgress", "false") \.appName("Binarize").master("local[*]").getOrCreate()data = spark.createDataFrame([(0.1,),(2.3,),(1.1,),(4.2,),(2.5,),(6.8,),], ["values"])data.show()binarizer = Binarizer(threshold=2.4, inputCol="values", outputCol="features")res = binarizer.transform(data)res.show()+------+--------+|values|features|+------+--------+| 0.1| 0.0|| 2.3| 0.0|| 1.1| 0.0|| 4.2| 1.0|| 2.5| 1.0|| 6.8| 1.0|+------+--------+
# 连续特征分桶离散化from pyspark.sql import SparkSessionfrom pyspark.ml.feature import Bucketizerspark = SparkSession\.builder\.appName("BucketizerExample")\.getOrCreate()splits = [-float("inf"), -0.5, 0.0, 0.5, float("inf")]data = [(-999.9,), (-0.5,), (-0.3,), (0.0,), (0.2,), (999.9,)]dataFrame = spark.createDataFrame(data, ["features"])# splits:区间边界,outputCol:分桶后的特征名bucketizer = Bucketizer(splits=splits, inputCol="features", outputCol="bucketedFeatures")# Transform original data into its bucket index.bucketedData = bucketizer.transform(dataFrame)print("Bucketizer output with %d buckets" % (len(bucketizer.getSplits())-1))bucketedData.show()# 运行结果|features|bucketedFeatures|+--------+----------------+| -999.9| 0.0|| -0.5| 1.0|| -0.3| 1.0|| 0.0| 2.0|| 0.2| 2.0|| 999.9| 3.0|+--------+----------------+
普通的特征都是在一行内进行提取,而在真实的场景中,仅仅是这样单行的特征是无法满足业务的需要的。在建模过程中,用户往往需要统计更加复杂的特征。
比如建模工程师会觉得用户在过去一周内的单笔最大消费额是非常有用的特征,而这样的特征明显是需要从很多行的数据中进行计算。而这样的特征一般被称作多行特征或者时序特征,因为这类特征往往都是在计算一段时间内的数据特性,所以往往被叫做时序特征。
在一些支持sql的计算框架和数据库中,窗口函数往往会被用来提取时序特征。
比如在spark中可以这样编写代码:
from pyspark import SparkContext, SparkConf, SQLContextfrom pyspark.sql import functions as Ffrom pyspark.sql.functions import udffrom pyspark.sql.window import Windowconf = SparkConf().setMaster("local").setAppName("My App")sc = SparkContext(conf=conf)sqlContext = SQLContext(sc)dicts = [['frank','男', 16, '程序员', 3600], ['alex','女', 26, '项目经理', 3000], ['frank','男', 16, '程序员', 2600]]rdd = sc.parallelize(dicts, 3)dataf = sqlContext.createDataFrame(rdd, ['name','gender', 'age', 'title', 'price'])windowSpec = Window.partitionBy(dataf.gender)windowSpec = windowSpec.orderBy(dataf.age)windowSpec = windowSpec.rowsBetween(Window.unboundedPreceding, Window.currentRow)dataf.withColumn('max_price', F.max(dataf.price).over(windowSpec)).show()# 运行结果+-----+------+---+--------+-----+---------+| name|gender|age| title|price|max_price|+-----+------+---+--------+-----+---------+|frank| 男| 16| 程序员| 3600| 3600||frank| 男| 16| 程序员| 2600| 3600|| alex| 女| 26|项目经理| 3000| 3000|+-----+------+---+--------+-----+---------+

Copyright 2014-2026 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号


















