
测试开发中的数据处理与模型挑战
在测试自动化、性能监控、异常检测等场景中,深度学习模型的应用日益广泛。但面临两大核心问题:
数据蒸馏与知识蒸馏技术为上述问题提供了系统性解决方案。本文从技术原理到测试实践,解析这两项关键技术的实现路径。
核心目标:从原始数据集中提取高价值子集,提升测试数据质量
四步实现:
数据清洗:剔除重复、错误样本(如自动化测试中的无效截图)
特征提取:通过卷积层/嵌入层捕获关键特征(如UI元素的布局模式)
降维处理:使用PCA/t-SNE减少冗余维度(压缩日志分析数据量)
子集生成:保留覆盖主要场景的样本(如接口测试的典型请求参数组合)
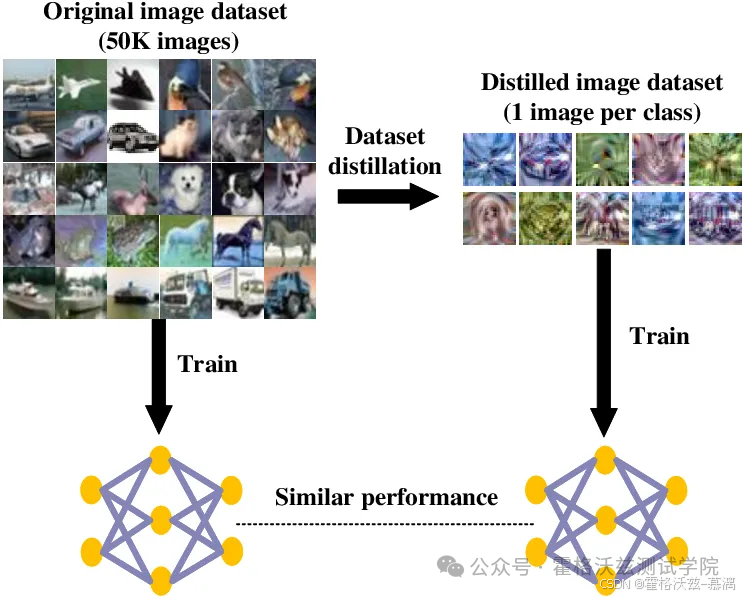
自动化测试数据集优化:
原始数据:10万张UI截图(含30%模糊/重复图像)
蒸馏后:2万张高代表性截图,测试用例执行效率提升3倍
性能测试数据生成:
通过聚类算法提取典型用户行为模式,压测脚本覆盖率提升50%
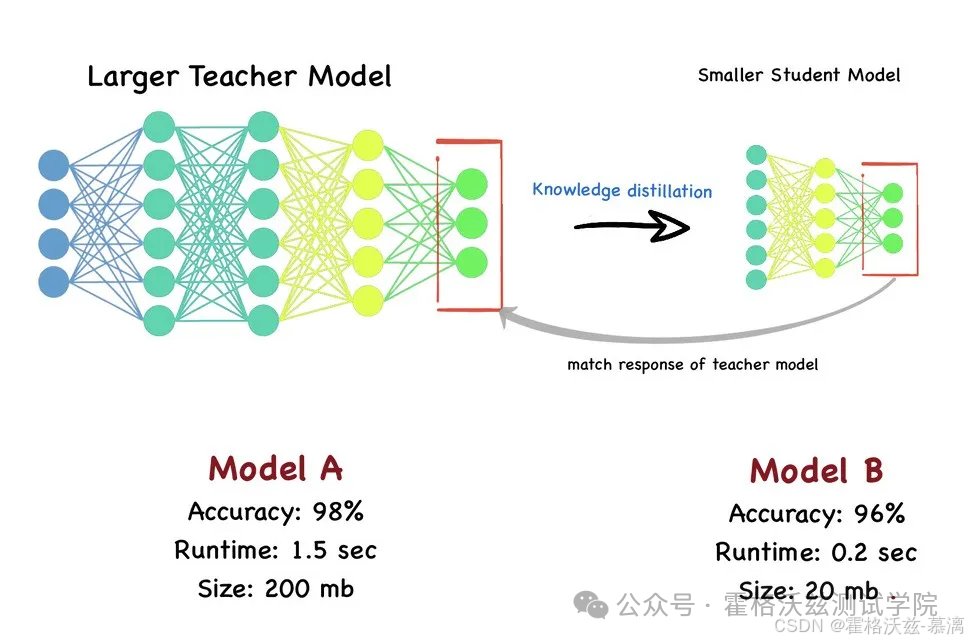
核心逻辑: 将大模型(教师)的知识迁移至小模型(学生)
关键步骤:
教师模型训练:使用完整数据集训练高精度模型(如ResNet-50)
软标签生成:输出概率分布而非硬标签(传递“猫与豹的相似性”信息)
学生模型训练:结合软标签与真实标签优化(交叉熵+KL散度联合损失)
(示例对比)
| 模型类型 | 准确率 | 推理速度 | 内存占用 |
|---|---|---|---|
| 教师模型 | 98% | 1.5秒 | 200MB |
| 学生模型 | 96% | 0.2秒 | 20MB |
移动端测试工具部署:
问题:目标检测模型过大导致自动化测试App卡顿
方案:将YOLOv5蒸馏为MobileNet架构
效果:模型体积缩小90%,帧率从5FPS提升至30FPS
持续集成环境优化:
问题:Jenkins流水线模型推理资源不足
方案:使用蒸馏后模型,单任务GPU显存占用从4GB降至1GB
| 场景 | 推荐技术 | 工具链 |
|---|---|---|
| 测试数据质量低下 | 数据蒸馏 | Scikit-learn/PyTorch |
| 端侧测试资源受限 | 知识蒸馏 | TensorFlow Lite/HuggingFace |
| 多任务并发测试 | 混合方案 | NNI(自动化调参工具) |
需求分析:统计测试数据集冗余率与模型推理延迟
技术验证:
数据蒸馏:评估子集覆盖度(如关键路径覆盖率)
知识蒸馏:监控精度损失与资源消耗曲线
渐进落地:
优先在非核心链路(如测试报告生成)试点
逐步扩展至性能测试/异常检测等关键场景
数据蒸馏过度:子集丢失关键边界场景(如支付失败异常)
知识迁移失效:学生模型过度简化(如MobileNet处理复杂OCR)
| 技术 | 核心指标 | 合格标准 |
|---|---|---|
| 数据蒸馏 | 测试用例覆盖率 | ≥原始数据集95% |
| 知识蒸馏 | 精度损失/资源消耗比 | 损失≤3%且资源降幅≥70% |
总结:构建高效测试工具链的技术路径数据层
(附:开源工具推荐)
数据蒸馏:DISTIL(Facebook开源数据集优化库)
知识蒸馏:PyTorch Lightning-Bolts(预训练蒸馏模板)

Copyright 2014-2026 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号


















