

RAG,全称Retrieval Augmented Generation,翻译过来就是检索增强生成,随着大模型技术的应用,我们听到这个词的频率越来越高,可以说是当下最火的一种应用方案。
简单来说,就是增强大模型的知识领域,从而生成更准确和信息丰富的文本。
相信大家或多或少的都接触过GPT或者类似的诸如文心一言、通义千问等等LLM(大语言模型,下文将以此简称)的使用,能力强大,但是依然有明显的无法满足部分实际业务的场景:
因此为了解决上述问题,我们就需要引入RAG技术
从RAG的名称(检索增强生成)也可以很清晰的知道,其核心组成就是检索+生成;可以检索到我们想知道的相关信息,然后依靠LLM生成我们想知道的答案。而想要更快速准确的检索到相关信息,我们就还需要索引。
索引的主要工作,就是将我们的本地私有知识库进行向量化存储,利用向量数据库的高效存储和检索能力,召回目标知识,供LLM分析使用。
索引的过程一般大体上有如下几步:
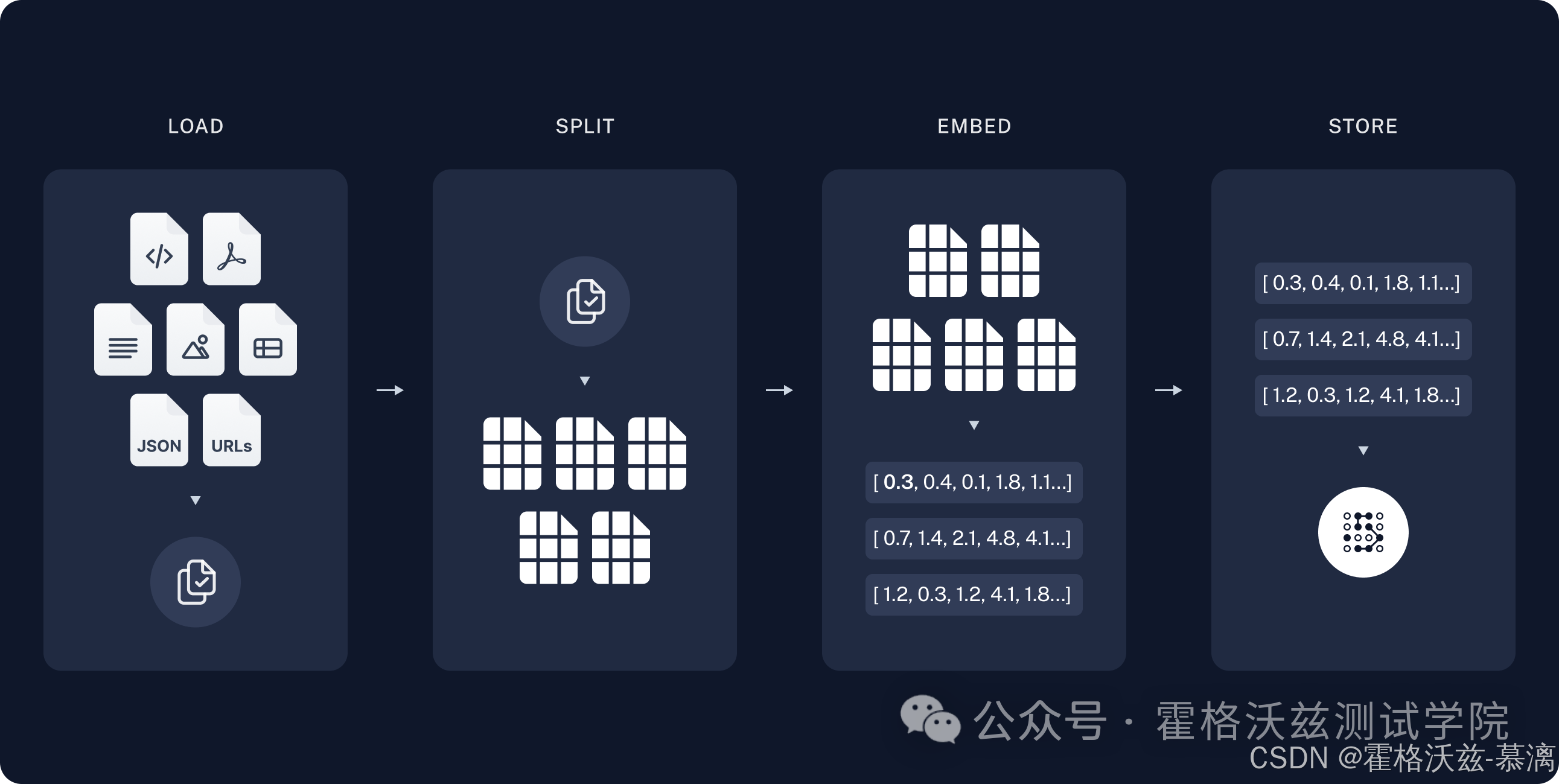
1、本地数据加载:数据可能有多种形式,Json、txt、Markdown、PDF等
2、数据切片:本地的数据可能一份很大,对于检索的准确度和LLM对token的限制都有影响,所以我们需要将数据分割成若干个小块;
过程中切片的大小,重叠的多少,以及以何种方式断句分割都对后续的检索效果有一定的影响。因为文本只有语义关联的,一个句子如果还没有说完,中间直接截断,那么就会造成上下文语义不清晰的情况。
3、向量存储:这一步,利用使用VectorStore和Embeddings模型来完成将切片数据进行存储和索引,以供后续的检索使用
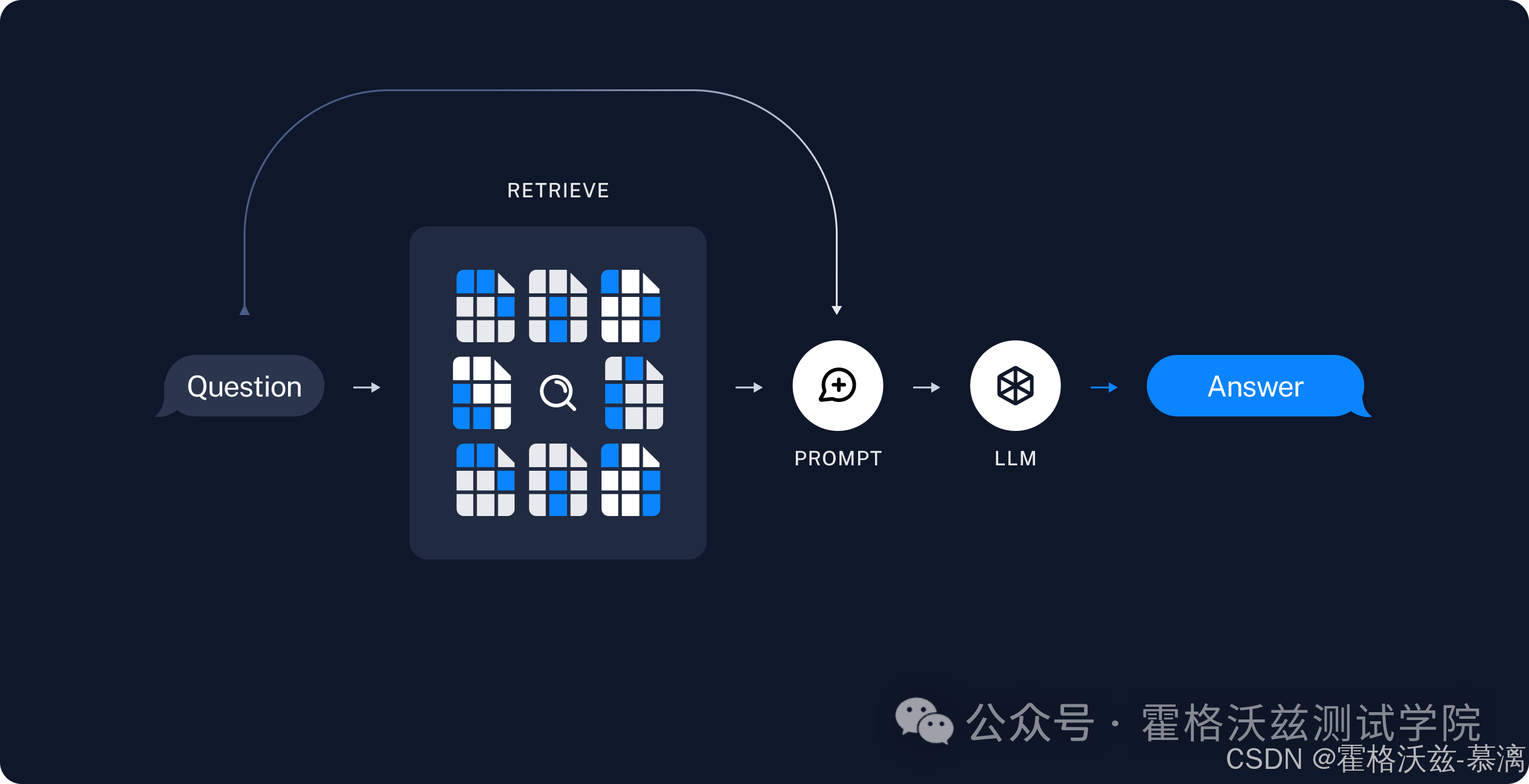
1、检索:通过检索器对切片分割的数据进行检索,其中可能涉及多种检索方式的融合,例如相似性,可按照相似度排分进行召回top-k个结果
2、生成:LLM使用包含问题和检索到的数据的Prompt生成答案
应用:
1、问答系统
现代问答系统需要处理各种各样的问题,从简单的事实查询到复杂的推理问题。传统生成模型在处理这些问题时,可能会因为缺乏足够的上下文信息而产生不准确的回答。RAG通过检索相关文档,为生成模型提供了丰富的背景知识,从而生成更准确和详细的回答。
示例:
2、内容生成
在内容生成应用中,如新闻写作、报告生成和产品描述,RAG可以通过检索相关资料,生成内容丰富且信息准确的文本。这不仅提高了生成内容的质量,还节省了大量的人工编辑时间。
示例:
3、客户支持
RAG可以帮助客服机器人提供更专业和详细的回答,提高客户服务质量。通过检索相关的支持文档和解决方案,RAG能够快速且准确地回答客户的问题。
示例:
思考:
1、使用形式
如上所述,目前主流的RAG大多都是以chatbot的形式,chatbot的形式固然是发挥了交互上以自然语言聊天沟通的优势,不过也缺少了在特定技术领域的操作便捷性。
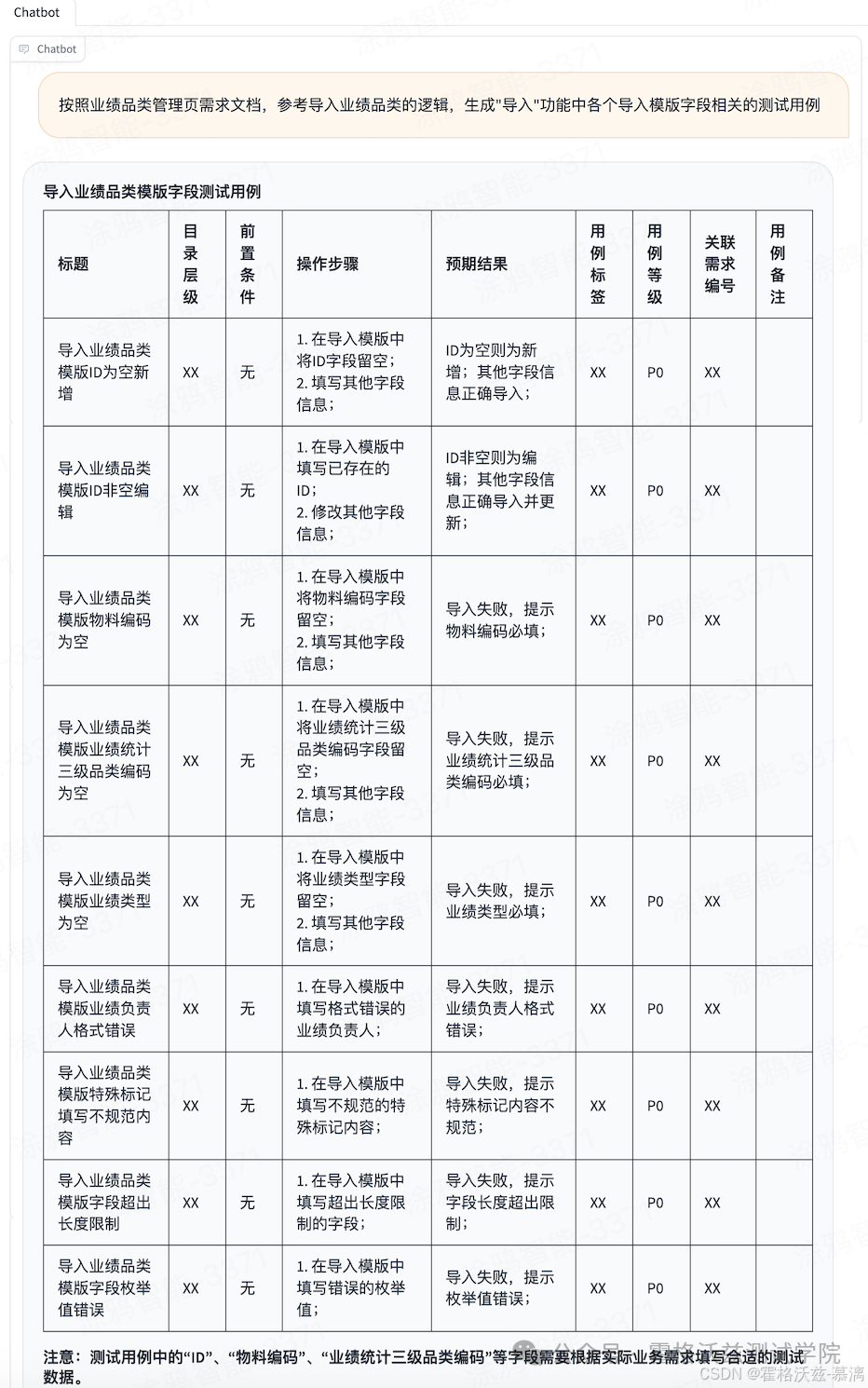
以测试用例编写为例,在公司内部,测试用例的实际编写时,有相当一部分都是基于XMind编写后再上传至平台保存的。
如果有使用过Copilot的一定有所感触,直接在IDE上进行chat,获取你想知道的相关技术问题,chat的过程还可以联想到项目中的代码中。而代码的编写时可以自动联想补全,这种形式很方便很符合开发检索的需求

受此启发,那么我们就想,如果我能把IDE换成XMind,一边用XMind写用例,一边在写的过程中可以根据当前用例需要的需求背景和功能模块描述帮我自动补全修改甚至检查XMind上的用例,完成后保存即可上传至平台存档,岂不美哉?
于是乎,这将会是下个阶段的探索目标,希望能拥有我们测试人自己的“Copilot”。
2、能力拓展
在做AI领域的调研探索时,相信很多人和我一样经常会有这样的想法,我能不能就直接告诉他帮我干一件什么事,然后AI直接帮我给做了。
还是拿测试领域为例,测试除了测试用例,还有个最频繁打交道的就是数据,例如我有了一堆数据,我需要以某种规则或格式整理出来,然后填入到某个平台中供使用;
或者根据测试数据生成了一些自动化用例,自动去触发执行。
我们单从RAG的角度来看,是无法完成的,RAG仅仅是加强版的搜索;我们可以简单以一个人为例子,RAG可能就属于一个人的大脑,大脑有很强的思考逻辑能力,但是大脑本身不具备行动能力,想要画画,得控制手去握住画笔进行创作。

那么下个阶段,我们就需要拓展AI的行动能力,给大脑赋予身体(agent)和工具(tools),让AI能做到人与人之间的对话指挥一样,你来说,我来做。

Copyright 2014-2026 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号


















