
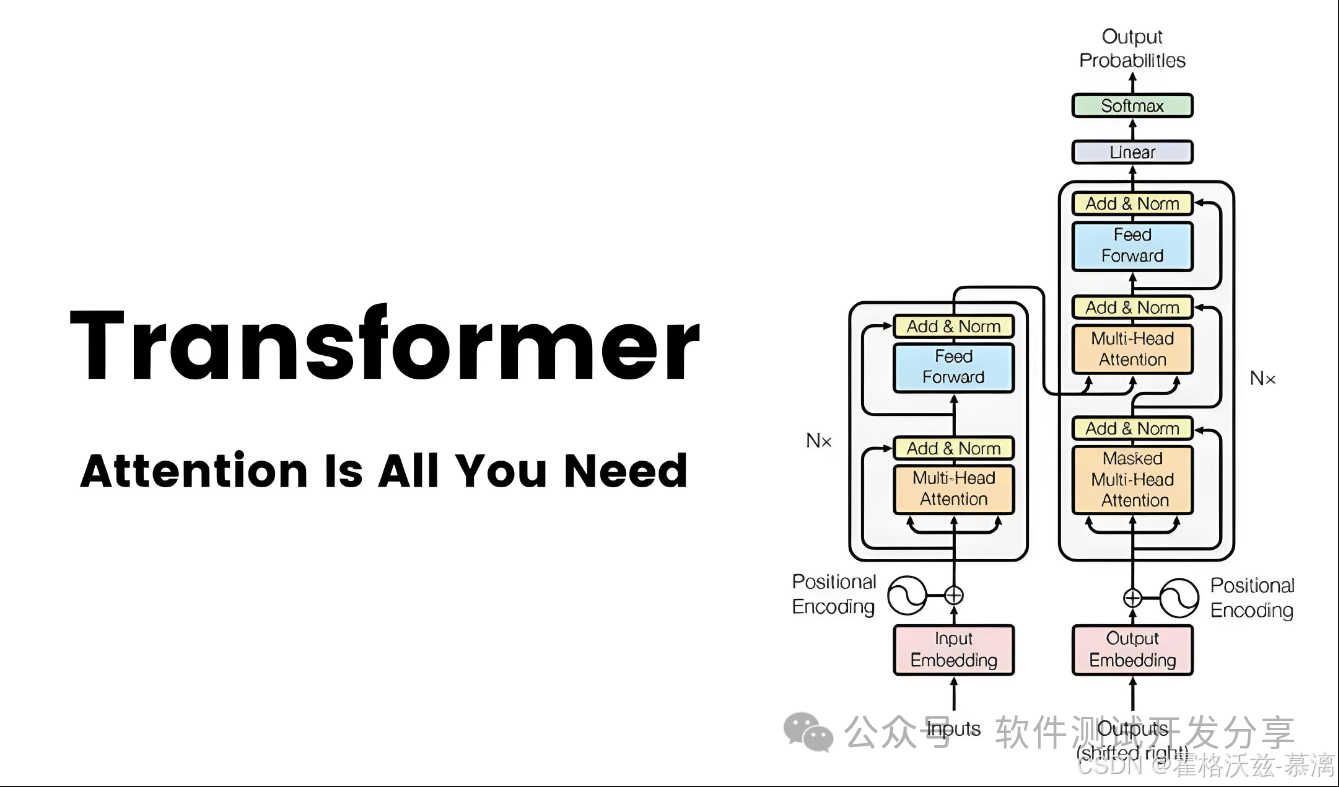
Transformer是近年来自然语言处理(NLP)领域最重要的突破之一,由Google在2017年发表的论文《Attention is All You Need》中提出。它彻底改变了序列建模的方式,取代了传统的RNN和LSTM模型。下面我们将全面解析Transformer的核心概念和工作原理。
Transformer是一种基于自注意力机制(Self-Attention)的序列到序列(Seq2Seq)模型,具有以下特点:
自注意力机制是Transformer的核心,它允许模型在处理每个词时关注输入序列中的所有词,并动态计算它们的重要性。
计算过程:
分数 = Q·K^T / √d_k (d_k是Key的维度)为了捕捉不同子空间的信息,Transformer使用多头注意力:
由于Transformer没有循环结构,需要显式地注入位置信息:
PE(pos,2i) = sin(pos/10000^(2i/d_model))PE(pos,2i+1) = cos(pos/10000^(2i/d_model))
其中pos是位置,i是维度。
每层的FFN通常由两个线性变换和ReLU激活组成:
FFN(x) = max(0, xW1 + b1)W2 + b2
自原始Transformer提出后,出现了许多改进版本:
在实际实现Transformer时需要注意:
Transformer已广泛应用于:
Transformer通过自注意力机制彻底改变了序列建模的方式,成为现代NLP的基石。理解其核心思想和实现细节对于掌握当前最先进的深度学习模型至关重要。随着研究的深入,Transformer及其变体在各种领域的应用仍在不断扩展。

Copyright 2014-2026 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号


















