
spark streaming和structured streaming是apache spark生态系统中用于流处理的两种不同框架。让我们详细比较它们的特点和优势。
Spark Streaming的特点:
Spark Streaming是Spark最初推出的流处理框架,采用微批处理的方式进行流数据处理。它使用基于RDD的DStream API,每个时间间隔内的数据被视为一个RDD,通过不断处理这些RDD来实现流计算。
然而,Spark Streaming也存在一些不足:
处理时间而非事件时间:Spark Streaming基于处理时间(Processing Time)进行数据切割,而非事件时间(Event Time)。处理时间是数据到达Spark被处理的时间,而事件时间是数据本身产生的时刻。这种基于处理时间的切割使得使用事件时间进行数据处理变得非常困难。
复杂且低级的API:DStream API类似于RDD API,属于低级API。开发者需要构造RDD的DAG执行图,这可能导致执行效率因开发者水平不同而有显著差异,影响开发体验。
难以保证端到端的一致性:DStream只能保证自身的exactly-once一致性语义,而输入和输出的一致性需要开发者自己保证,这对开发者来说是一个挑战。
批流代码不统一:尽管批处理和流处理是两套系统,但统一它们是有必要的。将DStream代码转换为RDD需要额外的工作量,而现在Spark的批处理已经使用DataSet/DataFrame API。
Structured Streaming的优势:
Structured Streaming是Spark 2.0版本推出的新的实时流处理框架(2.0和2.1为实验版本,从Spark 2.2开始为稳定版本)。自Spark 2.X版本后,Spark Streaming进入维护模式,而Structured Streaming成为Spark流处理的主要方向。
Structured Streaming的优势包括:
简洁的模型:Structured Streaming将流数据视为一个不断增长的表,模型简洁易懂。
一致的API:与Spark SQL共用大部分API,使得熟悉Spark SQL的用户容易上手。批处理和流处理可以共用代码,提高开发效率。
卓越的性能:Structured Streaming使用Spark SQL的Catalyst优化器和Tungsten引擎,性能出色,并能从Spark SQL的未来性能优化中受益。
多语言支持:支持Spark SQL支持的所有语言,包括Scala、Java、Python、R和SQL,用户可以选择自己喜欢的语言进行开发。
基于事件时间:与Spark Streaming基于处理时间不同,Structured Streaming支持基于事件时间的处理,更符合业务场景。
支持Spark 2的DataFrame处理:解决了Spark Streaming在代码升级、DAG图变化导致的任务失败和无法断点续传的问题。
基于Spark SQL的可扩展和容错流处理引擎:使得实时流处理和离线计算可以使用相同的处理方式(DataFrame&SQL)。
底层原理差异:
Spark Streaming:采用微批处理方法,每个批处理间隔为一个批次,即一个RDD,通过操作RDD实现持续数据处理。
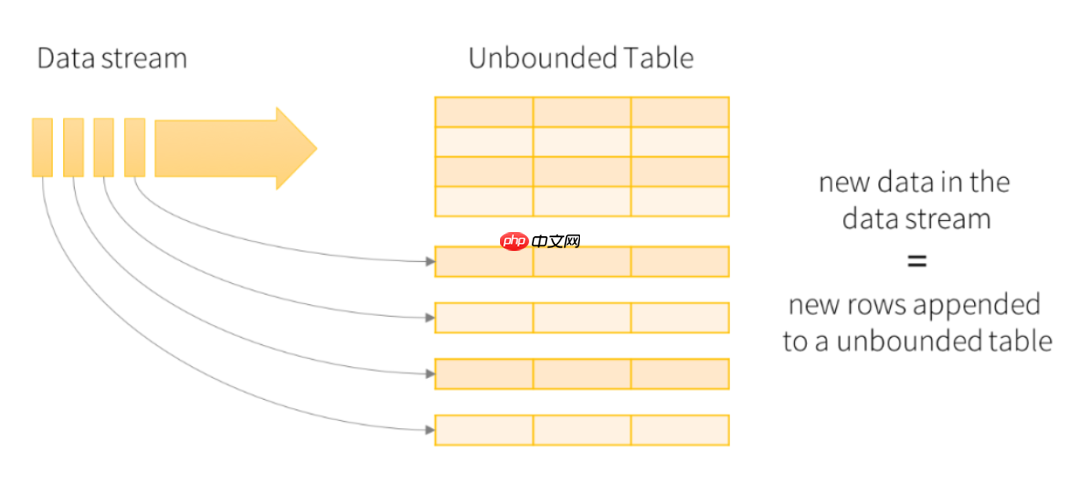
Structured Streaming:将实时数据视为被连续追加的表,每条数据类似于向表中添加一行新数据。

自Spark 3.0.0发布后,Structured Streaming迎来了全新的UI界面,预示着Structured Streaming将在未来不断进步。
通过上述比较可以看出,Structured Streaming在简洁性、一致性、性能和多语言支持等方面都优于Spark Streaming,是Spark流处理的未来方向。
以上就是用Spark进行实时流计算的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 494
494























