
不知不觉,这已经是快速入门flink系列的第7篇博客了。早在第4篇博客中,博主就已经为大家介绍了在批处理中,数据输入data sources 与数据输出data sinks的各种分类(传送门:flink批处理的datasources和datasinks)。但是大家是否还记得flink的概念?flink是 分布式、 高性能、 随时可用以及准确的为流处理应用程序打造的开源流处理框架。所以光介绍了批处理哪里行呢!本篇博客,我们就来学习flink流处理的datasources和datasinks~

1) 获取 Flink 流处理执行环境
2) 构建 source
3) 数据处理
4) 构建 sink
1.1.2 示例编写 Flink 程序,用来统计单词的数量。
1.1.3 步骤1) 获取 Flink 批处理运行环境
2) 构建一个 socket 源
3) 使用 flink 操作进行单词统计
4) 打印
说明:如果 linux 上没有安装 nc 服务 ,使用 yum 安装
代码语言:javascript代码运行次数:0运行复制yum install -y nc
import org.apache.flink.api.java.tuple.Tupleimport org.apache.flink.streaming.api.scala._import org.apache.flink.streaming.api.windowing.time.Timeimport org.apache.flink.streaming.api.windowing.windows.TimeWindow/* * @Author: Alice菌 * @Date: 2020/7/9 08:40 * @Description: */// 入门案例,单词统计object StreamWordCount { def main(args: Array[String]): Unit = { // 1、 创建流处理的执行环境 val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment // 2、 构建数据源,使用的socket val socketDataStream: DataStream[String] = env.socketTextStream("node01",9999, 0) // 3、 数据的处理 val wordDataStream: DataStream[(String, Int)] = socketDataStream.flatMap(_.split(" ")).map(_ -> 1) //4. 使用keyBy 进行分流(分组) // 在批处理中针对于dataset, 如果分组需要使用groupby // 在流处理中针对于datastream, 如果分组(分流)使用keyBy val groupedDataStream: KeyedStream[(String, Int), Tuple] = wordDataStream.keyBy(0) //5. 使用timeWinodw 指定窗口的长度(每5秒计算一次) // spark-》reduceBykeyAndWindow val windowDataStream: WindowedStream[(String,Int),Tuple,TimeWindow]= groupedDataStream.timeWindow( Time.seconds(5) ) //6. 使用sum执行累加 val sumDataStream: DataStream[(String, Int)] = windowDataStream.sum(1) sumDataStream.print() env.execute("StreamWordCount") }}我们来测试下效果如何~
首先我们在linux上开启9999端口
nc -lk 9999

然后我们启动我们的程序,发现也是毫无波澜。
接下来就是见证奇迹的时候了,当我以飞快的速度在命令行中敲下这些字母

然后观察程序的控制台,发现打印出了每5秒内,所有的字符数的个数

有朋友肯定会好奇,为什么scala一次显示为3次,后面只显示了1次?。哈哈,注意观察我上方留下的代码,我只设置了窗口的大小,滑动距离可还没有设置呢~所以,每次都是对单独一个5秒时间内所有字母求WordCount。
OK,看到了上方的效果图,我们可以继续深入学习。
1.2 输入数据集 Data Sources 在Flink中我们可以使用 StreamExecutionEnvironment.addSource(source) 来为程序添加数据来源。
Flink 已 经 提 供 了 若 干 实 现 好 了 的 source functions ,当 然 你 也 可 以 通 过 实 现 SourceFunction 来自定义非并行的 source 或者实现 ParallelSourceFunction 接口或者扩展 RichParallelSourceFunction 来自定义并行的 source。
1.2.1 Flink 在流处理上常见的 SourceFlink 在流处理上的 source 和在批处理上的 source 基本一致。
大致有 4 大类
基于本地集合的 source基于文件的 source基于网络套接字的 source自定义的 source1.2.2 基于集合的 source示例代码代码语言:javascript代码运行次数:0运行复制import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}import scala.collection.immutable.{Queue, Stack}import scala.collection.mutableimport scala.collection.mutable.{ArrayBuffer, ListBuffer}import org.apache.flink.api.scala._/* * @Author: Alice菌 * @Date: 2020/8/8 17:02 * @Description: */object StreamDataSourceDemo { def main(args: Array[String]): Unit = { val senv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment // 0. 用element创建DataStream val ds0: DataStream[String] = senv.fromElements("spark","flink") ds0.print() // 1. 用Tuple创建DataStream val ds1: DataStream[(Int, String)] = senv.fromElements((1,"spark"),(2,"flink")) ds1.print() // 2. 用Array创建DataStream val ds2: DataStream[String] = senv.fromCollection(Array("spark","flink")) ds2.print() // 3. 用ArrayBuffer 创建DataStream val ds3: DataStream[String] = senv.fromCollection(ArrayBuffer("spark","flink")) ds3.print() // 4. 用List创建DataStream val ds4: DataStream[String] = senv.fromCollection(List("spark","flink")) ds4.print() // 5. 用List创建DataStreamm val ds5: DataStream[String] = senv.fromCollection(ListBuffer("spark","flink")) ds5.print() // 6. 用Vector创建DataStream val ds6: DataStream[String] = senv.fromCollection(Vector("spark","flink")) ds6.print() // 7. 用Queue创建DataStream val ds7: DataStream[String] = senv.fromCollection(Queue("spark","flink")) ds7.print() // 8. 用Stack创建DataStream val ds8: DataStream[String] = senv.fromCollection(Stack("spark", "flink")) // 9. 用Stream创建DataStream(Stream相当于lazy List,避免在中间过程中生 成不必要的集合) val ds9: DataStream[String] = senv.fromCollection(Stream("spark","flink")) ds9.print() // 10. 用Seq创建DataStream val ds10: DataStream[String] = senv.fromCollection(Seq("spark","flink")) ds10.print() // 11. 用Set创建DataStream(不支持) // val ds11: DataStream[String] = senv.fromCollection(Seq("spark", "flink")) // ds11.print() // 12.用Iterable创建DataStream(不支持) // val ds12: DataStream[String] = senv.fromCollection(Iterable("spark", "flink")) // ds12.print() // 13.用ArraySeq创建DataStream val ds13: DataStream[String] = senv.fromCollection(mutable.ArraySeq("spark","flink")) ds13.print() // 14.用 ArrayStack 创建DataStream val ds14: DataStream[String] = senv.fromCollection(mutable.ArrayStack("spark","flink")) ds14.print() // 15.用Map 创建 DataStream(不支持) //val ds15: DataStream[(Int, String)] = senv.fromCollection(Map(1 -> "spark", 2 -> "flink")) //ds15.print() // 16.用Range创建DataStream val ds16: DataStream[Int] = senv.fromCollection(Range(1,9)) ds16.print() // 17.用fromElements创建DataStream val ds17: DataStream[Long] = senv.generateSequence(1,9) ds17.print() senv.execute("StreamDataSourceDemo") }}1、DataStream流式应用需要显示指定execute()方法运行程序,如果不调用则Flink流式程序不会执行。
2、无法通过Set,Iterable,Map 来创建 DataStream
1.2.3 基于文件的 source示例代码代码语言:javascript代码运行次数:0运行复制import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}/* * @Author: Alice菌 * @Date: 2020/8/8 17:42 * @Description: 基于文件的source */object StreamFileSourceDemo { def main(args: Array[String]): Unit = { // 1、构建流处理的环境 val senv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment // 2、基于文件的source,构建数据集 val textDStream: DataStream[String] = senv.readTextFile("data/input/wordcount.txt") // 3、打印输出 textDStream.print() // 4、执行程序 senv.execute("StreamFileSourceDemo") //3> Final Memory Finished at //10> Total time BUILD SUCCESS //4> Flink Flink Flink Flink Flink //9> Final Memory Finished at //1> Total time BUILD SUCCESS //8> Total time BUILD SUCCESS //12> Final Memory Finished at //6> Hive Hive Hive Hive Hive }}这里的代码跟入门案例的代码是一样哒~已经浏览过入门案例代码的朋友可以跳过啦。
其中构建数据源,使用socket : val source = env.socketTextStream("IP", PORT)
import org.apache.flink.api.java.tuple.Tupleimport org.apache.flink.streaming.api.scala._import org.apache.flink.streaming.api.windowing.time.Timeimport org.apache.flink.streaming.api.windowing.windows.TimeWindow/* * @Author: Alice菌 * @Date: 2020/7/9 08:40 * @Description: 基于网络套接字的 source */// 入门案例,单词统计object StreamWordCount { def main(args: Array[String]): Unit = { // 1、 创建流处理的执行环境 val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment // 2、 构建数据源,使用的socket val socketDataStream: DataStream[String] = env.socketTextStream("node01",9999, 0) // 3、 数据的处理 val wordDataStream: DataStream[(String, Int)] = socketDataStream.flatMap(_.split(" ")).map(_ -> 1) //4. 使用keyBy 进行分流(分组) // 在批处理中针对于dataset, 如果分组需要使用groupby // 在流处理中针对于datastream, 如果分组(分流)使用keyBy val groupedDataStream: KeyedStream[(String, Int), Tuple] = wordDataStream.keyBy(0) //5. 使用timeWinodw 指定窗口的长度(每5秒计算一次) // spark-》reduceBykeyAndWindow val windowDataStream: WindowedStream[(String,Int),Tuple,TimeWindow]= groupedDataStream.timeWindow( Time.seconds(5) ) //6. 使用sum执行累加 val sumDataStream: DataStream[(String, Int)] = windowDataStream.sum(1) sumDataStream.print() env.execute("StreamWordCount") }} 除了预定义的 Source 外,我们还可以通过实现 SourceFunction 来自定义 Source,然后通过 StreamExecutionEnvironment.addSource(sourceFunction)添加进来。
比如读取 Kafka 数据的 Source:addSource(new FlinkKafkaConsumer08);。我们可以实现以下三个接口来自定义 Source:
import org.apache.flink.streaming.api.functions.source.SourceFunctionimport org.apache.flink.streaming.api.scala.StreamExecutionEnvironmentimport org.apache.flink.streaming.api.scala._/* * @Author: Alice菌 * @Date: 2020/8/8 21:51 * @Description: 自定义非并行数据源 */object StreamCustomerNoParallelSourceDemo { def main(args: Array[String]): Unit = { // 1、创建流处理的执行环境 val senv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment // 2、基于自定义数据源构建数据 val longDStream: DataStream[Long] = senv.addSource(new MyNoParallelSource()).setParallelism(1) // 3、输出打印 longDStream.print() // 4、执行程序 senv.execute("StreamCustomerNoParallelSourceDemo") //10> 1 //11> 2 //12> 3 //1> 4 //2> 5 //3> 6 //4> 7 //5> 8 //6> 9 } /* 创建一个并行度为1的数据源 * 实现从1开始产生递增数字 */ class MyNoParallelSource extends SourceFunction[Long]{ // 申明一个变量number var number:Long = 1L var isRunning:Boolean = true override def run(ctx: SourceFunction.SourceContext[Long]): Unit = { while (isRunning){ ctx.collect(number) number += 1 // 休眠1秒 Thread.sleep(1000) if (number == 10){ cancel() } } } override def cancel(): Unit = { isRunning = false } }}import org.apache.flink.streaming.api.functions.source.{ParallelSourceFunction, SourceFunction}import org.apache.flink.streaming.api.scala.StreamExecutionEnvironmentimport org.apache.flink.streaming.api.scala._/* * @Author: Alice菌 * @Date: 2020/8/8 22:05 * @Description: 自定义创建并行数据源 */object StreamCustomerParallelSourceDemo { def main(args: Array[String]): Unit = { // 1、创建流处理的执行环境 val senv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment // 2、基于自定义ParallelSource数据源创建并行的数据 val parallelSource: DataStream[Long] = senv.addSource(new MyParallelSource()).setParallelism(5) // 3、打印输出 parallelSource.print() // 4、执行程序 senv.execute("StreamCustomerParallelSourceDemo") } /* 创建一个并行度为1的数据源 * 实现从1开始产生递增数字 */ class MyParallelSource extends ParallelSourceFunction[Long] { // 声明一个Long类型的变量 var number:Long = 1L // 申明一个初始化为true的Boolean变量 var isRunning: Boolean = true override def run(ctx: SourceFunction.SourceContext[Long]): Unit = { while (isRunning) { ctx.collect(number) number += 1 if (number > 20) { cancel() } } } override def cancel(): Unit = { isRunning = false } }}import org.apache.flink.streaming.api.functions.source.{RichParallelSourceFunction,SourceFunction}import org.apache.flink.streaming.api.scala.{DataStream,StreamExecutionEnvironment}import org.apache.flink.api.scala._import org.apache.flink.configuration.Configuration/* * @Author: Alice菌 * @Date: 2020/8/8 22:23 * @Description: 创建并行数据源 */object StreamCustomerRichParallelSourceDemo { def main(args: Array[String]): Unit = { // 1、 创建流处理运行环境 val senv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment // 2、 基于 RichParallelSource 并行数据源构建数据集 val richParallelSource: DataStream[Long] = senv.addSource(new MyRichParallelSource()).setParallelism(2) // 3、 打印输出 richParallelSource.map(line => { println("接收到的数据:" + line) line }) // 4、执行程序 senv.execute("StreamCustomerRichParallelSourceDemo") } /* 创建一个并行度为1 的数据源 实现从 1 开始产生递增数字 */ class MyRichParallelSource extends RichParallelSourceFunction[Long] { var count: Long = 1L var isRunning: Boolean = true override def run(ctx: SourceFunction.SourceContext[Long]): Unit = { while (isRunning){ ctx.collect(count) count += 1 Thread.sleep(1000) } } override def cancel(): Unit = { isRunning = false } override def open(parameters: Configuration): Unit = { super.close() } }}import java.util.Propertiesimport org.apache.flink.api.common.serialization.SimpleStringSchemaimport org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}import org.apache.flink.api.scala._import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011/* * @Author: Alice菌 * @Date: 2020/8/8 22:51 * @Description: 基于 kafka 的 source 操作 */object StreamKafkaSourceDemo { def main(args: Array[String]): Unit = { // 1、构建流处理执行环境 val senv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment // 指定消费者主题 val topic: String = "test" // 设置参数 val props: Properties = new Properties props.setProperty("bootstrap.servers", "node01:9092") props.setProperty("group.id", "test") props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer") props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer") // 基于 Flink,创建 Kafka消费者 val kafkaConsumer: FlinkKafkaConsumer011[String] = new FlinkKafkaConsumer011[String](topic,new SimpleStringSchema(),props) // Flink 从 topic 中最新的数据开始消费 kafkaConsumer.setStartFromLatest() // 构建基于 kafka 的数据源 val kafkaDataStream: DataStream[String] = senv.addSource(kafkaConsumer) // 打印输出消费的数据 kafkaDataStream.print() // 执行流处理的程序 senv.execute("StreamKafkaSourceDemo") }}我们启动kafka,模拟生产者来生产数据。
node01 服务器执行以下命令来模拟生产者进行生产数据。
代码语言:javascript代码运行次数:0运行复制cd /export/servers/kafka_2.11-1.0.0bin/kafka-console-producer.sh --broker-list node01:9092,node02:9092,node03:9092 --topic test
然后我们启动所写的程序
同时,在kafka中生产一些数据

观察程序的控制台
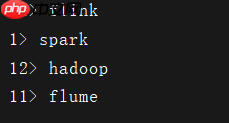
看到这样的效果就说明我们的代码是OK了~
1.2.7 基于 mysql 的 source 操作上面就是 Flink 自带的 Kafka source,那么接下来就模仿着写一个从 MySQL 中读取数据 的 Source。
首先我们先确定需要查询指定数据库下的某张表。
这里我们以 blogs 数据库下的 notice表为例。

下面,我们通过Flink来获取到该数据表的内容。
示例代码代码语言:javascript代码运行次数:0运行复制import java.sql.{Connection, DriverManager, PreparedStatement, ResultSet}import org.apache.flink.configuration.Configurationimport org.apache.flink.streaming.api.functions.source.{RichSourceFunction, SourceFunction}import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}/* * @Author: Alice菌 * @Date: 2020/8/8 23:52 * @Description: 基于mysql的source操作 */object StreamFromMysqlSource { def main(args: Array[String]): Unit = { // 1、创建流处理执行环境 val senv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment import org.apache.flink.api.scala._ // 2、添加自定义的 mysql 数据源对象 val studentDataStream: DataStream[Student] = senv.addSource(new MysqlSource()) studentDataStream.print() senv.execute("StreamFromMysqlSource") } // 3、创建mysql自定义数据源对象 class MysqlSource extends RichSourceFunction[Student](){ // 3.1 声明Connection对象 var connection:Connection = _ // 3.2 声明PreparedStatement对象 var ps: PreparedStatement = _ // 在 open 方法中进行配置链接信息 drive url username password // 加载驱动 Class.forName(),DriveManager 获取链接,调用prepareStatement,预编译执行sql override def open(parameters: Configuration): Unit = { val driver: String = "com.mysql.jdbc.Driver" val url: String = "jdbc:mysql://localhost:3306/blogs" val username: String = "root" val password: String = "root" Class.forName(driver) connection = DriverManager.getConnection(url,username,password) val sql: String = """ |select nid,ntitle,content from notice """.stripMargin ps = connection.prepareStatement(sql) } // 在run方法中进行查询,结果封装成样例类,ctx进行collect override def run(ctx: SourceFunction.SourceContext[Student]): Unit = { // 执行 SQL 查询 val queryResultSet: ResultSet = ps.executeQuery() while (queryResultSet.next()){ // 分别获取到查询的值 val nid: Int = queryResultSet.getInt("nid") val ntitle: String = queryResultSet.getString("ntitle") val content: String = queryResultSet.getString("content") // 将获取到的值,封装成样例类 val student: Student = Student(nid,ntitle,content) ctx.collect(student) } } override def close(): Unit = { if (connection != null){ connection.close() } if (ps != null){ ps.close() } } override def cancel(): Unit = { } } case class Student(nid: Int, ntitle: String, content: String) { override def toString: String = { "文章id:" + nid + " 标题:" + ntitle + " 内容:" + content } }}
看到这样的效果,说明我们的代码是OK的。
1.3 数据输出 Data Sinks介绍完了常用的数据输入DataSources,我们接下里来讲Flink流处理常用的数据输出 DataSinks。
大致分为以下几类
将数据sink到本地文件sink到本地集合sink到hdfssink到kafkasink到MySQL前三种我们可以参考批处理,方式都是一样的(传送门:Flink批处理的DataSources和DataSinks),这里我们就介绍第四、五种,如何 sink 到 kafak 和 mysql 。
1.3.1 sink 到 kafka参考代码代码语言:javascript代码运行次数:0运行复制import java.util.Propertiesimport org.apache.flink.api.common.serialization.SimpleStringSchemaimport org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer011/* * @Author: Alice菌 * @Date: 2020/8/10 10:08 * @Description: sink 到 kafka */object StreamKafkaSink { def main(args: Array[String]): Unit = { val senv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment // 导入隐式转换 import org.apache.flink.api.scala._ val source: DataStream[String] = senv.fromElements("1,小丽,北京,女") val properties: Properties = new Properties() properties.setProperty("bootstrap.servers","node01:9092") val flinkKafkaProducer: FlinkKafkaProducer011[String] = new FlinkKafkaProducer011[String]("test",new SimpleStringSchema(),properties) source.addSink(flinkKafkaProducer) // 打印 source.print() // 执行 senv.execute("StreamKafkaSink") }}在运行程序前,我们通过以下命令,开启 kafka 的消费者,进行消费数据
代码语言:javascript代码运行次数:0运行复制cd /export/servers/kafka_2.11-1.0.0bin/kafka-console-consumer.sh --from-beginning --topic test --zookeeper node01:2181,node02:2181,node03:2181

我们可以发现,当前 test 主题下的内容,仍是我们之前手动生产的数据。当我们启动程序,通过使用flink往kafka的 test 分区下打入数据 ,再观察消费数据的变化。

可以发现多了一条我们在程序中指定的数据~说明我们的代码是ok的。
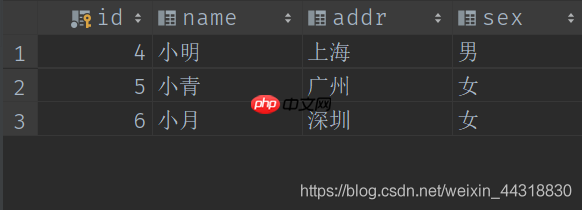
1.3.2 sink 到 mysql参考代码代码语言:javascript代码运行次数:0运行复制import java.sql.{Connection, DriverManager, PreparedStatement}import org.apache.flink.api.scala._import org.apache.flink.configuration.Configurationimport org.apache.flink.streaming.api.functions.sink.RichSinkFunctionimport org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}/* * @Author: Alice菌 * @Date: 2020/8/10 10:29 * @Description: */object StreamMysqlSink { // 定义一个样例类,用于封装数据 case class Student(id:Int,name:String,addr:String,sex:String) def main(args: Array[String]): Unit = { // 1、创建执行环境 val senv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment // 2、准备数据 val studentDStream: DataStream[Student] = senv.fromElements( Student(4, "小明", "上海", "男"), Student(5, "小青", "广州", "女"), Student(6, "小月", "深圳", "女") ) studentDStream.addSink(new StudentSlinkToMySql) senv.execute("StreamMysqlSink") } class StudentSlinkToMySql extends RichSinkFunction[Student]{ private var connection:Connection = _ private var ps:PreparedStatement = _ override def open(parameters: Configuration): Unit = { // 设置驱动,连接地址,用户名,密码 var driver: String = "com.mysql.jdbc.Driver" var url:String = "jdbc:mysql://localhost:3306/blogs?characterEncoding=utf-8&useSSL=false" var username: String = "root" var password: String = "root" // 1、加载驱动 Class.forName(driver) // 2、创建连接 connection = DriverManager.getConnection(url,username,password) // 书写SQL语句 val sql: String = "insert into student(id,name,addr,sex) values(?,?,?,?);" // 3、获得执行语句 ps = connection.prepareStatement(sql) } // 关闭连接操作 override def close(): Unit = { if (connection != null){ connection.close() } if (ps != null){ ps.close() } } // 每个元素的插入,都要触发一次 invoke,这里主要进行 invoke 插入 override def invoke(stu: Student): Unit = { try{ // 4、组装数据,执行插入操作 ps.setInt(1,stu.id) ps.setString(2,stu.name) ps.setString(3,stu.addr) ps.setString(4,stu.sex) ps.executeUpdate() } catch { case e:Exception => println(e.getMessage) } } }}在程序运行前,student表中还没有数据

运行程序后,可以观察到指定的数据被添加到了MySQL指定的数据库下的数据表里。
本篇博客,博主为大家介绍了Flink在流处理过程中,常用的数据输入和输出的几种方式,这块的知识非常基础,也同样非常重要,初学Flink的朋友们可要勤加练习咯~
如果以上过程中出现了任何的纰漏错误,烦请大佬们指正?
受益的朋友或对大数据技术感兴趣的伙伴记得点赞关注支持一波?
希望我们都能在学习的道路上越走越远?
以上就是快速入门Flink (7) —— 小白都喜欢看的Flink流处理之DataSources和DataSinks的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 983
983

























